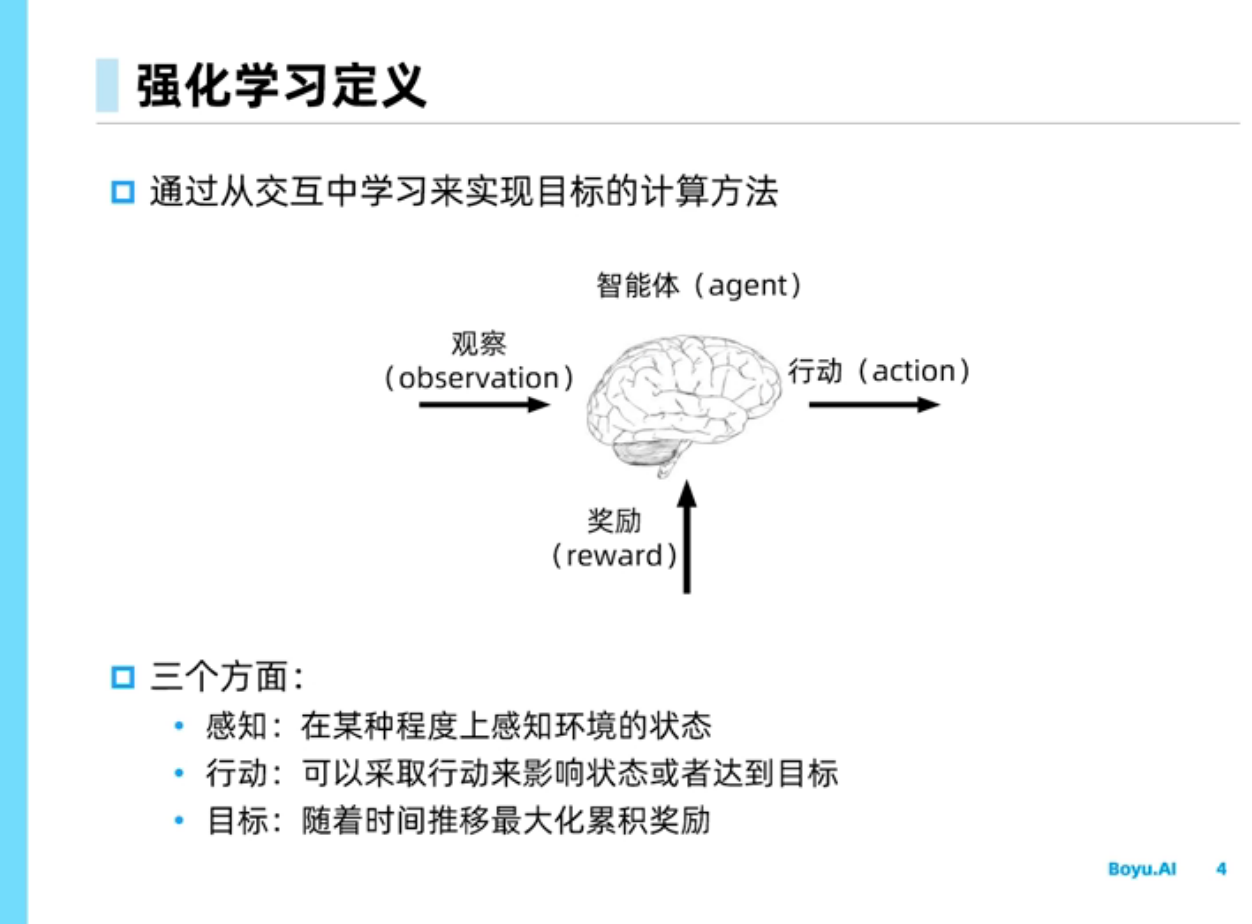
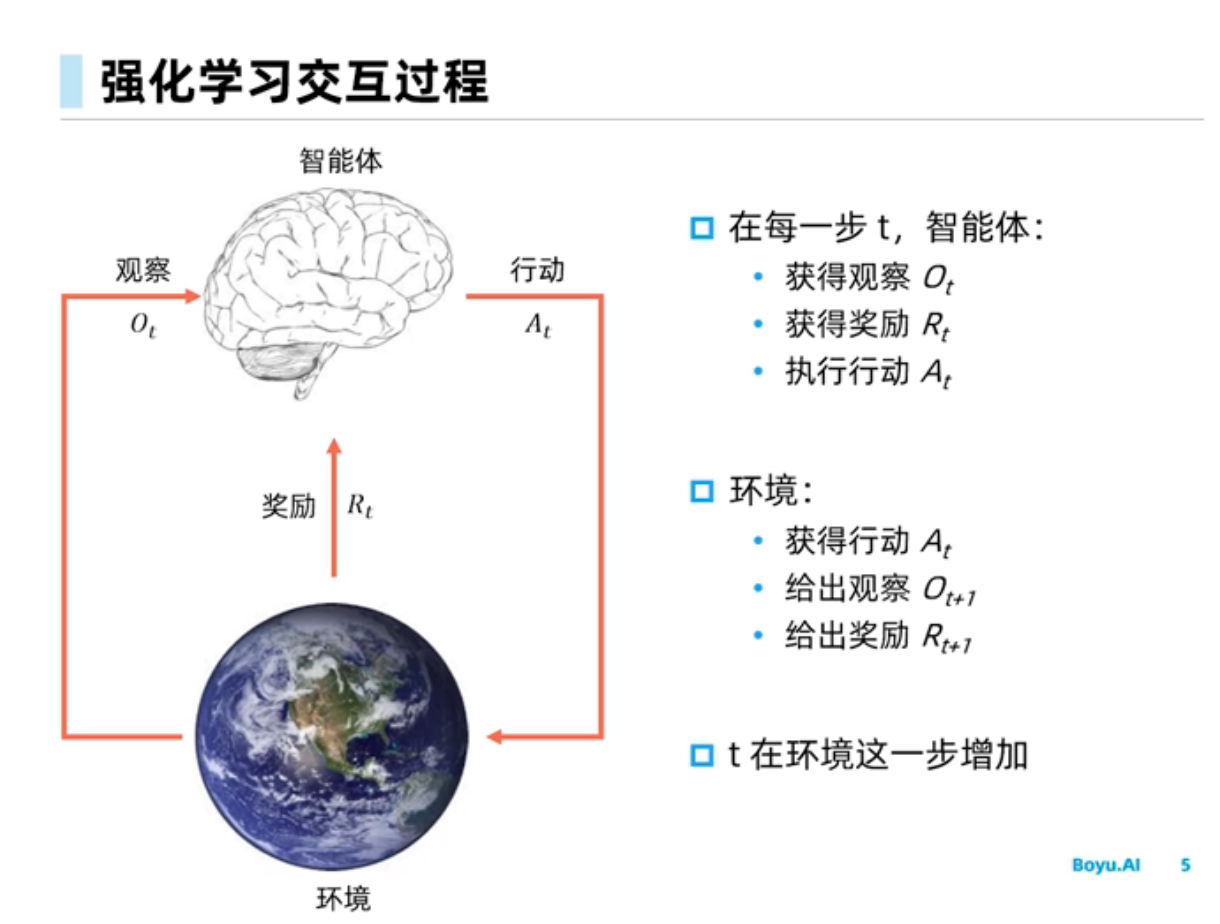
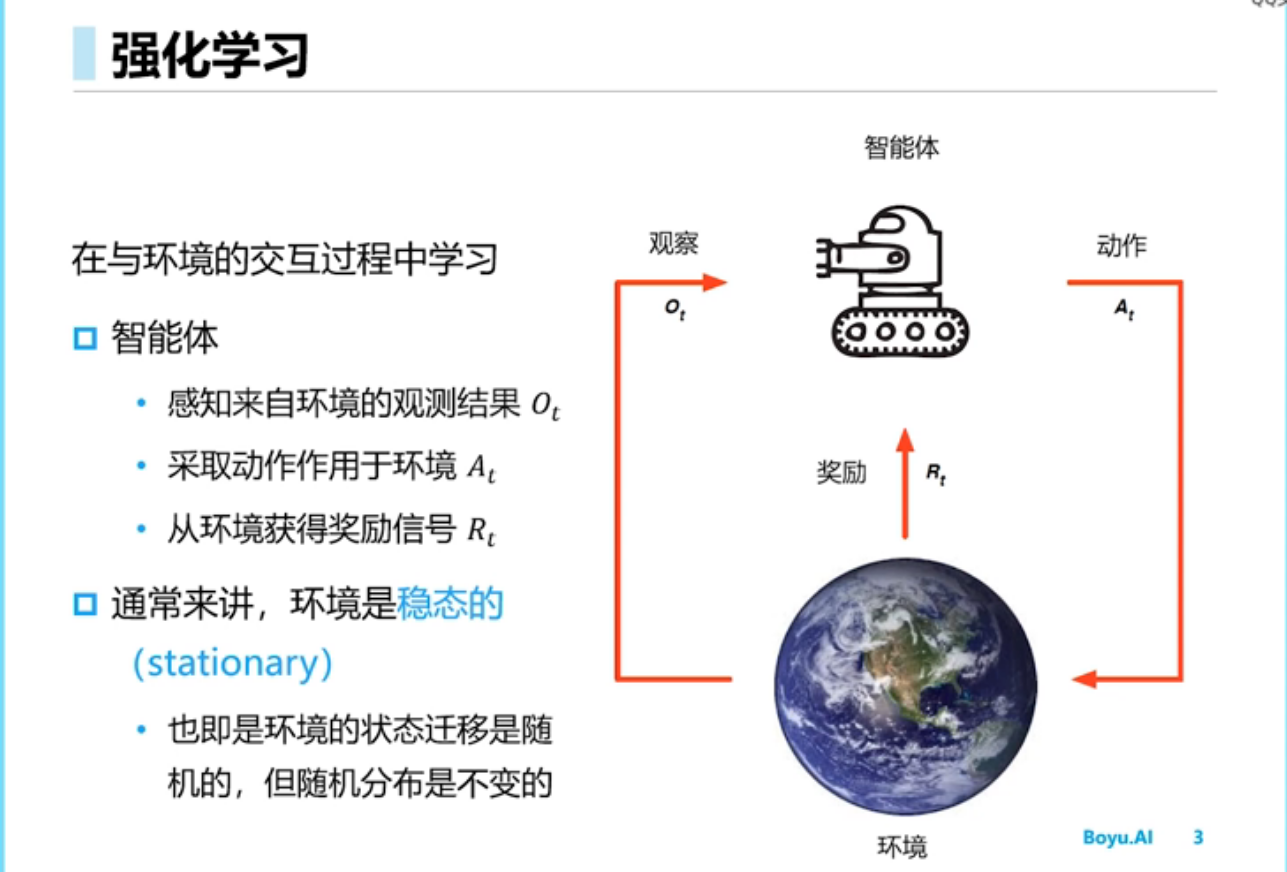
强化学习简介
强化学习里面一直以来就是value based和policy based两路方法,它们各有优劣。
Value based 方法强调让机器知道什么state或者state-action pair是好的,什么是坏的。例如Q-learning训练的优化目标是最小化一个TD error:
这个优化目标很清晰,就是让当前Q函数估计更准。但是这个优化目标并不对应任何策略的目标。
