工具
pytorch
内存相关
原地操作
运行一些操作可能会导致为新结果分配内存。 例如,如果我们用Y=X+Y,我们将取消引用Y指向的张量,而是指向新分配的内存处的张量。
before = id(Y)
Y = Y + X
id(Y) == beforeFalse首先,我们不想总是不必要地分配内存。在机器学习中,我们可能有数百兆的参数,并且在一秒内多次更新所有参数。 通常情况下,我们希望原地执行这些更新。 其次,如果我们不原地更新,其他引用仍然会指向旧的内存位置, 这样我们的某些代码可能会无意中引用旧的参数。
幸运的是,执行原地操作非常简单。 我们可以使用切片表示法将操作的结果分配给先前分配的数组,例如Y[:] = <expression>。 为了说明这一点,我们首先创建一个新的矩阵Z,其形状与另一个Y相同, 使用zeros_like来分配一个全0的块。
Z = torch.zeros_like(Y)
print('id(Z):', id(Z))
Z[:] = X + Y
print('id(Z):', id(Z))输出:
id(Z): 139931132035296
id(Z): 139931132035296如果在后续计算中没有重复使用X, 我们也可以使用X[:] = X + Y或X += Y来减少操作的内存开销
before = id(X)
X += Y
id(X) == before输出:
True
EarlyStopping
# 定义 EarlyStopping Callback
class EarlyStopping:
def __init__(self, patience=10, delta=0):
self.patience = patience
self.delta = delta
self.best_score = None
self.counter = 0
self.early_stop = False
def __call__(self, val_loss):
score = -val_loss
if self.best_score is None:
self.best_score = score
elif score < self.best_score + self.delta:
self.counter += 1
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_score = score
self.counter = 0linux 服务器守护线程——tmux
$HOME : echo $HOME = ‘/data/kangbaobin’【是Linux中的一个环境变量,表示用户初次登陆时的起始目录名】
Xshell断开连接后仍保持服务器程序执行
先安装tmux:
root用户安装仅需一行
sudo apt-get install tmux非root用户
1、下载与解压
wget -c https://github.com/tmux/tmux/releases/download/3.0a/tmux-3.0a.tar.gz
wget -c https://github.com/libevent/libevent/releases/download/release-2.1.11-stable/libevent-2.1.11-stable.tar.gz
wget -c https://ftp.gnu.org/gnu/ncurses/ncurses-6.2.tar.gz解压指令如下:
tar -xzvf tmux-3.0a.tar.gz
tar -xzvf libevent-2.1.11-stable.tar.gz
tar -xzvf ncurses-6.2.tar.gz2、安装
libevent会安在 /data/kangbaobin/tmux/tmux_depend / lib
cd libevent-2.1.11-stable
# $HOME/data/kangbaobin/tmux/tmux_depend 是我的安装路径,大家可以修改
./configure --prefix=$HOME/data/kangbaobin/tmux/tmux_depend --disable-shared
make && make installncurses会安在 /data/kangbaobin/tmux/tmux_depend / include
cd ncurses-6.2
./configure --prefix=$HOME/data/kangbaobin/tmux/tmux_depend
make && make install安装tmux
cd tmux-3.0a
./configure CFLAGS="-I$HOME/data/kangbaobin/tmux/tmux_depend/include -I/$HOME/data/kangbaobin/tmux/tmux_depend/include/ncurses" LDFLAGS="-L/$HOME/data/kangbaobin/tmux/tmux_depend/lib -L/$HOME/data/kangbaobin/tmux/tmux_depend/include/ncurses -L/$HOME/data/kangbaobin/tmux/tmux_depend/include"
make
cp tmux $HOME/data/kangbaobin/tmux/tmux_depend/bin3、设置环境变量(此步骤建议手动添加到bashrc文件中)
export PATH=$HOME/data/kangbaobin/tmux/tmux_depend/bin:$PATH
source ~/.bashrctmux常用命令
1)新建会话,比如新创建一个会话以"ccc"命名
[root@Centos6 ~]# tmux new -s ccc
加上参数-d,表示在后台新建会话
root@bobo:~# tmux new -s shibo -d
root@bobo:~# tmux ls
shibo: 1 windows (created Tue Oct 2 19:22:32 2018) [135x35]
2)查看创建得所有会话
[root@Centos6 ~]# tmux ls
0: 1 windows (created Wed Aug 30 17:58:20 2017) [112x22](attached) #这里的attached表示该会话是当前会话
aaa: 2 windows (created Wed Aug 30 16:54:33 2017) [112x22]
ccc: 1 windows (created Wed Aug 30 17:01:05 2017) [112x22]
3)登录一个已知会话。即从终端环境进入会话。
第一个参数a也可以写成attach。后面的aaa是会话名称。
[root@Centos6 ~]# tmux a -t aaa
4)退出会话不是关闭:
登到某一个会话后,先按键ctrl+b启动快捷键,再按d,这样就会退出该会话,但不会关闭会话。
如果直接ctrl + d,就会在退出会话的通话也关闭了该会话!
