Instruction
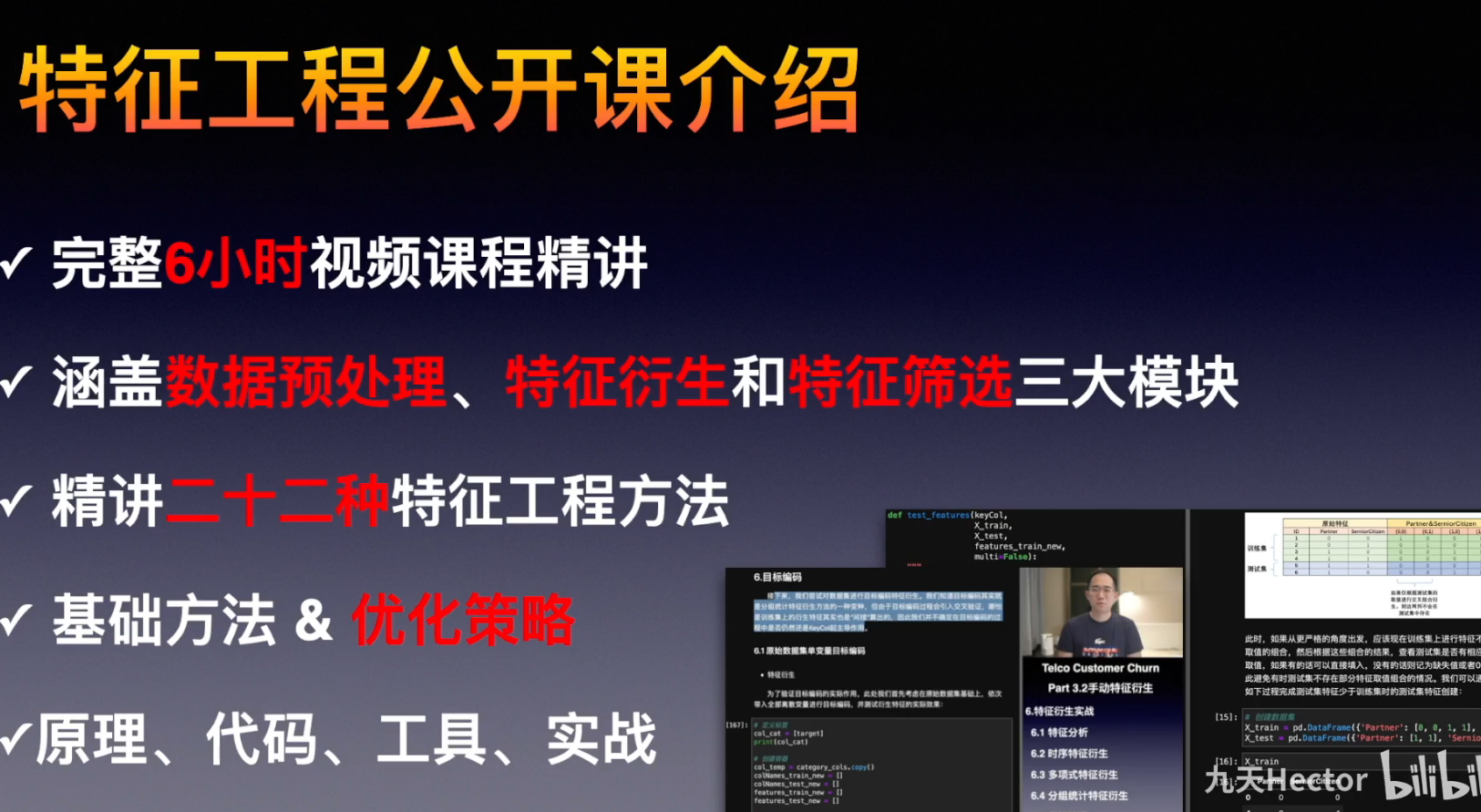
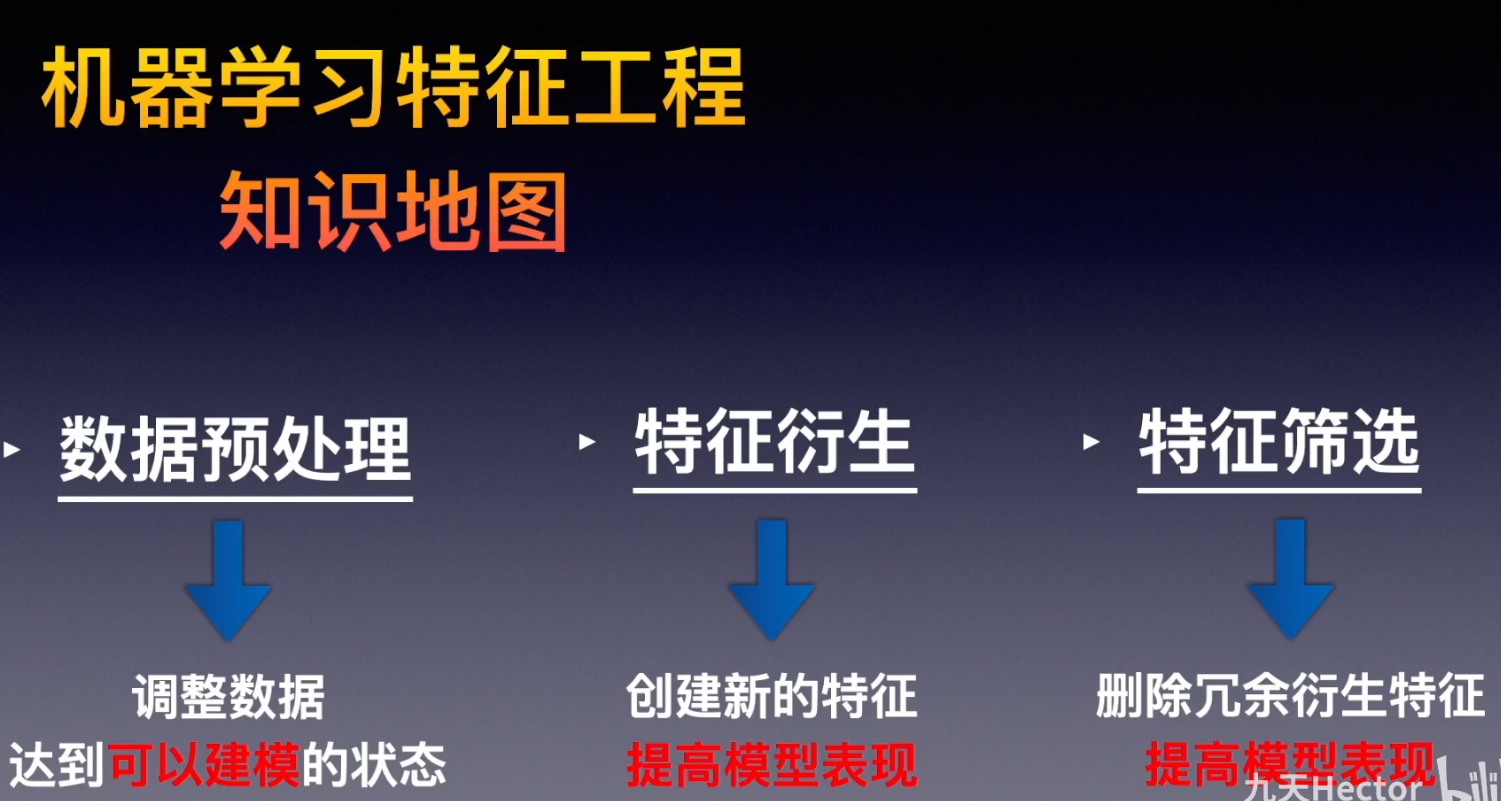
课程名称:特征工程实战方法精讲|Kaggle上分必备特征工程技巧|数据清洗|特征衍生|特征筛选
课程链接:跳转



pandas怎么处理特征中异常值
在处理异常值时,我们需要先了解数据的分布情况,以及异常值的产生原因,然后根据具体情况采取相应的处理方法。下面介绍一些常用的异常值处理方法:
- 剔除异常值:如果异常值是由于数据采集或处理错误引起的,可以考虑直接剔除异常值。例如,可以删除特别大或特别小的数据点,或者删除超出3个标准差的数据点。需要注意的是,剔除异常值可能会导致数据样本减少,从而影响建模结果。
- 修正异常值:如果异常值是由于数据采集或处理错误引起的,但是不能直接剔除,可以考虑对异常值进行修正。例如,可以将特别大或特别小的数据点修正为平均值或中位数,或者使用插值法进行修正。
- 分箱处理:如果异常值是由于数据分布不均匀引起的,可以将特征进行分箱处理。例如,可以将数值型特征按照分位数进行分箱,或者将分类特征进行合并。
- 离群值处理:如果异常值是由于样本本身的特殊性引起的,可以考虑将异常值作为一个新的特征进行处理。例如,可以将特别大或特别小的数据点作为一个新的二元特征,并将其设置为1或0。
在Pandas中,可以使用describe()方法查看特征的基本统计信息,例如均值、标准差、最大值、最小值、中位数等。另外,可以使用boxplot()方法绘制特征的箱线图,以帮助识别异常值。
下面是一个示例代码,演示如何使用Pandas处理特征中的异常值:
import pandas as pd
import numpy as np
# 创建一个包含异常值的DataFrame
df = pd.DataFrame({'A': [1, 2, 3, 4, 5, 1000], 'B': [4, 5, 6, 7, 8, -1000]})
# 查看DataFrame的基本统计信息
print(df.describe())
# 绘制DataFrame的箱线图
df.boxplot()
# 将超出3个标准差的数据点替换为NaN
df[np.abs(df - df.mean()) > 3 * df.std()] = np.nan
# 输出处理后的DataFrame
print(df)
输出结果如下:
A B
count 6.000000 6.000000
mean 168.333333 -150.500000
std 417.179679 642.418291
min 1.000000 -1000.000000
25% 2.250000 4.250000
50% 3.500000 6.500000
75% 4.750000 7.750000
max 1000.