我们强化学习的总目标是给出一个policy,使之能在环境里面很好的完成序列决策任务。
Policy based 方法则正好直接朝着这么目标去优化策略的参数:
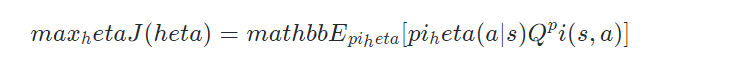
所以Berkeley和OpenAI的人(PPO和TRPO的作者)一般喜欢强调policy based 方法更加直接在优化最终的目标。
当然,我们也要知道value based 方法其实往往更方便学习,毕竟其优化目标就是一个TD error,相比policy based方法的目标要容易优化得多。
所以如果我们希望算法能尽快达到一个比较好的效果,可以直接用value based 方法。而如果有足够的时间和算力去训练,那么推荐使用 policy based 方法。


随机策略输出是条件概率分布


环境最重要得两个部分:状态转移概率,奖励函数
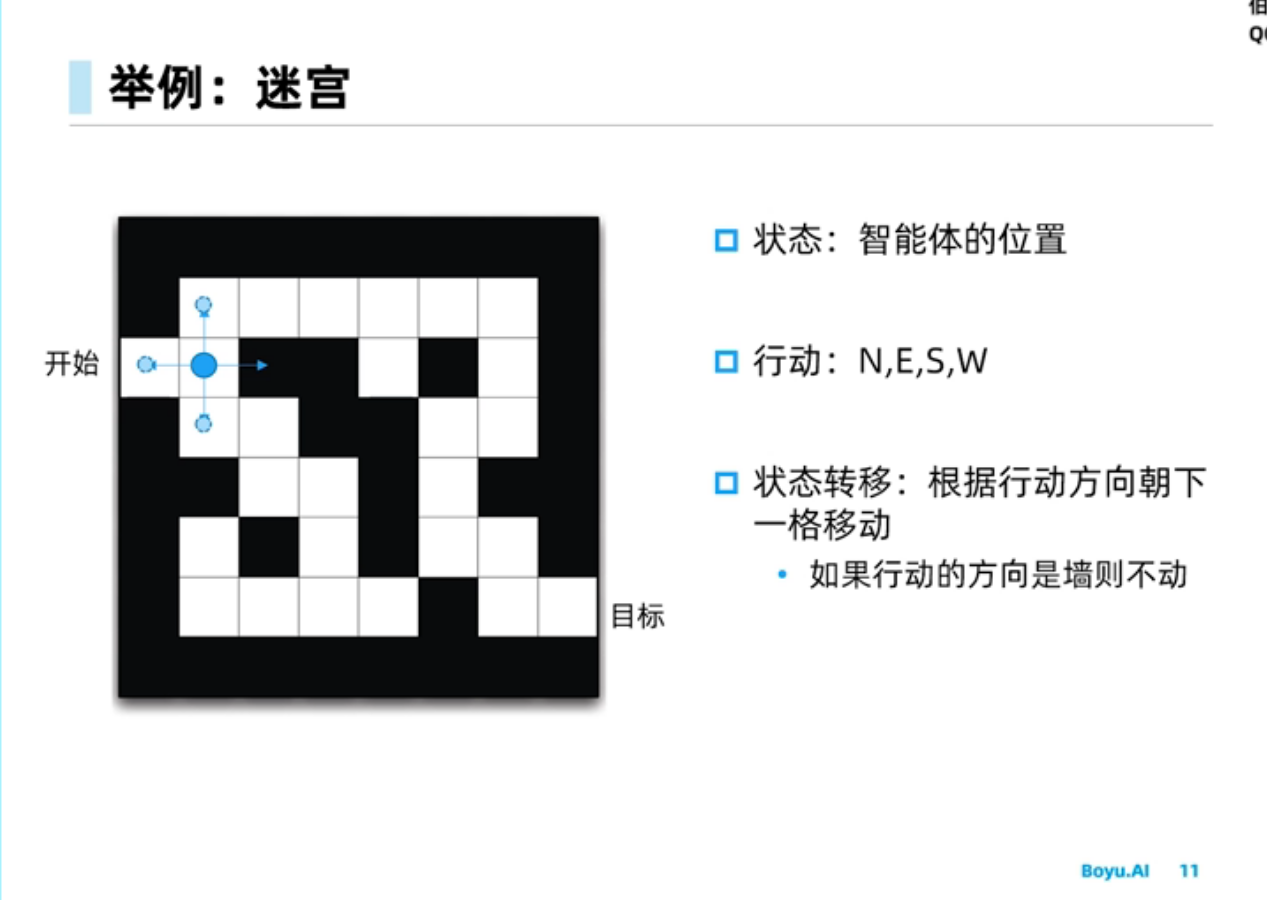
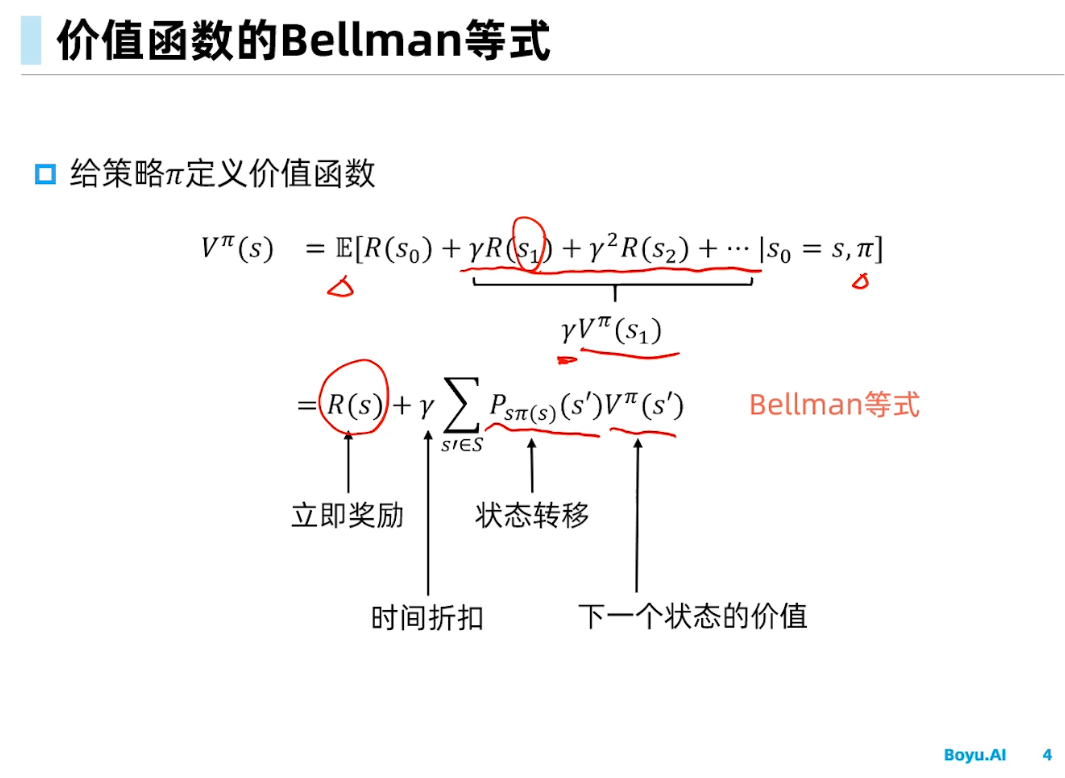
如下行走策略$\pi$
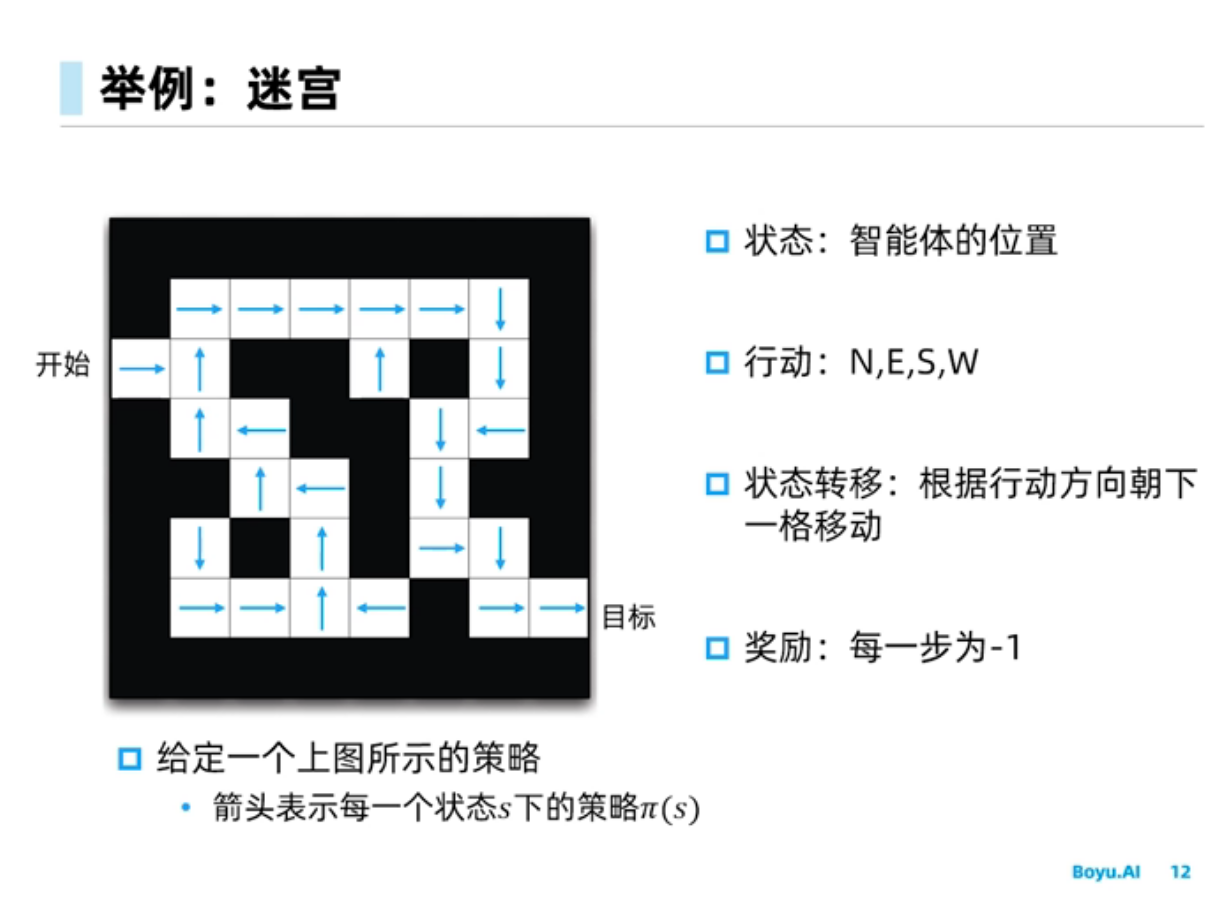
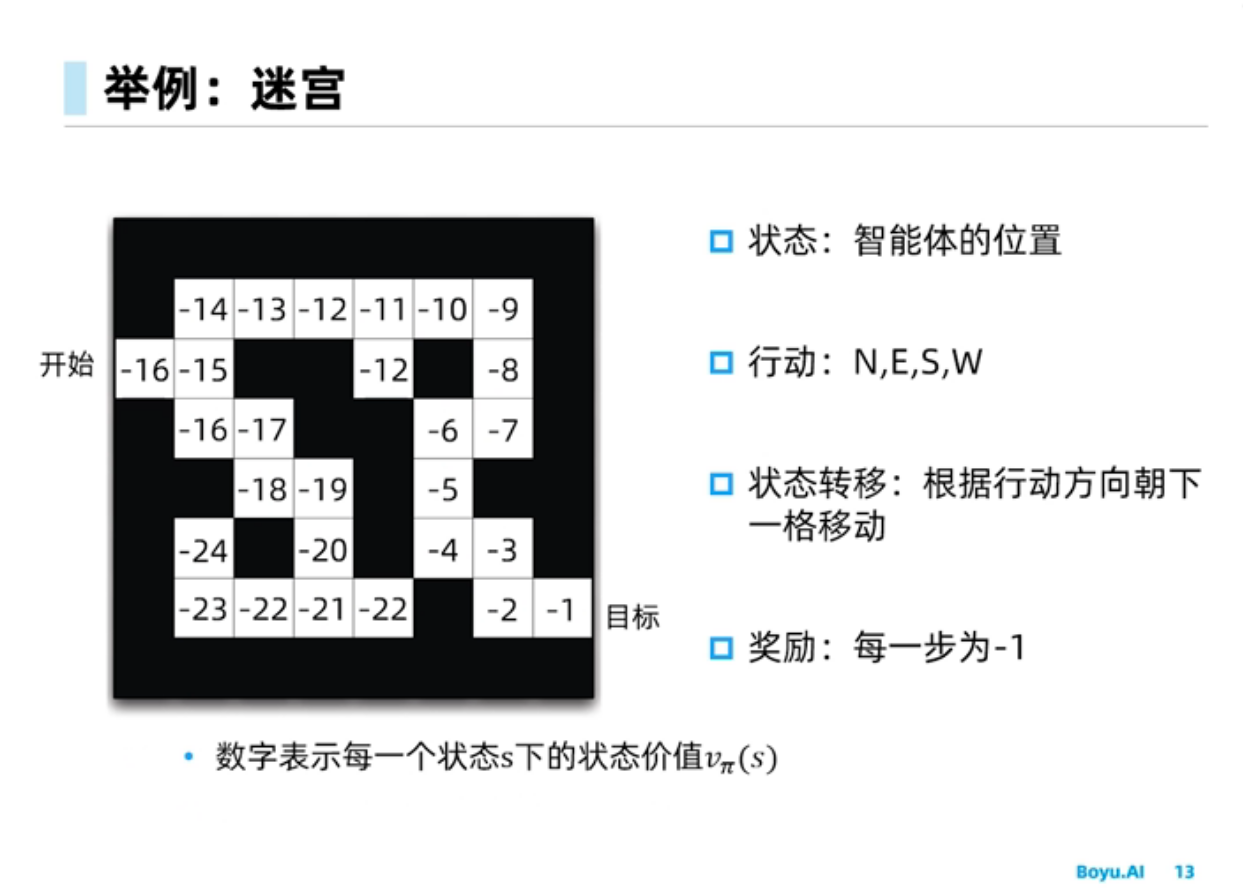
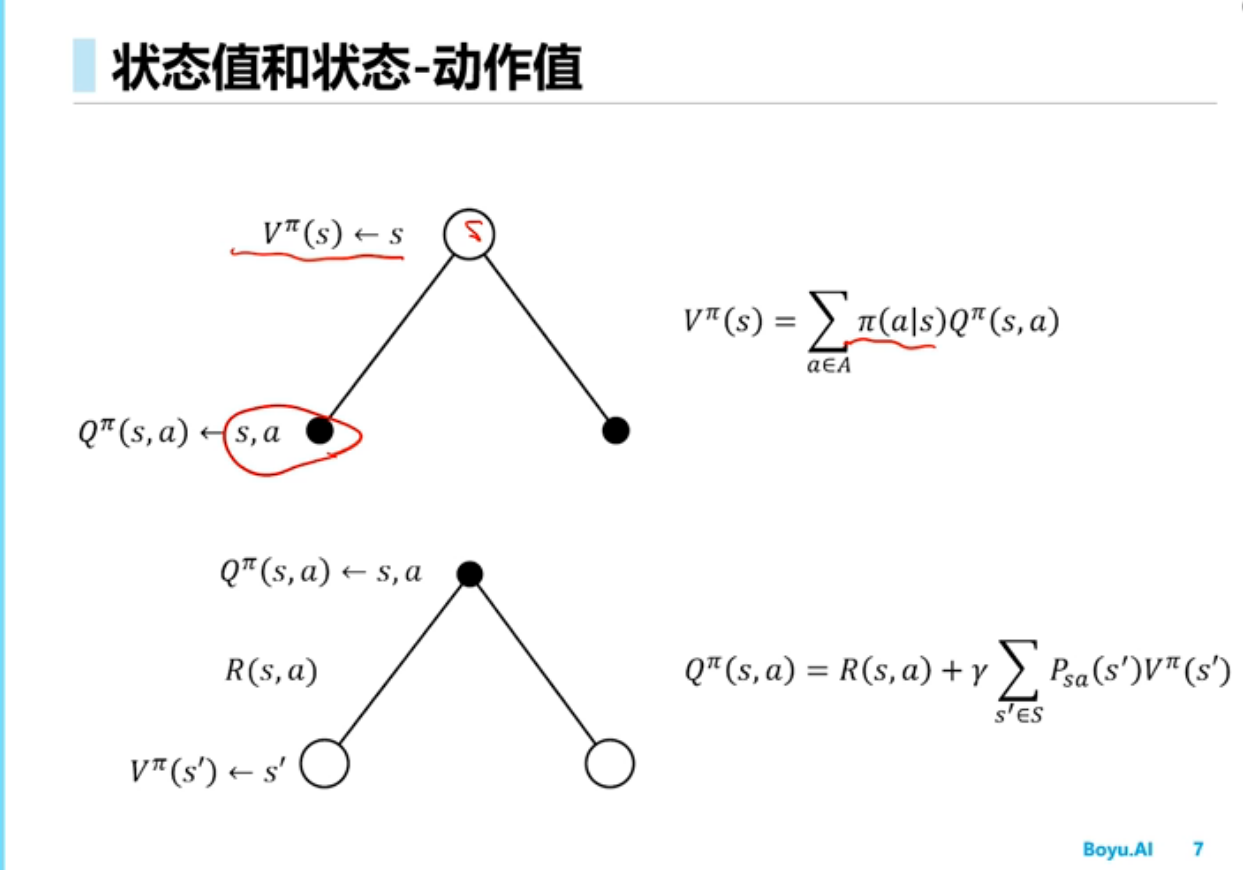
对于上面给出的$\pi$的状态价值函数如下