5)关闭会话(销毁会话)
[root@Centos6 ~]# tmux ls
aaa: 2 windows (created Wed Aug 30 16:54:33 2017) [112x22]
bbb: 1 windows (created Wed Aug 30 19:02:09 2017) [112x22]
[root@Centos6 ~]# tmux kill-session -t bbb
[root@Centos6 ~]# tmux ls
aaa: 2 windows (created Wed Aug 30 16:54:33 2017) [112x22]
6)重命名会话
[root@Centos6 ~]# tmux ls
wangshibo: 1 windows (created Sun Sep 30 10:17:00 2018) [136x29] (attached)
[root@Centos6 ~]# tmux rename -t wangshibo kevin
[root@Centos6 ~]# tmux ls
kevin: 1 windows (created Sun Sep 30 10:17:00 2018) [136x29] (attached)Python
计时器
class Timer:
"""记录多次运行时间"""
def __init__(self):
self.times = []
self.start()
def start(self):
"""启动计时器"""
self.tik = time.time()
def stop(self):
"""停止计时器并将时间记录在列表中"""
self.times.append(time.time() - self.tik)
return self.times[-1]
def avg(self):
"""返回平均时间"""
return sum(self.times) / len(self.times)
def sum(self):
"""返回时间总和"""
return sum(self.times)
def cumsum(self):
"""返回累计时间"""
return np.array(self.times).cumsum().tolist()lambda函数
- lambda函数是一种匿名函数,即没有名字的函数
- 使用lambda保留字定义,函数名是返回结果
- lambda函数的函数体只是一个表达式
- lambda函数用于定义简单的、能够在一行内表示的函数
- lambda表达式” : “后面,只能有一个表达式,def则可以有多个。
- lambda一般用来定义简单的函数(单行函数),而def可以定义复杂的函数
g = lambda x:x*x+1
g(3)#10封装日志类
以下是一个比较复杂的 Python 封装日志类的示例代码,其中包含了很多不同的功能和选项:
import logging
import os
import sys
class CustomLogger:
def __init__(self, logger_name, log_level=logging.DEBUG, log_dir=None, log_filename=None, console_log=True, file_log=True):
# create logger
self.logger = logging.getLogger(logger_name)
self.logger.setLevel(log_level)
# set log format
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# add console handler
if console_log:
ch = logging.StreamHandler(sys.stdout)
ch.setFormatter(formatter)
self.logger.addHandler(ch)
# add file handler
if file_log:
if not log_dir:
log_dir = os.getcwd()
if not log_filename:
log_filename = logger_name + '.log'
log_file_path = os.path.join(log_dir, log_filename)
fh = logging.FileHandler(log_file_path)
fh.setFormatter(formatter)
self.logger.addHandler(fh)
def debug(self, message):
self.logger.debug(message)
def info(self, message):
self.logger.info(message)
def warning(self, message):
self.logger.warning(message)
def error(self, message):
self.logger.error(message)
def critical(self, message):
self.logger.critical(message)在上面的代码中,CustomLogger 类接受以下参数:
logger_name:指定 logger 的名称。log_level:指定 logger 的日志级别,默认为logging.DEBUG。log_dir:指定日志文件存储的目录,默认为当前工作目录。log_filename:指定日志文件的文件名,默认为 logger 的名称加上.log后缀。console_log:如果为 True,将会向控制台输出日志。file_log:如果为 True,将会将日志写入文件。
CustomLogger 类在初始化时会创建 logger 对象,并设置日志级别。然后,它会根据给定的参数决定是否添加控制台处理器和文件处理器。控制台处理器将日志输出到标准输出流,文件处理器将日志写入指定的文件。如果没有指定日志文件的存储目录和文件名,则会使用当前工作目录和 logger 名称加上 .log 后缀。
CustomLogger 类还定义了一些方法,包括 debug()、info()、warning()、error() 和 critical(),这些方法分别对应不同的日志级别,并将日志消息传递给 logger 对象进行处理。
使用该类时,您可以像下面这样实例化:
logger = CustomLogger(logger_name='my_logger', log_level=logging.INFO, log_dir='/path/to/logs', log_filename='my_app.log', console_log=True, file_log=True)
logger.info('Hello, world!')
