机器学习
简单线性回归
题目1


代码:
import pandas
import numpy as np
import matplotlib.pyplot as plt
# load dataset
df = pandas.read_csv('temperature_dataset.csv')
data = np.array(df)
# config
lr = 0.0001
epoch = 1000
total_size = len(data)
train_size = 3000
test_size = total_size - train_size
# dataset
train_set = data[0:3000,1:5]
train_target = data[0:3000,0]
test_set = data[3000:total_size,1:5]
test_target = data[3000:total_size,0]
#train
# w,y,y_hat 为列向量,
w = np.zeros(4).reshape((-1,1))
b = 0
train_loss = []
for _ in range(epoch):
y_hat = np.dot(train_set,w) + b
y = train_target.reshape((-1,1))
b = b - 2*lr*((y_hat - y).sum().item(0))/train_size
w = w - 2*lr*np.dot(train_set.T,(y_hat-y))/train_size
train_loss.append((np.abs(y_hat - y)).sum().item(0)/train_size)
# loss曲线
plt.plot(train_loss)
#rmse
e = (np.dot(train_set,w)+b-train_target.reshape((-1,1)))# y_hat - y
train_rmse = np.sqrt(np.dot(e.T,e)/train_size)
'''
加上特征缩放
'''
w = np.zeros(4).reshape((-1,1))
b = 0
lr = 0.1 #必须要调整学习率
# min-max特征缩放
x_max = train_set.max()
x_min = train_set.min()
train_set = (train_set - x_min) /(x_max - x_min)
train_loss = []
for _ in range(epoch):
y_hat = np.dot(train_set,w) + b
y = train_target.reshape((-1,1))
# print((y_hat - y).sum())
b = b - 2*lr*((y_hat - y).sum().item(0))/train_size
w = w - 2*lr*np.dot(train_set.T,(y_hat-y))/train_size
train_loss.append((np.abs(y_hat - y)).sum().item(0)/train_size)
#rmse
e = (np.dot(train_set,w)+b-train_target.reshape((-1,1)))# y_hat - y
train_rmse = np.sqrt(np.dot(e.T,e)/train_size)
题目2

import numpy as np
import matplotlib.pyplot as plt
# parameters
dataset = 1 # index of training dataset
# datasets for training
if dataset == 1: # balanced dataset
x_train = np.array([50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70]).reshape((1, -1))
y_train = np.array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]).reshape((1, -1))
elif dataset == 2: # unbalanced dataset 1
x_train = np.array([0, 5, 10, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70]).reshape((1, -1))
y_train = np.array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]).reshape((1, -1))
elif dataset == 3: # unbalanced dataset 2
x_train = np.array([0, 5, 10, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73]).reshape((1, -1))
y_train = np.array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]).reshape((1, -1))
m_train = x_train.size # number of training examples
epoch = 200000
lr = 0.002
x = x_train.T
y = y_train.T
# train
w = 0
b = 0
def sigmoid(x):
return 1/(1+np.exp(-x))
train_loss = []
for _ in range(epoch):
y_hat = sigmoid(w*x + b)
b = b - 2*lr*(y_hat*(1-y_hat)*(y_hat-y)).sum()/m_train
w = w - 2*lr*np.dot(x.T,y_hat*(1-y_hat)*(y_hat-y))/m_train
train_loss.append(np.abs(y_hat - y).sum()/m_train)
逻辑回归
题目1