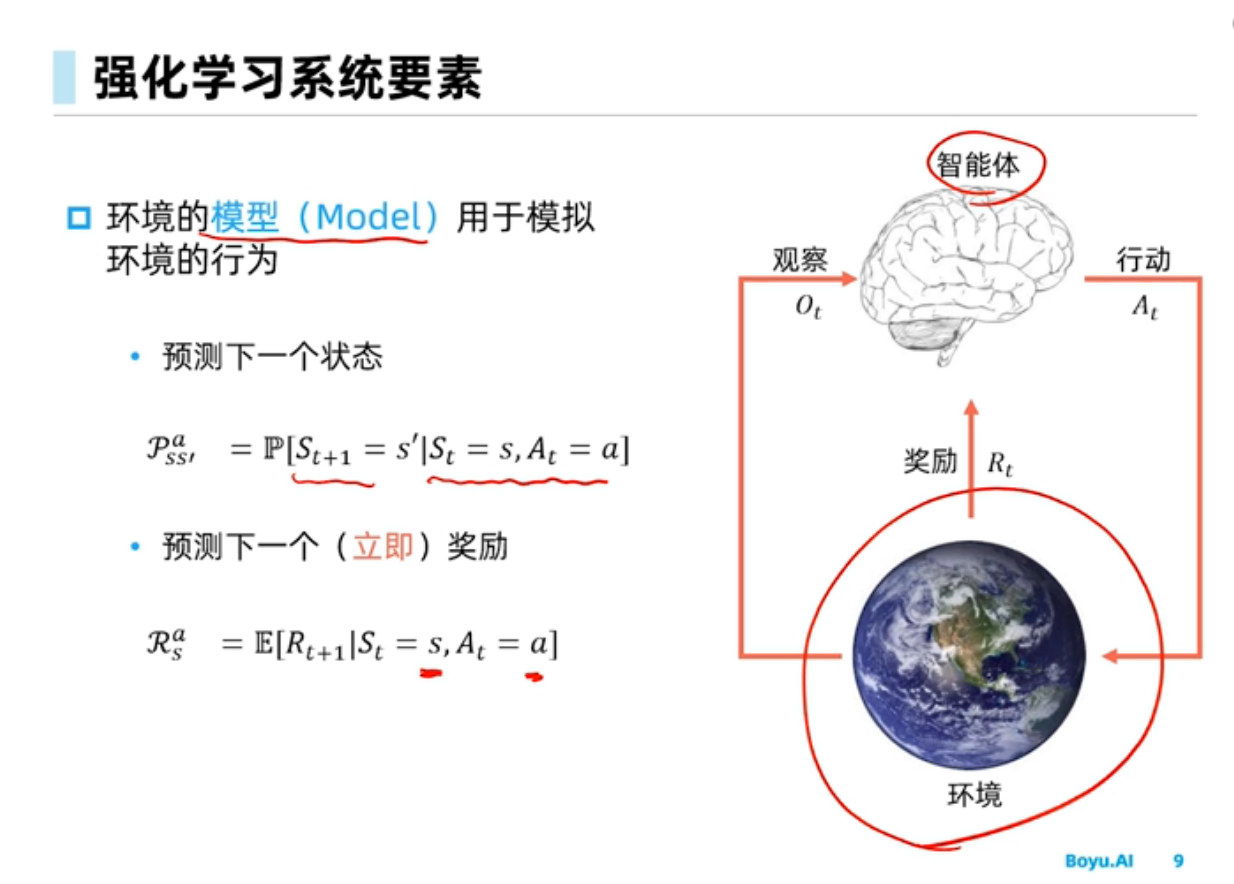
强化学习可分为基于model-base或者model-free的强化学习
model-base:知道环境信息,可以自己模拟
model-free:不知道环境信息,需要大量采样
Model-based RL最终效果还是会受到环境model本身精度不够的影响,导致最终效果往往不如model-free RL。


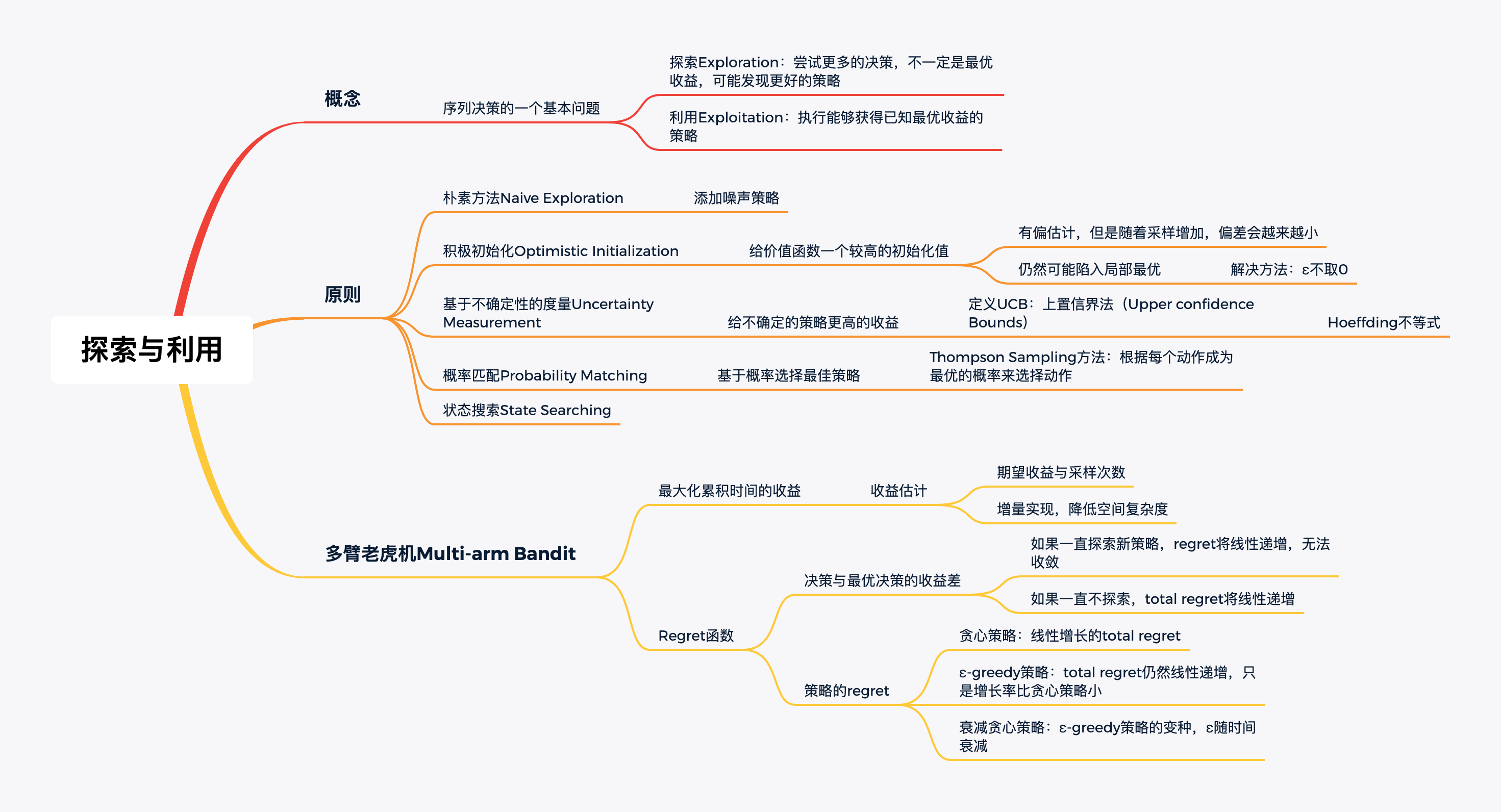
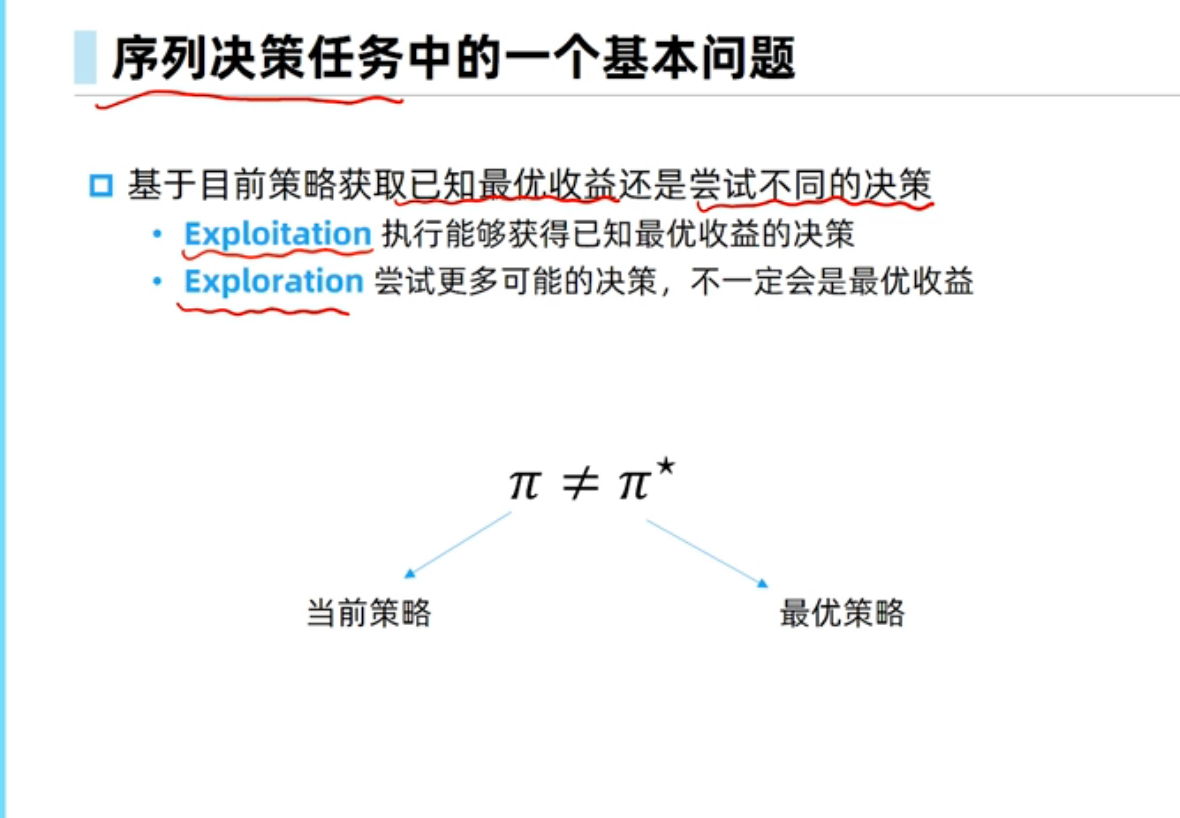
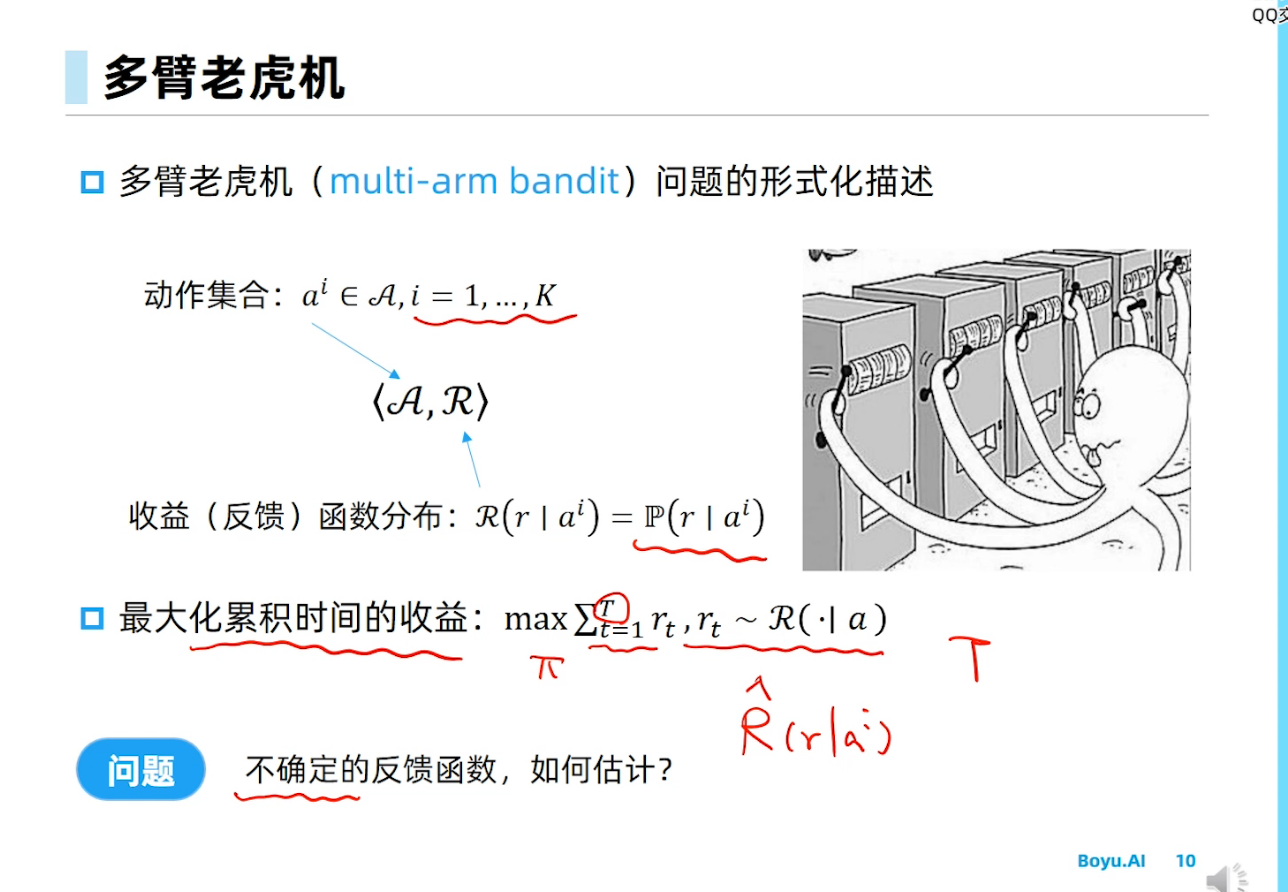