这将创建一个名为 my_logger 的 logger 对象,日志级别为 logging.INFO,日志文件存储在 /path/to/logs/my_app.log,同时向控制台输出日志。然后,它将记录一条日志消息:“Hello, world
jupyter
如何在jupyter中可视化训练效果?
某些情况不方便弹窗把 env 界面实时渲染出来,所以我们通过下面两种方法环境的可视化,从而看到智能体的交互情况。
方法一:直接在jupyter中渲染
import gym
from IPython import display
import matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
# Set up fake display; otherwise rendering will fail
import os
os.system("Xvfb :1 -screen 0 1024x768x24 &")
os.environ['DISPLAY'] = ':1'
env = gym.make('CartPole-v1')
env.seed(23)
env.reset()
img = plt.imshow(env.render(mode='rgb_array')) # only call this once
for _ in range(100):
img.set_data(env.render(mode='rgb_array')) # just update the data
display.display(plt.gcf())
display.clear_output(wait=True)
action = env.action_space.sample()
env.step(action)方法二:对环境进行录制,再播放视频
由于工具函数太长了,具体见github中的代码
下面录制视频和播放视频:
# 录制视频
record_video('CartPole-v1', model, video_length=500, prefix='ppo2-cartpole')
# 展示视频
show_videos('videos', prefix='ppo2')网络结构
网络输出离散动作概率的时候,一般加一层
softmax层,保证输出的离散动作概率和为1;输出连续动作概率的时候,一般加一层tanh层,因为tanh范围是[-1,1],我们可以根据实际需要,将输出进行缩放。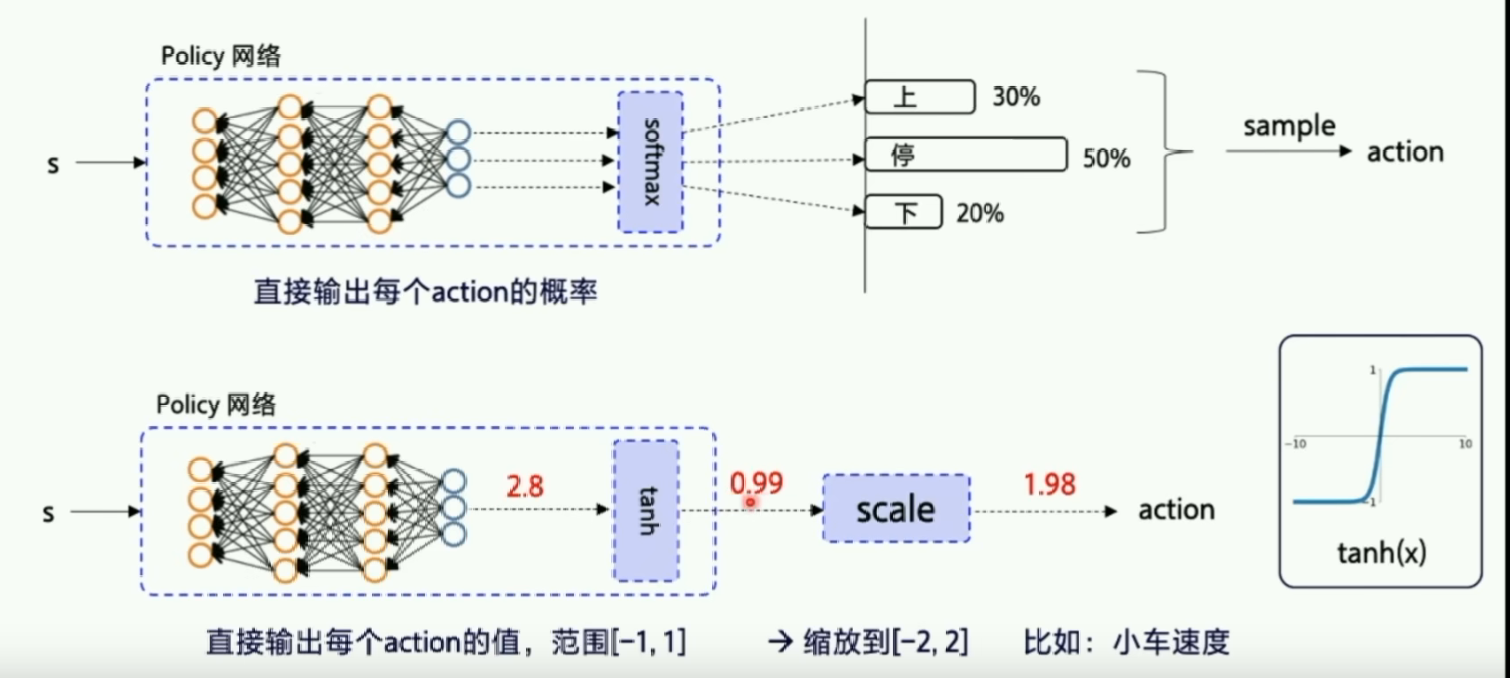
好玩的东西
print 函数 \r转义字符
NOTE:
\r后的字符串替换前面输出的字符串.
eg.print(“hello\rwork”)输出为work
下面的代码的功能是在训练中进度条式的显示输出结果,而不是一大长串字符输出。
import numpy as np
import time
for t in range(5):
for i in range(100):