import pandas
import numpy as np
import matplotlib.pyplot as plt
# load dataset
df = pandas.read_csv('alcohol_dataset.csv')
data = np.array(df)
# shuffer
rng = np.random.default_rng(1)
data = rng.permutation(data)
# normal
# data = (data - np.amin(data))/(np.amax(data) - np.amin(data))
# data
m_train = 250
m_test = len(data) - m_train
train_data = data[0:m_train,0:5]
train_label = data[0:m_train,5]
test_data = data[m_train:,0:5]
test_label = data[m_train:,5]
#config
epoch = 200000
# train
w = np.random.randn(5).reshape((-1,1))
b = np.random.randn()
def sigmoid(x):
return 1 / (1 + np.exp(-x))
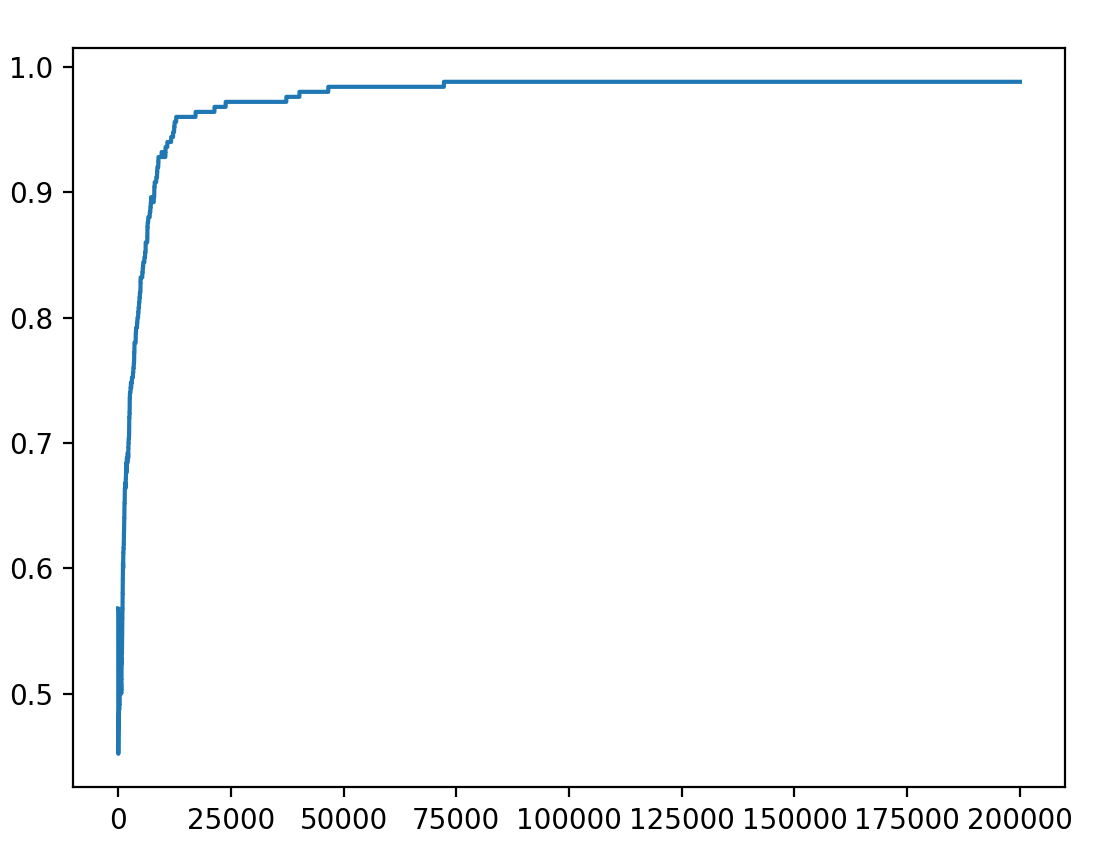
train_recall = []
train_accuracy = []
lr = 0.001
x = train_data
y = train_label.reshape((-1, 1))
for _ in range(epoch):
y_hat = sigmoid(np.dot(x, w) + b)
b = b - lr * (y_hat - y).sum() / m_train
w = w - lr * np.dot(x.T, y_hat - y) / m_train
y_hat = np.where(y_hat >= 0.5, 1, 0)
tp = np.logical_and(y_hat == 1, y == 1).sum()
fp = np.logical_and(y_hat == 1, y == 0).sum()
tn = np.logical_and(y_hat == 0, y == 0).sum()
fn = np.logical_and(y_hat == 0, y == 1).sum()
# print(tp)
# print(fp)
# print(tn)
# print(fn)
accuracy = (tp + tn) / (tp + tn + fp + fn) #准确率
train_accuracy.append(accuracy)
#训练集错误个数
y_hat = sigmoid(np.dot(x,w) + b)
y_hat = np.where(y_hat >= 0.5,1,0)
print(m_train - (y_hat == y).sum())
#测试集错误个数
x = test_data
y = test_label.reshape((-1,1))
y_hat = sigmoid(np.dot(x,w) + b)
y_hat = np.where(y_hat >= 0.5,1,0)
print(m_test - (y_hat == y).sum())
plt.plot(train_accuracy)
plt.show()