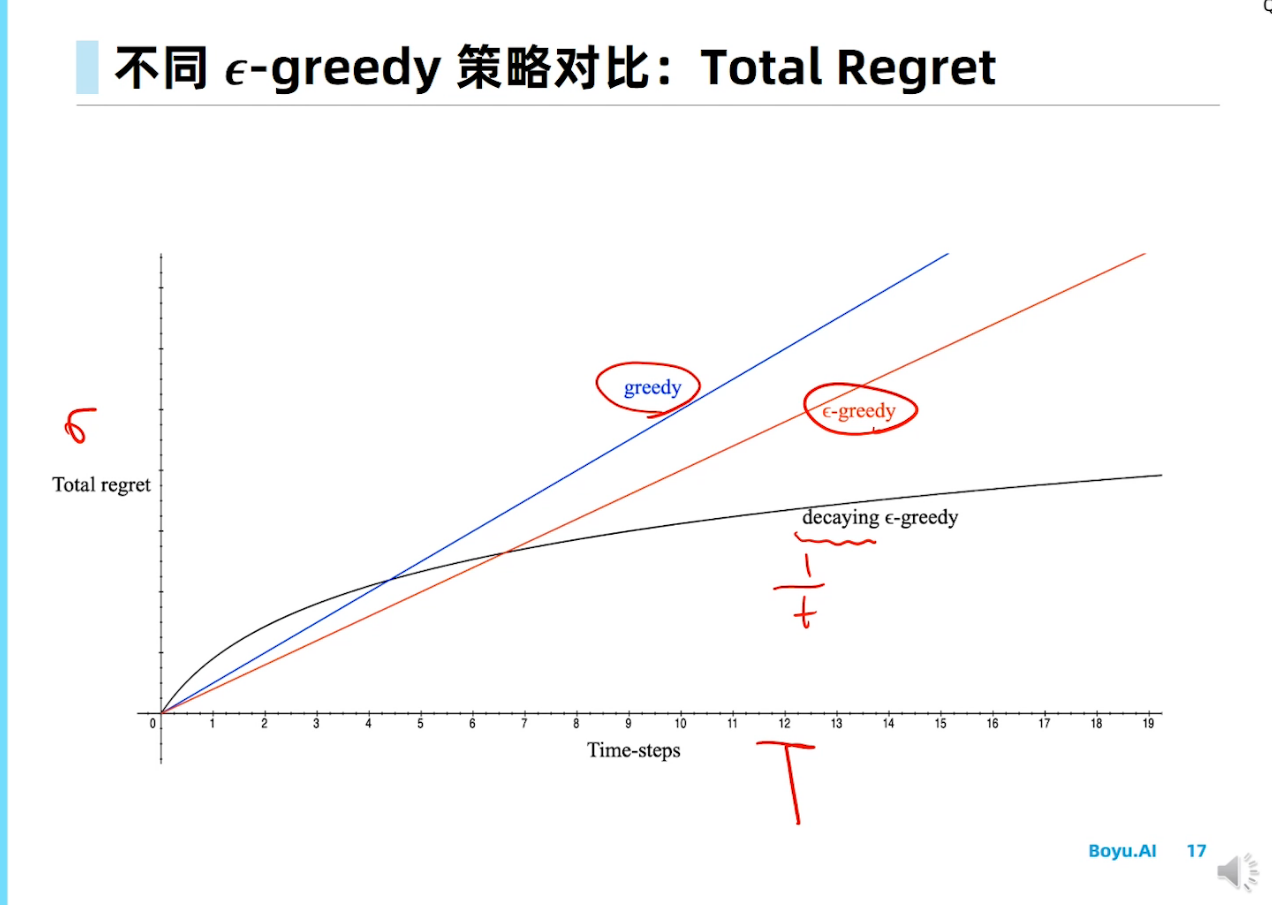
探索与利用
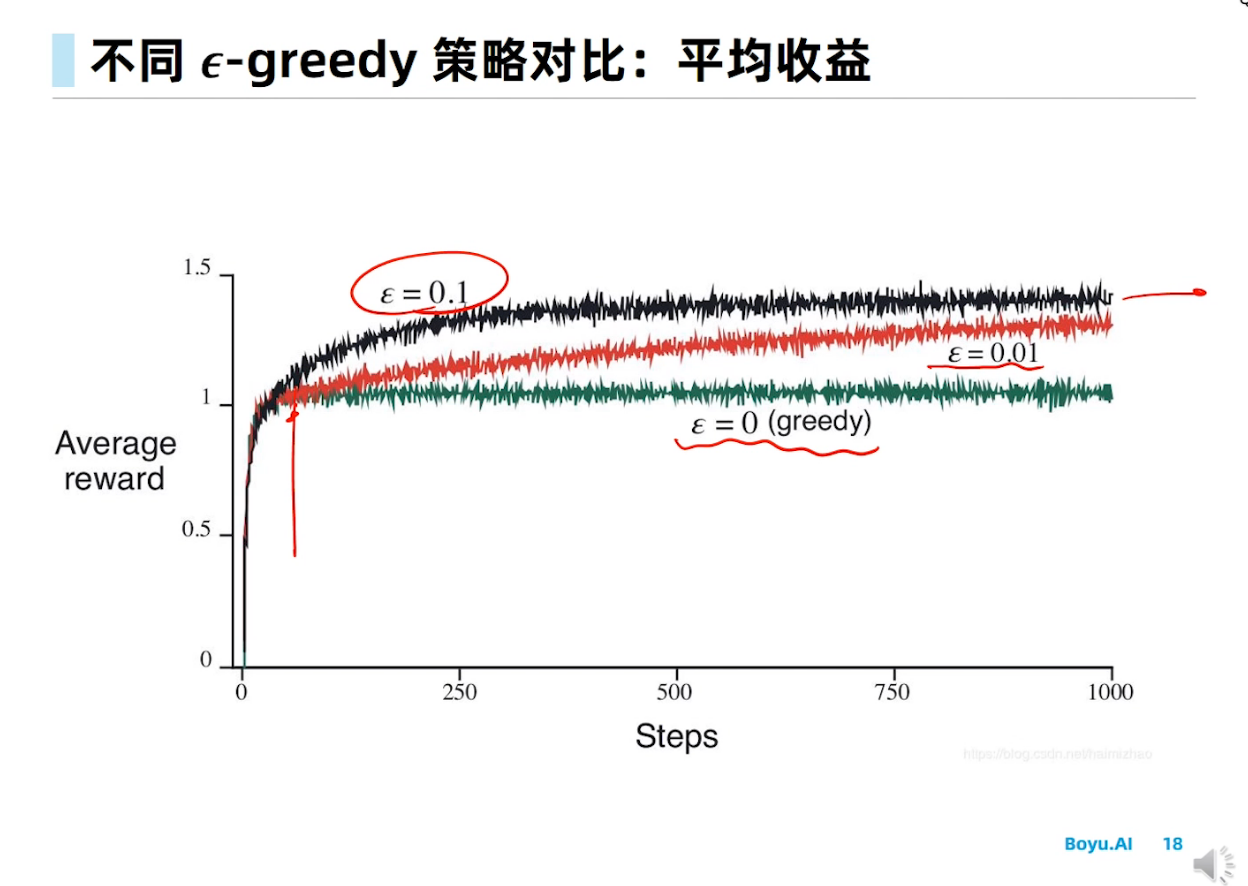
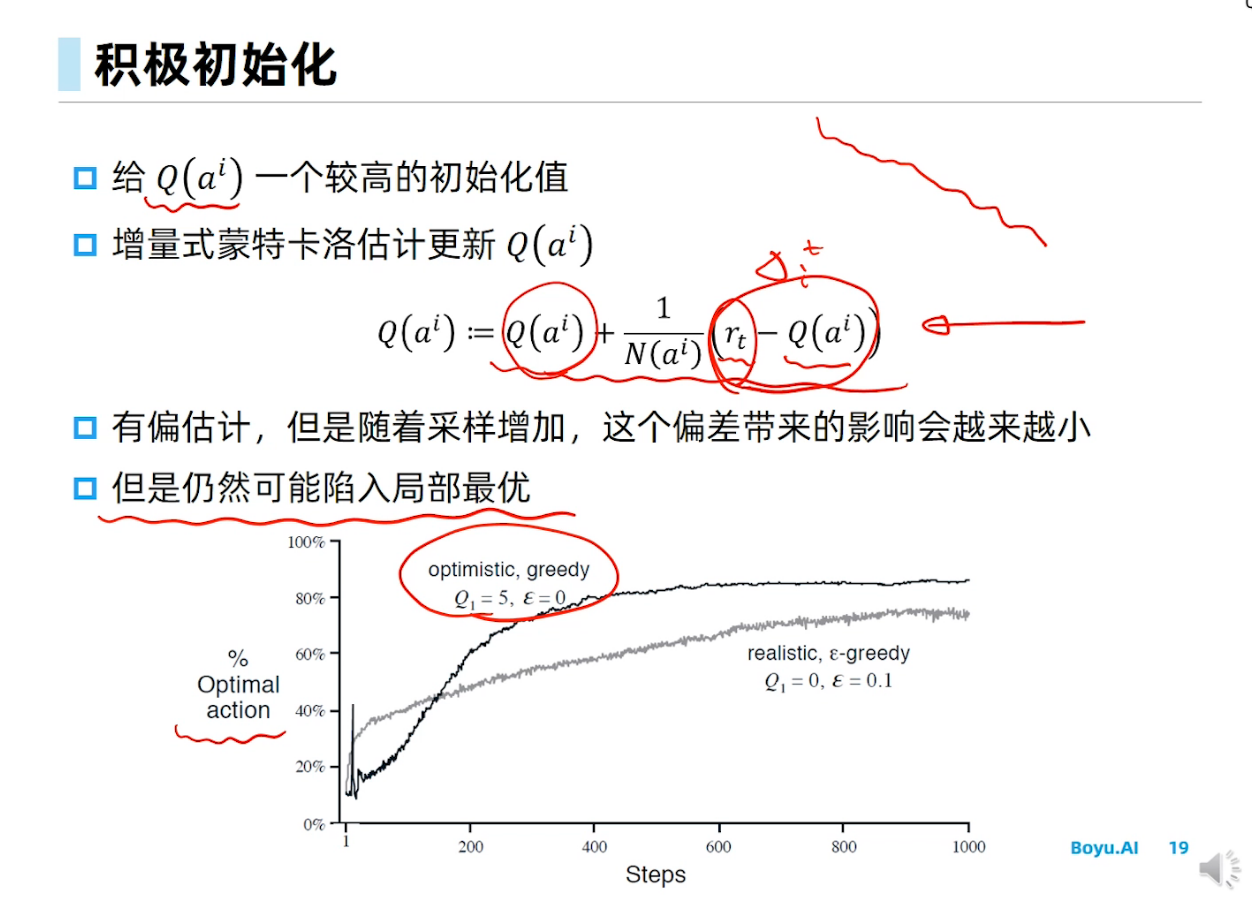
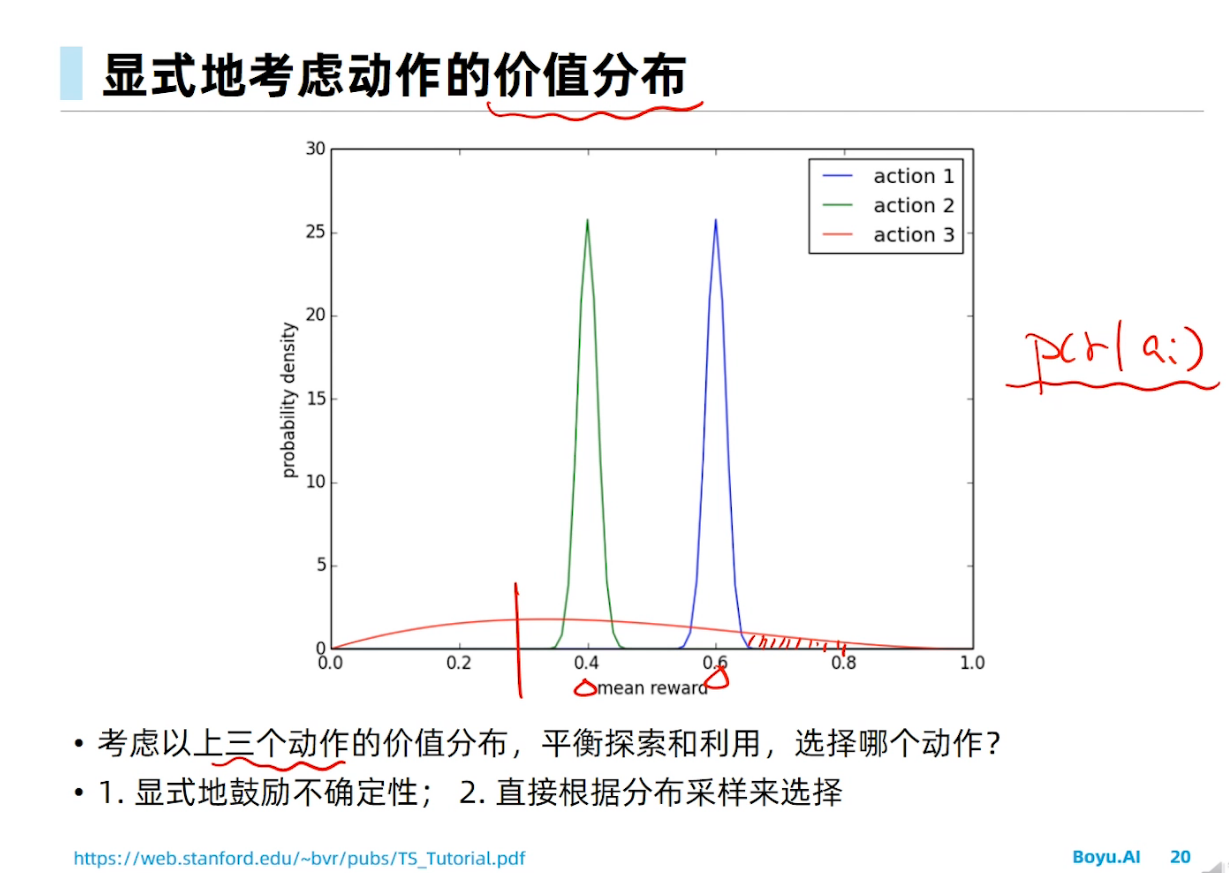
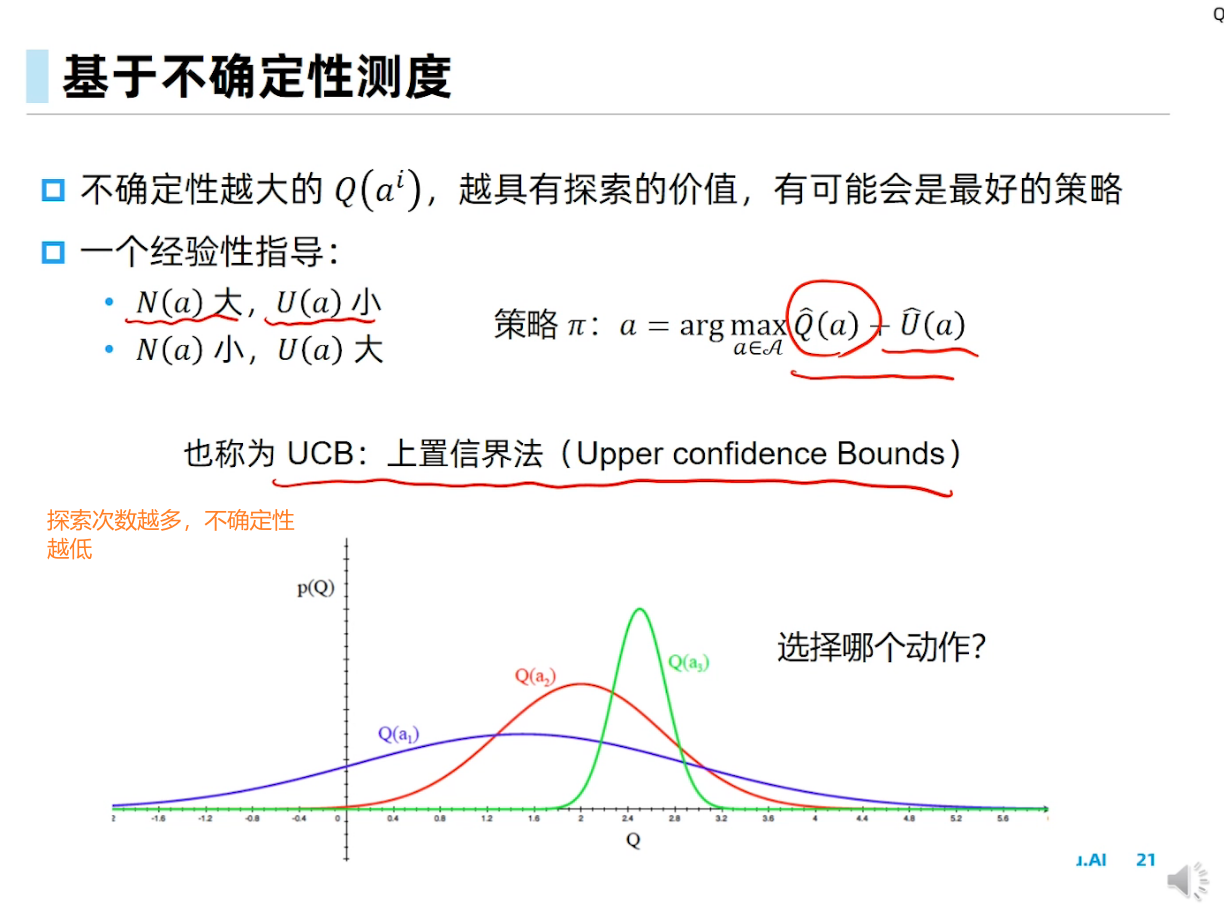
Epsilon greedy在RL里面是做探索的方法。其实RL领域也有不少其他的做探索的方法,只是专门在做探索,所以就不仅仅是UCB或者TS这种MAB的经典方法了。这个你搜索RL exploration methods就有不少工作。