print("\rStep {} Episode {},{} loss=({})".format(
t, i + 1, 100, np.random.randn()), end="")
time.sleep(0.1)输出:
Step 0 Episode 65,100 loss=(-2.30202248835621)最后结果

其他效果,具体参考看这里跳转
(1)转圈效果
from time import sleep
list = ['|','/','—','\\'] #创建转圈效果的所有样式,'\\'是'\'本身
while 1:
for i in list:
print('\r正在加载中 %s '%i,end='')
sleep(0.05) #间隔0.05秒
(2)动态表情
from time import sleep
list1 = ['(づ。◕ᴗᴗ◕。)づ','(づ。—ᴗᴗ—。)づ','(づ。◕ᴗᴗ◕。)づ','(づ。—ᴗᴗ—。)づ','(づ。◕ᴗᴗ◕。)づ',
'(づ。◕ᴗᴗ◕。)づ','(づ。◕ᴗᴗ◕。)づ','(づ。◕ᴗᴗ◕。)づ','(づ。◕ᴗᴗ◕。)づ','(づ。◕ᴗᴗ◕。)づ']
#第一个动态表情图的所有样式
list2 = ['u~(@_@)~*','u~(@_@)~*','u~(@_@)~*','u~(@_@)~*','u~(@_@)~*',
'u~(@_@)~*','u~(—_—)~*','u~(@_@)~*','u~(—_—)~*','u~(@_@)~*']
#第二个动态表情图的所有样式
while 1:
for a,b in zip(list1,list2):
print('\r %s %s '%(a,b),end='')
sleep(0.15)
(3)进度条
from time import sleep
while 1:
for i in range(51):
print('\r加载进度: [%-50s]%.2f%% '%('#'*i,i*2),end='')
sleep(0.05)
我们还可以为它加上颜色:
from time import sleep
while 1:
for i in range(51):
print('\r加载进度: [\033[32m%-50s\033[0m]\033[32m%.2f%%\033[0m '%('#'*i,i*2),end='')
sleep(0.05)
计算机视觉
图像裁剪
在计算机视觉中,通常将输入图像的大小调整为固定大小以便于模型处理。对于resnet34模型,它的输入尺寸是224x224。因此,我们需要对输入图像进行预处理,将其调整为224x224。但是,在将图像调整为目标大小之前,通常需要进行一些预处理操作来确保输入图像具有相同的特征。
在上面的示例中,首先将图像大小调整为256x256。这是因为图像通常具有不同的大小和宽高比,我们需要将其调整为统一的大小以确保输入图像具有相同的特征。然后,对调整后的图像进行中心裁剪为224x224,以确保图像的关键特征位于中心位置,这有助于提高模型的准确性。最后,将图像转换为张量并进行归一化,以便于模型进行处理。