例如,在树结构博弈环境里面UCB叫UCT (Upper Confidence bounds applied to Trees)。这方面很有名。David Silver的论文还拿了ICML的10年最佳论文奖:









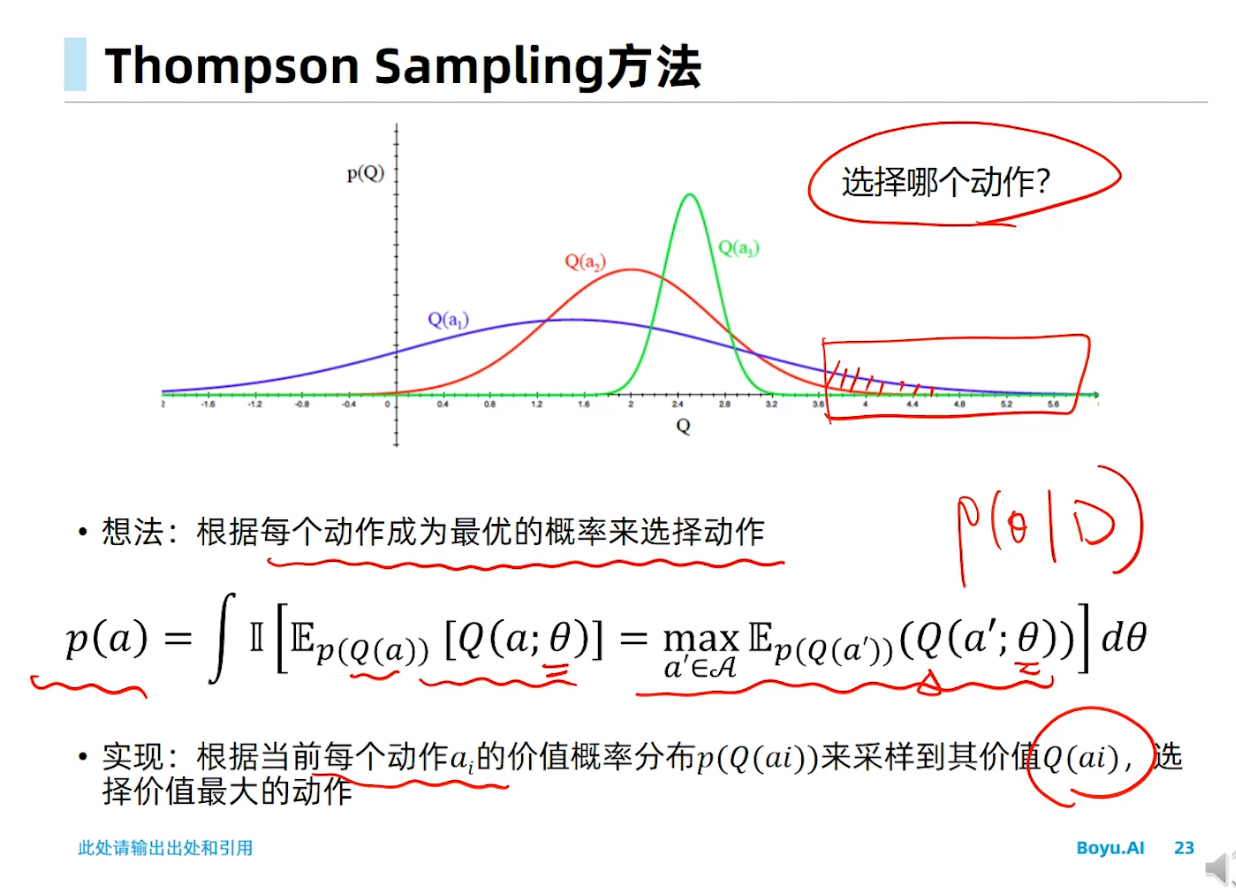
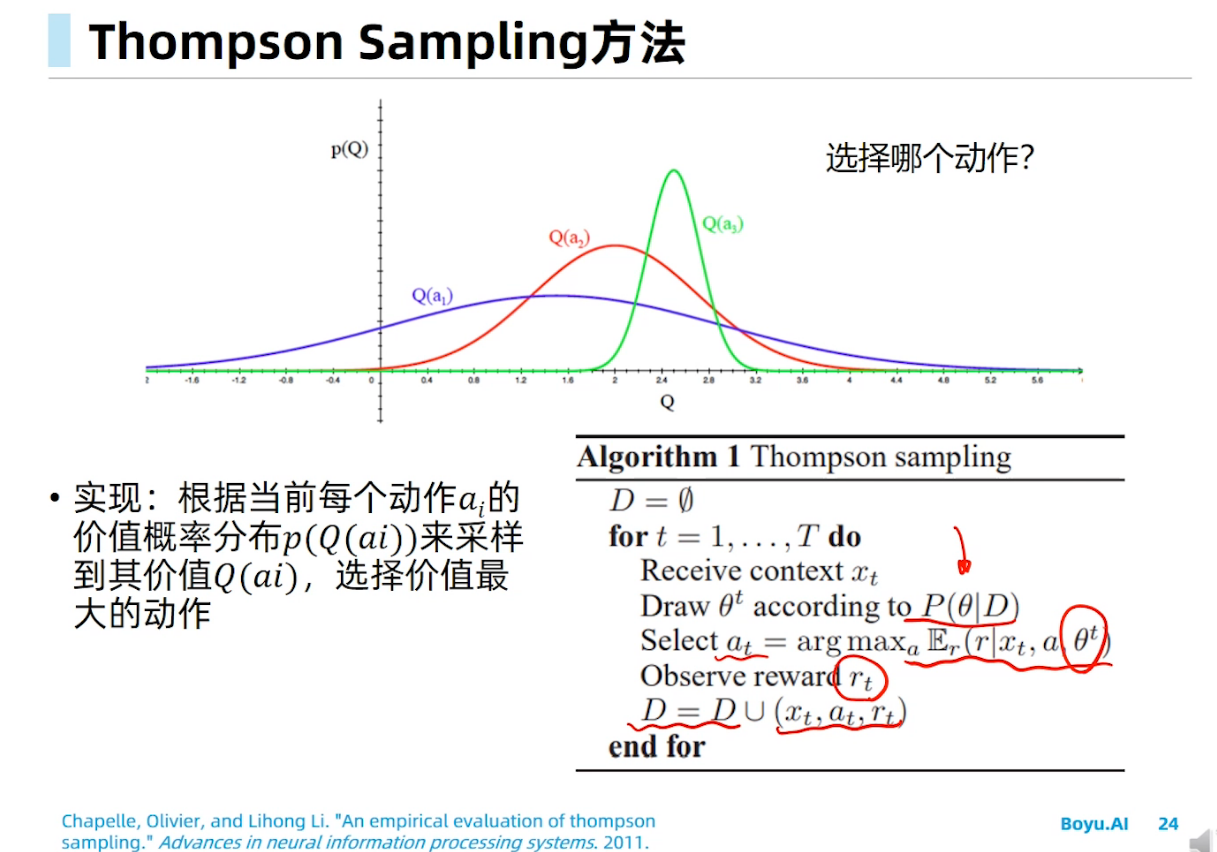
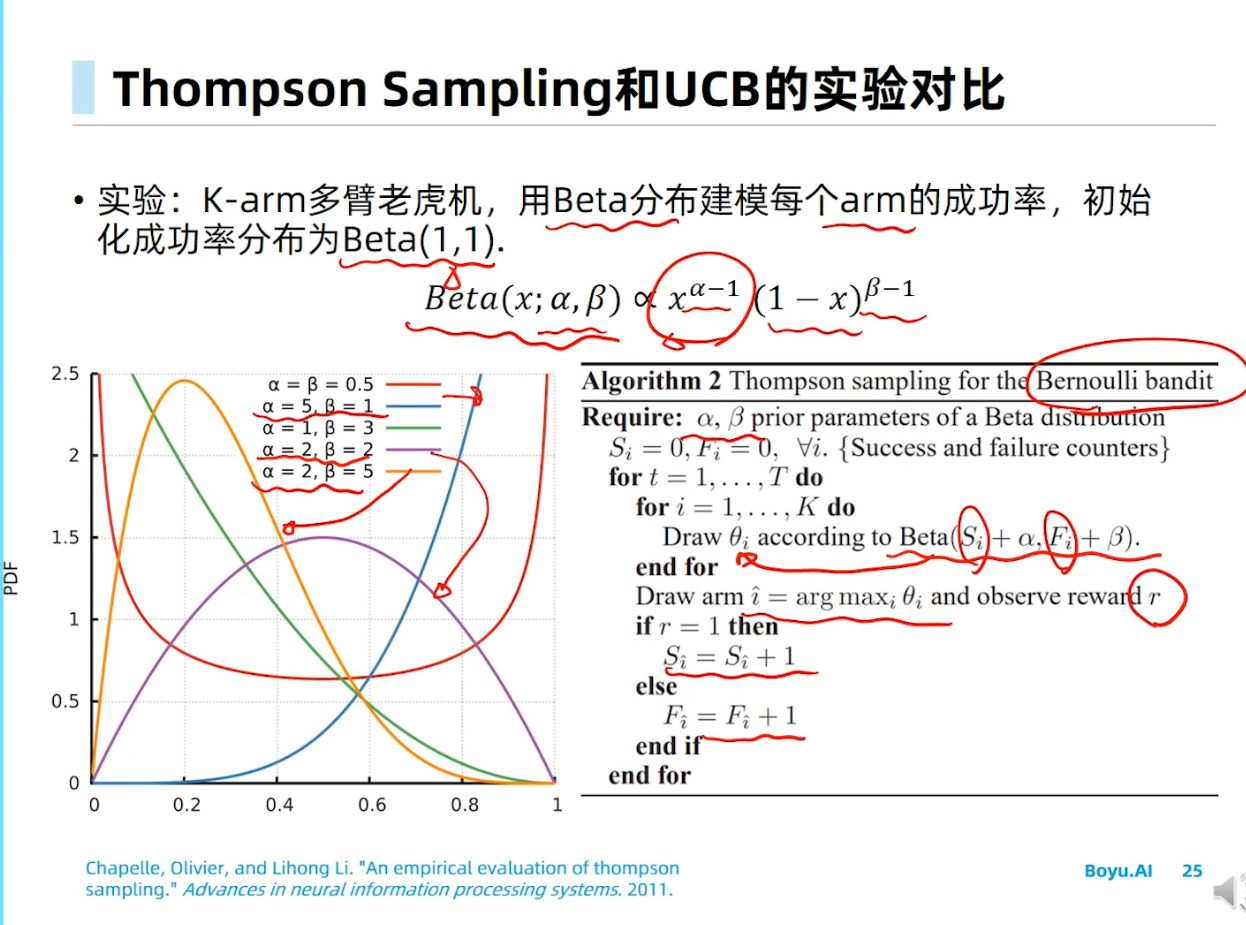
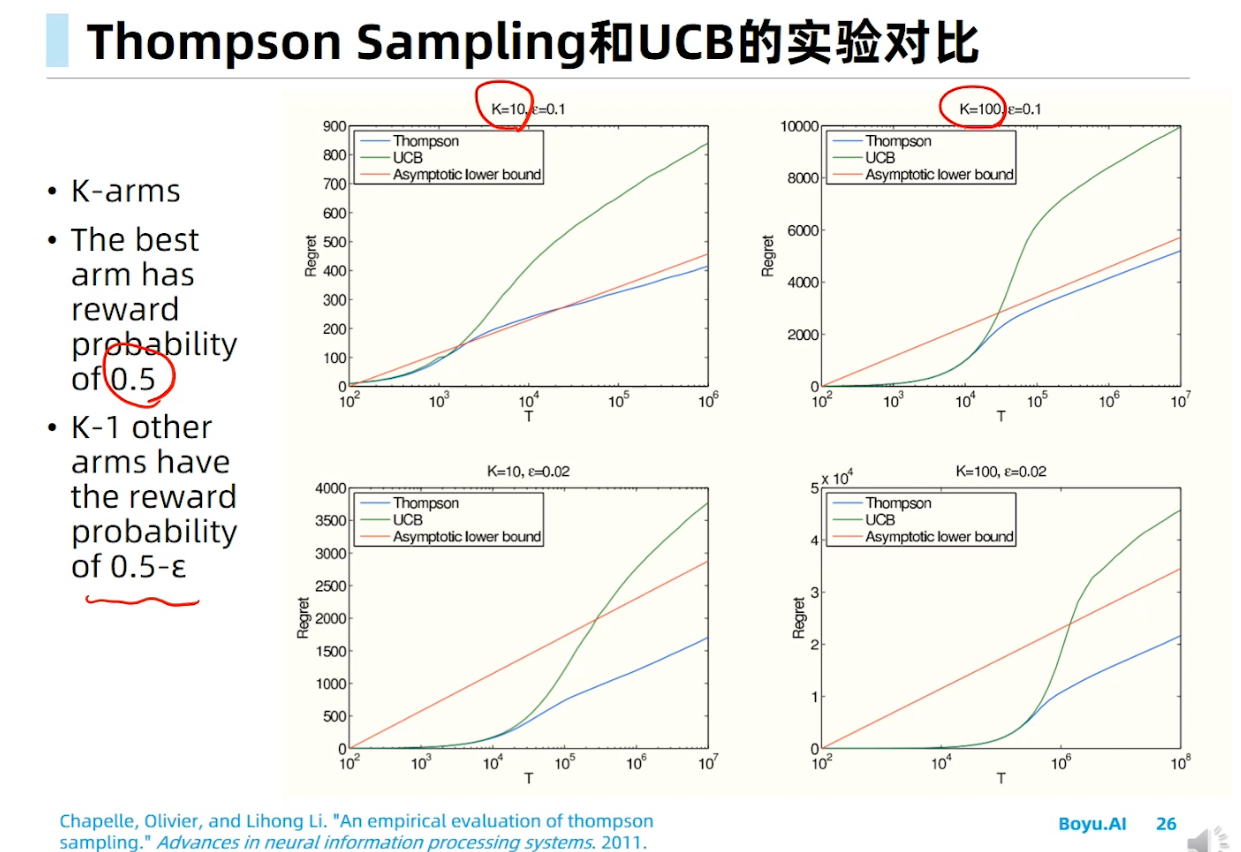

马尔科夫决策过程






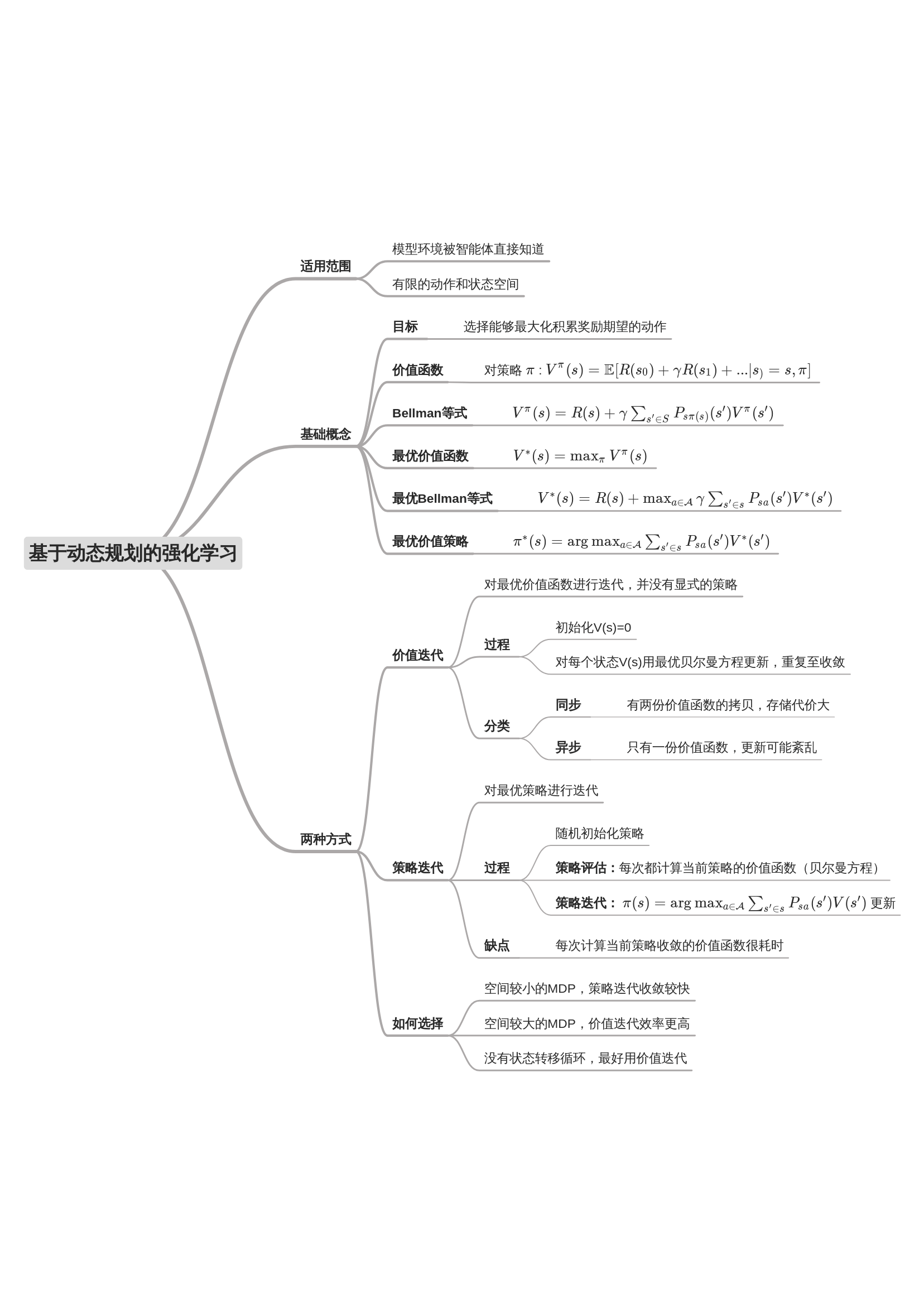
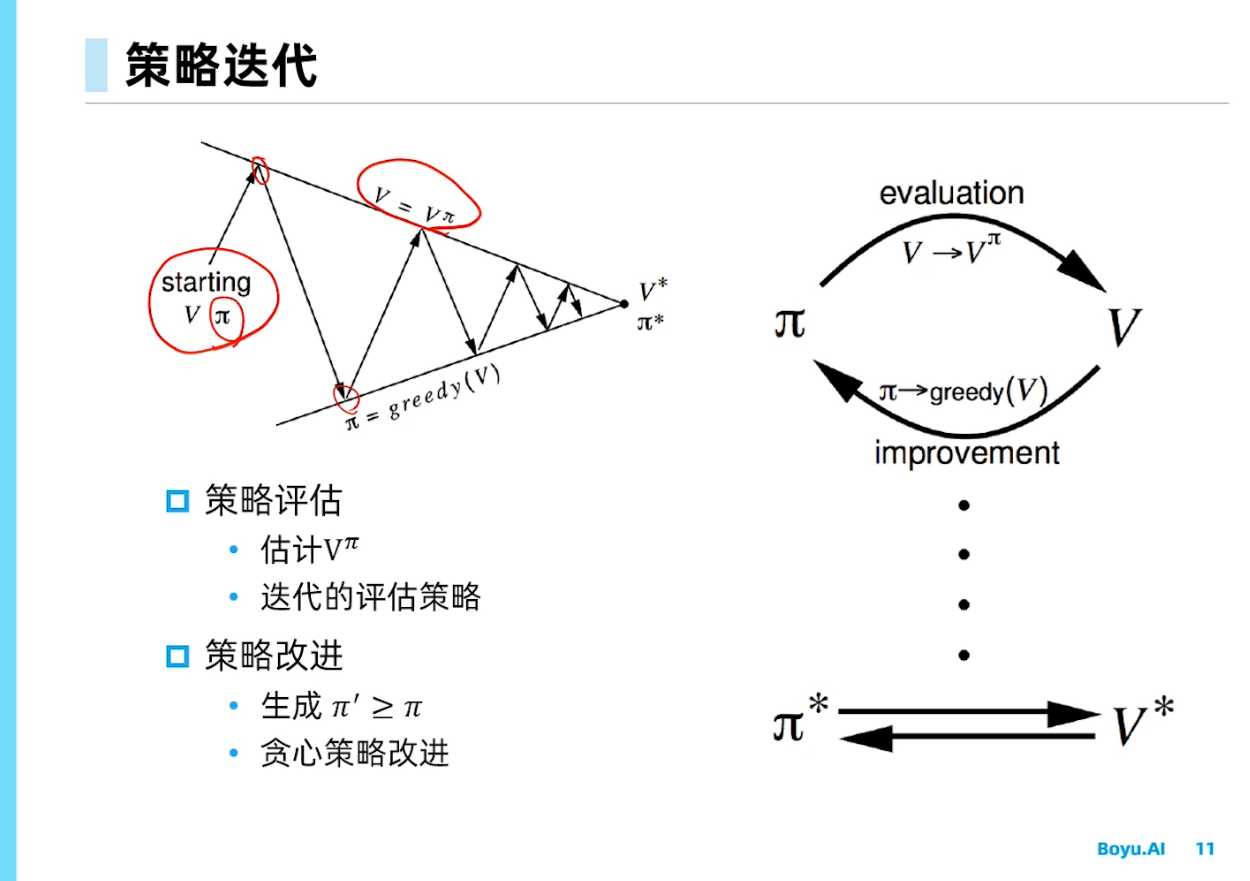
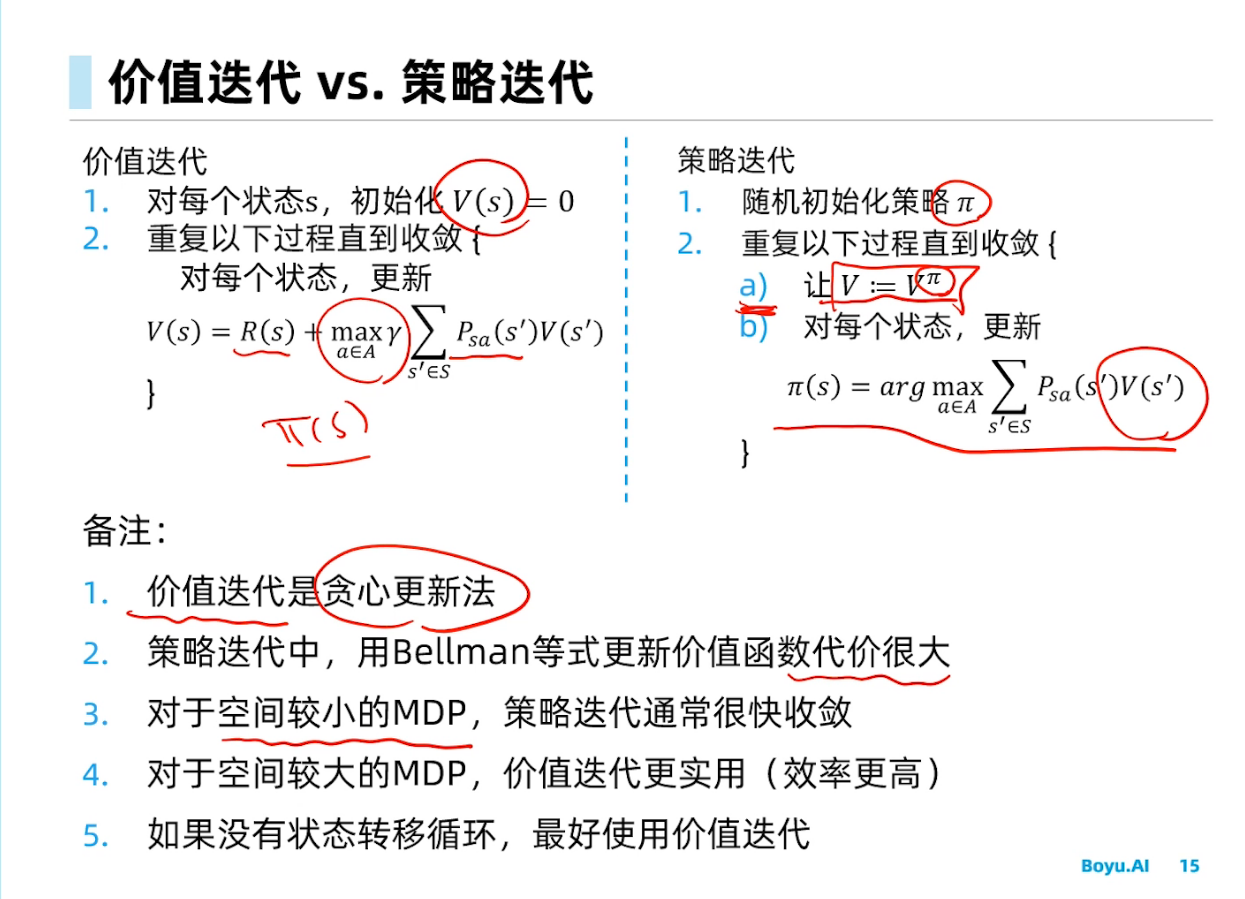
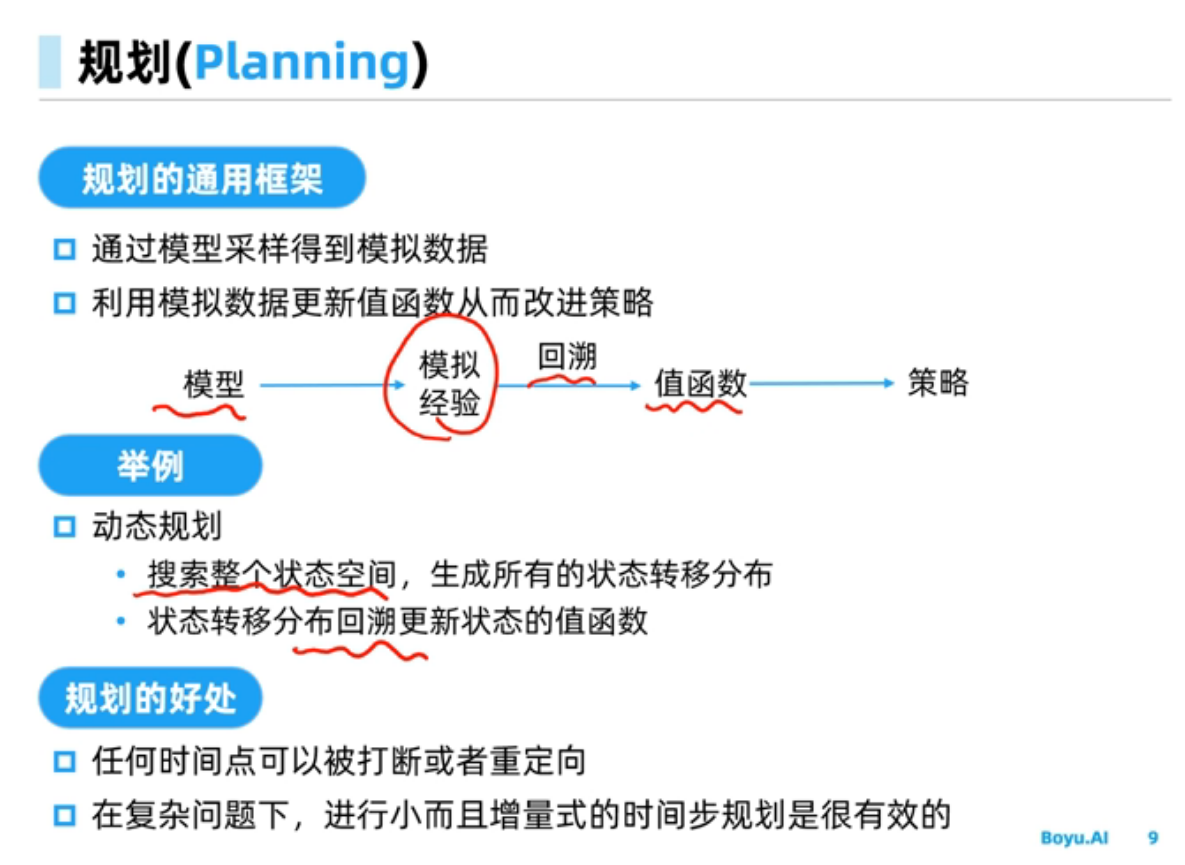
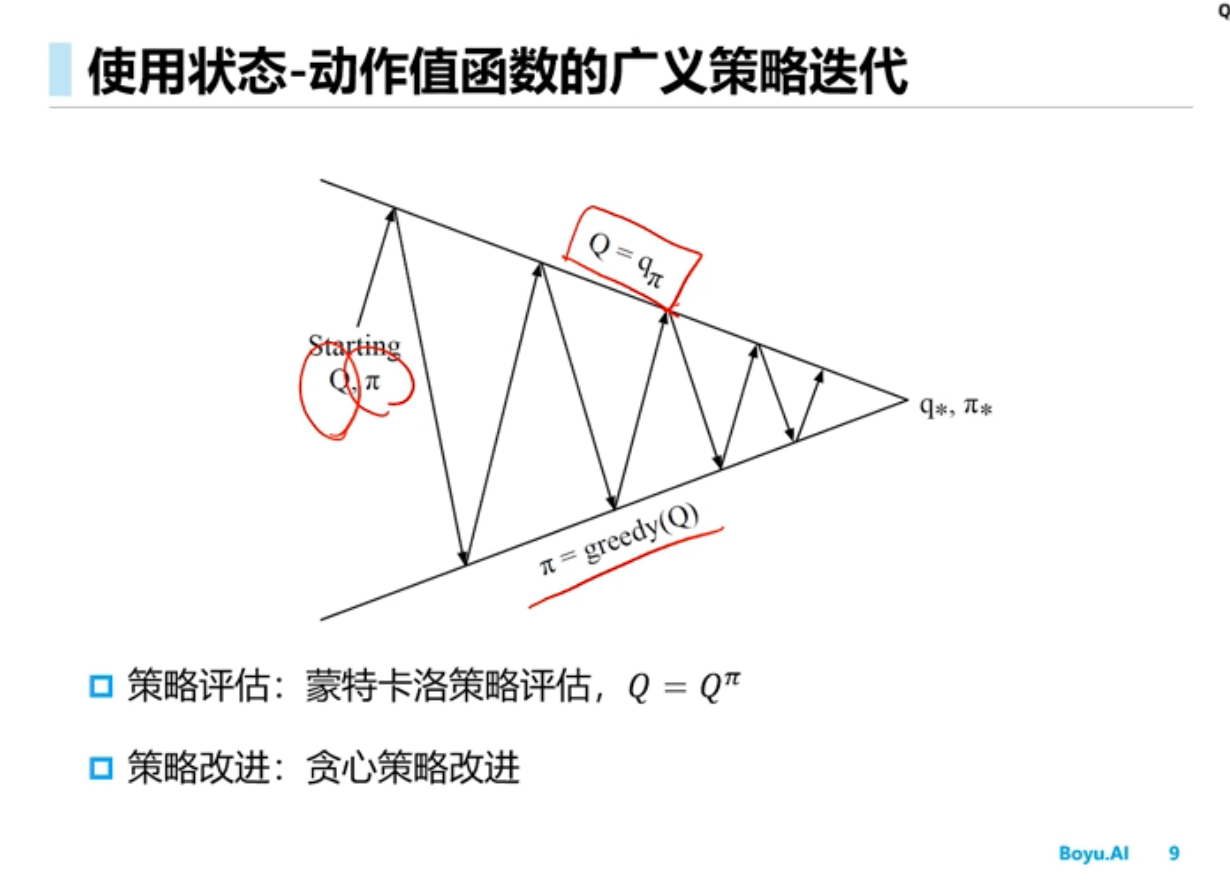
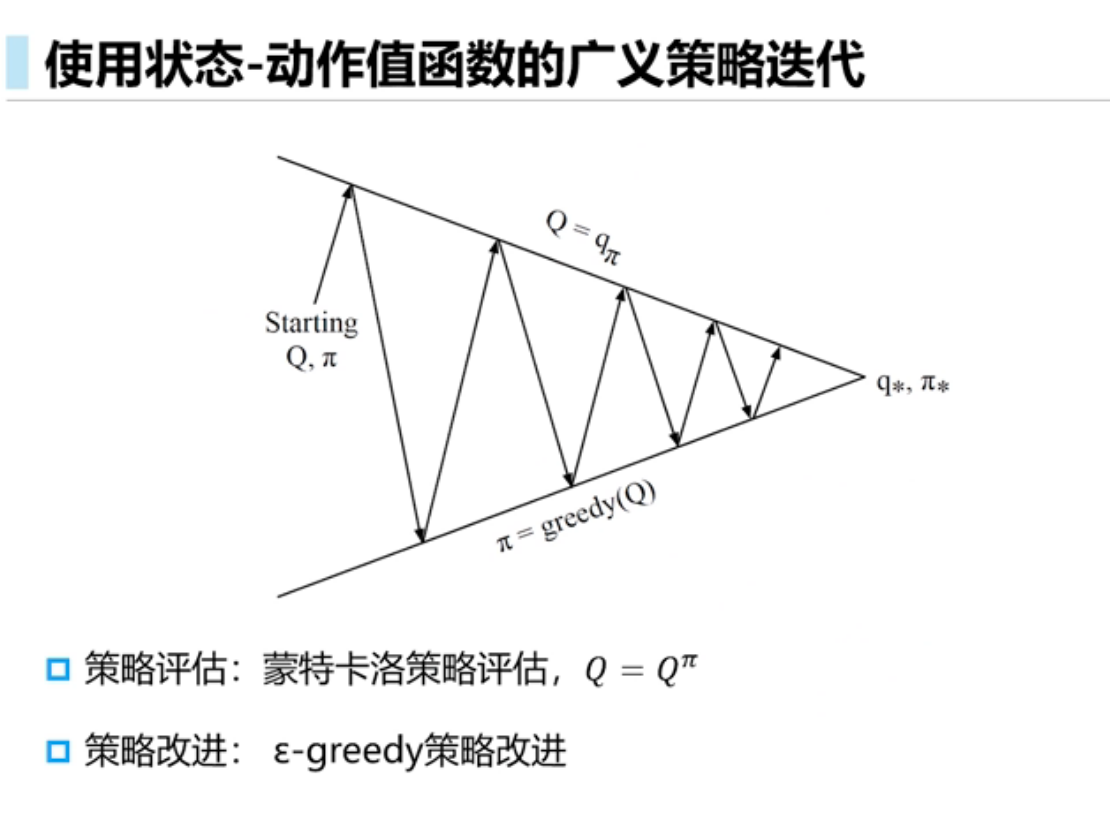
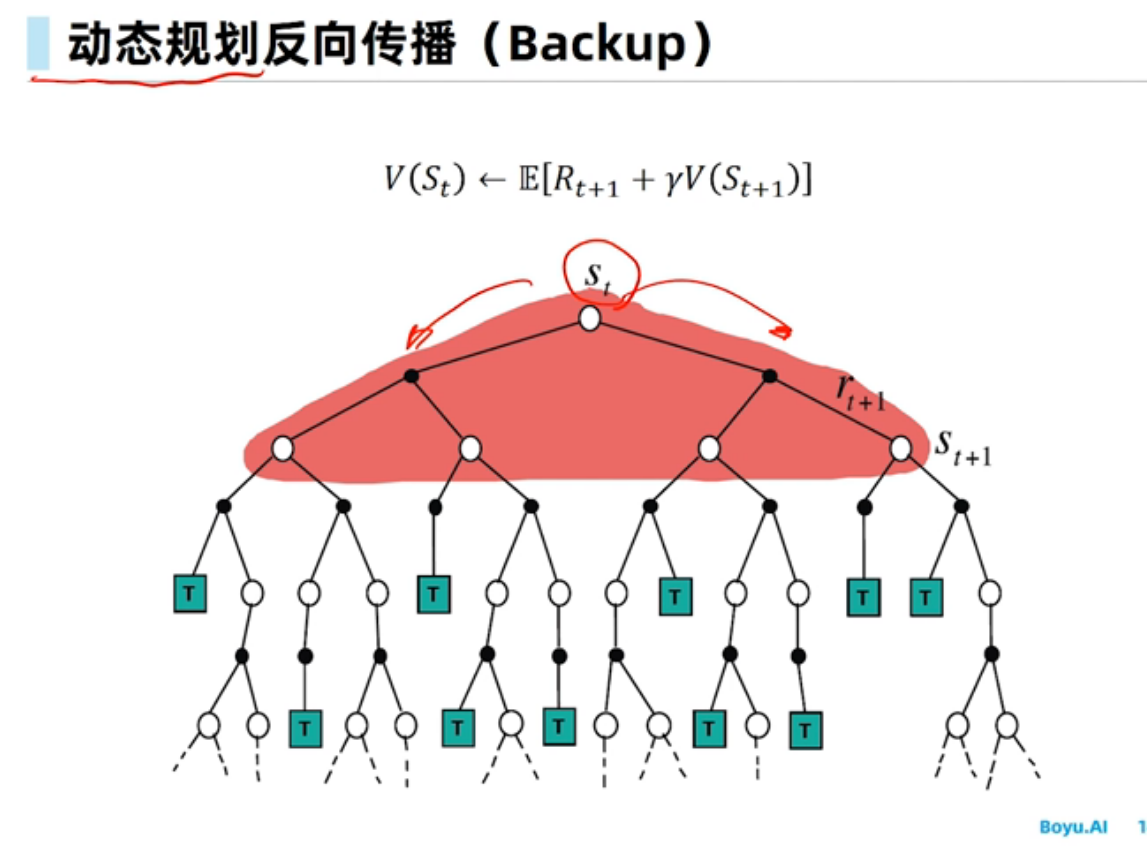
基于动态规划的强化学习
更新价值函数很耗时,对于空间较小的MDP,策略迭代通常更快收敛;而对于空间较大的价值迭代效率更高。







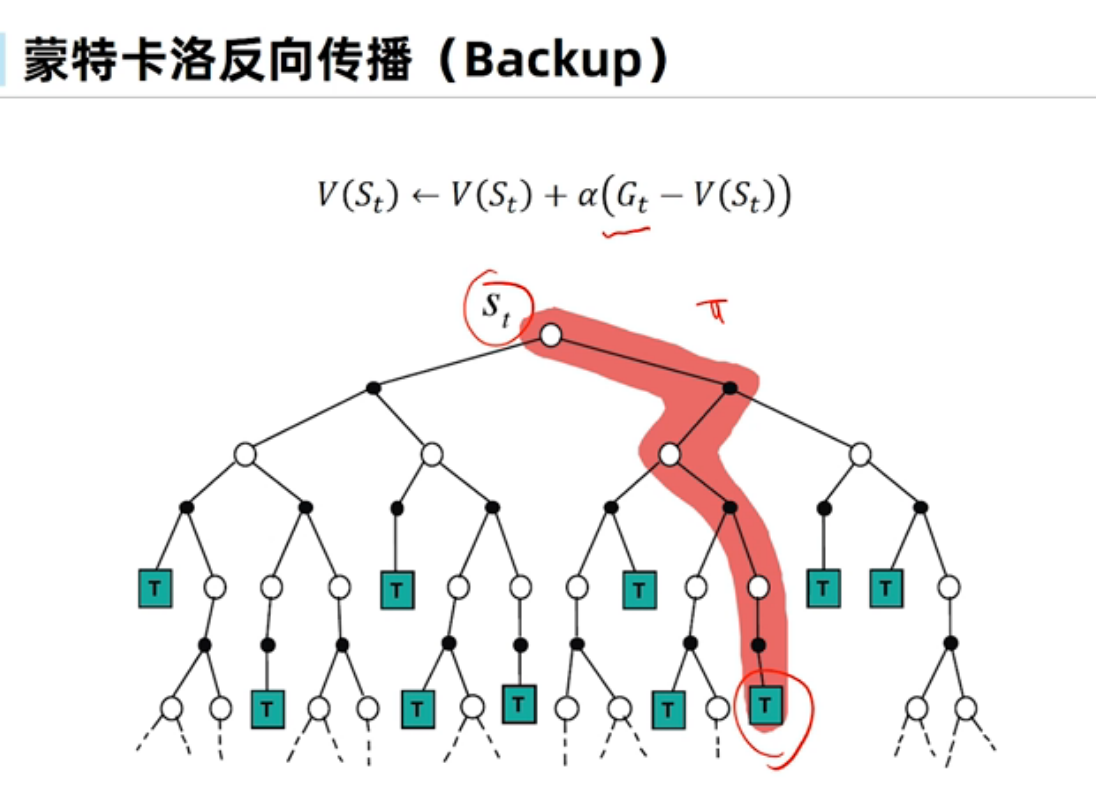
蒙特卡洛方法



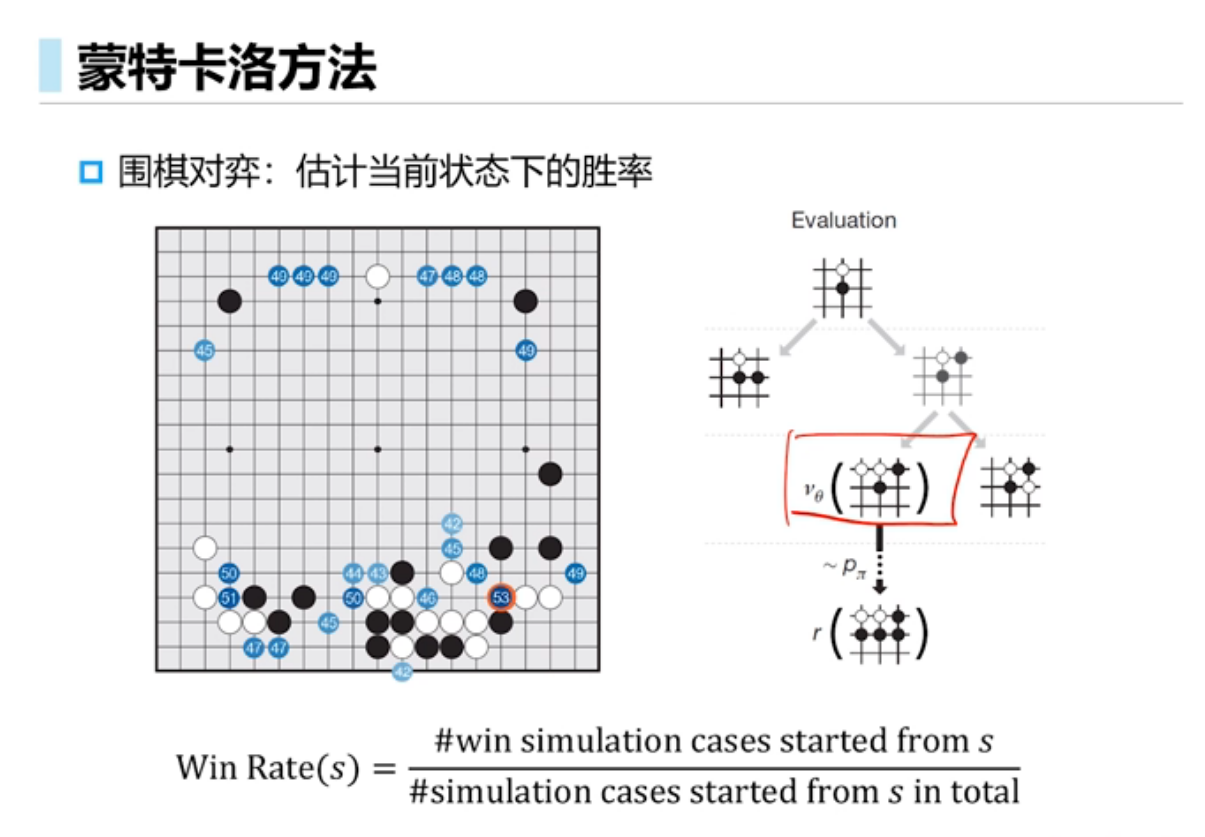
蒙特卡洛价值预测
蒙特卡洛策略评估使用经验平均累计奖励而不是期望累计奖励




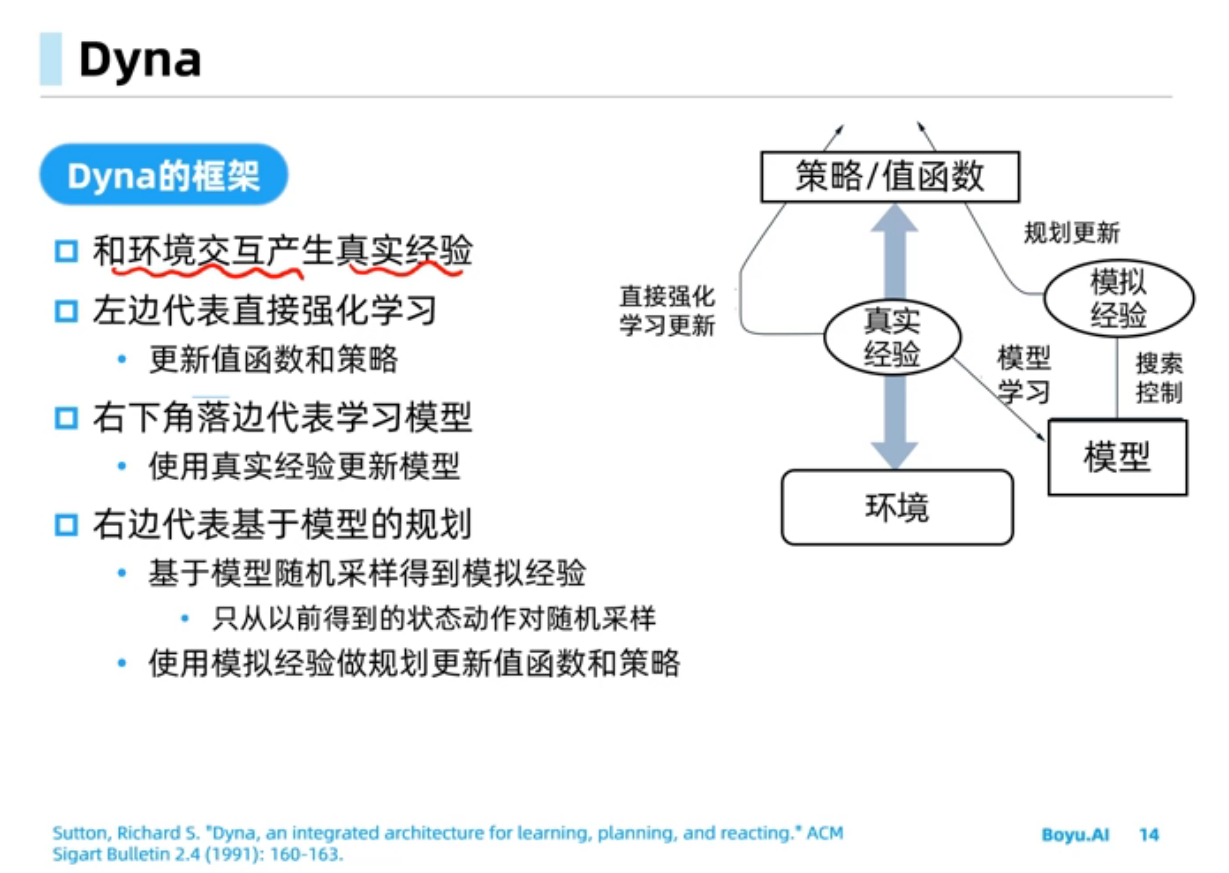
规划与学习
入门
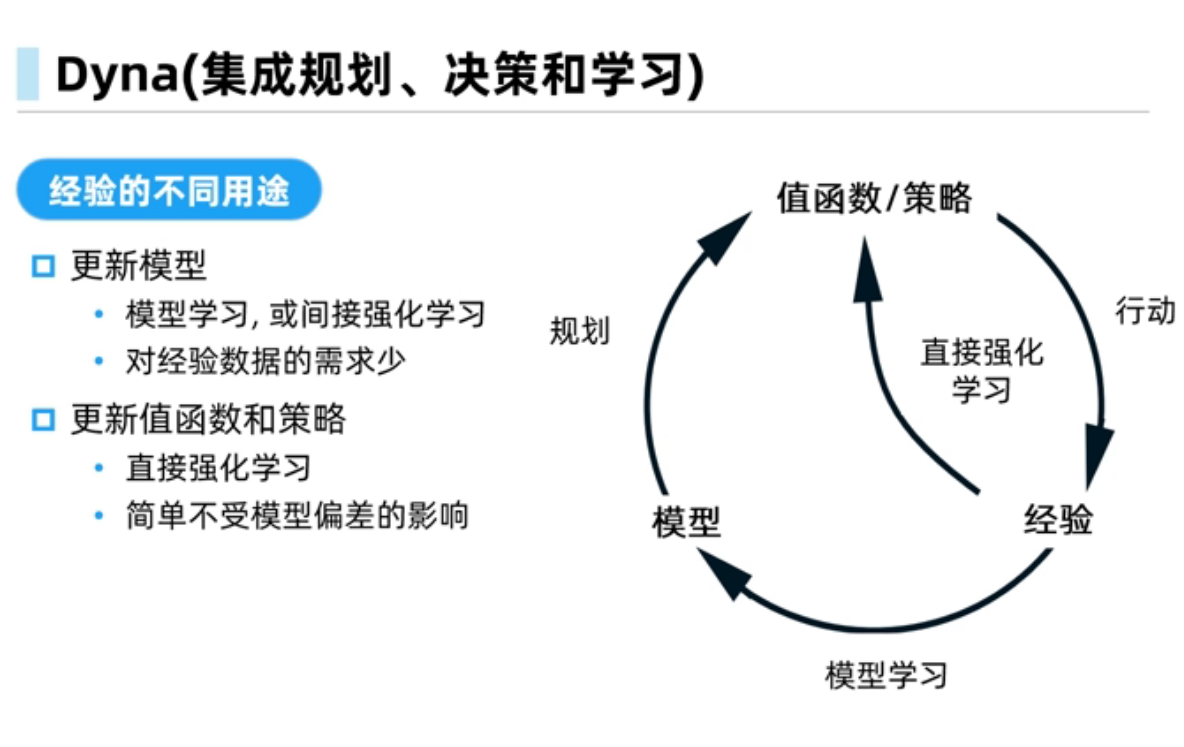
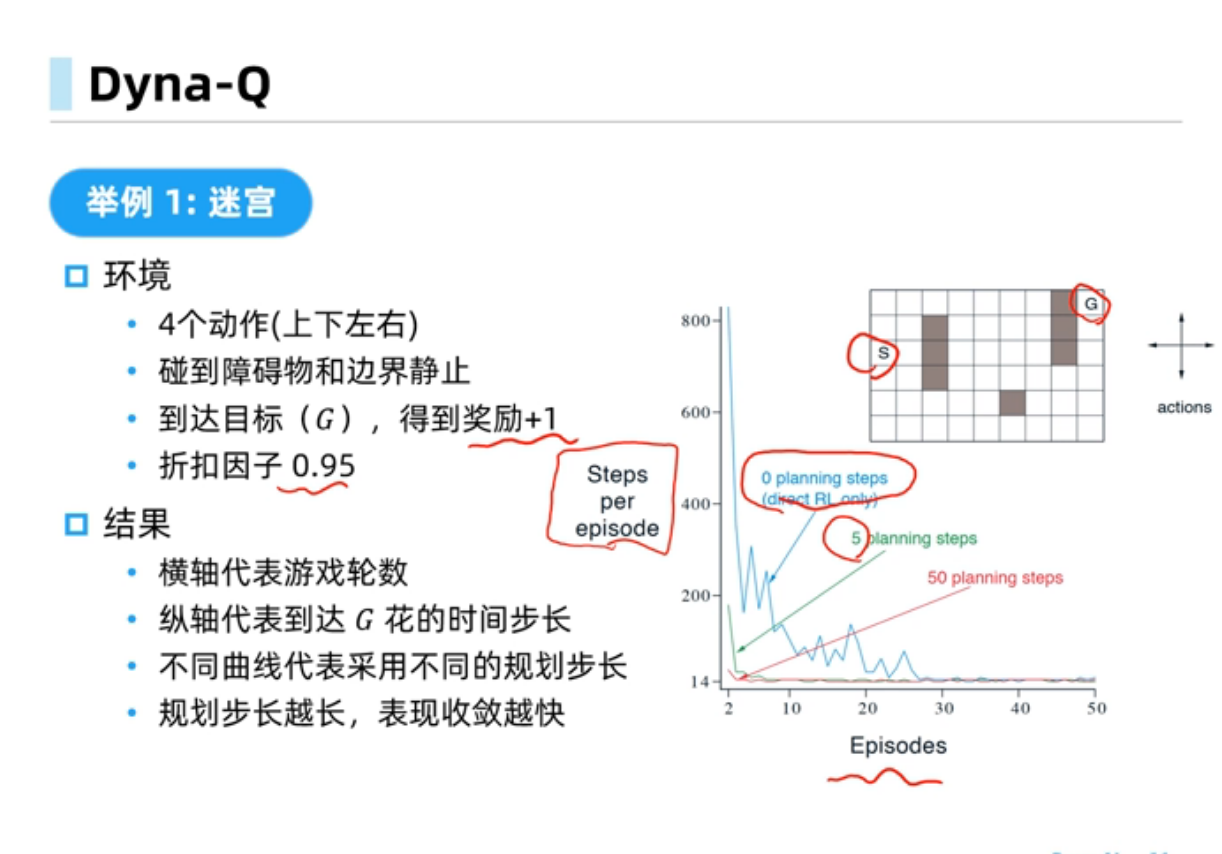
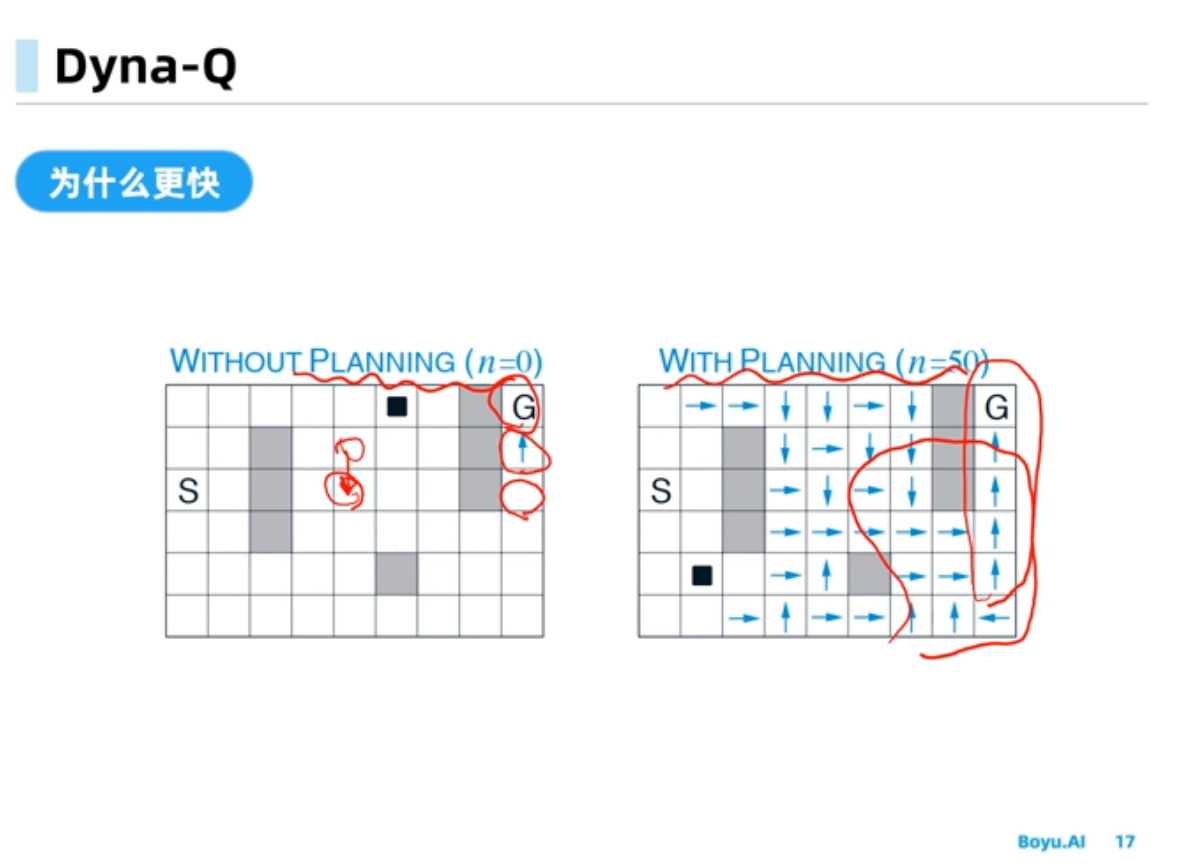
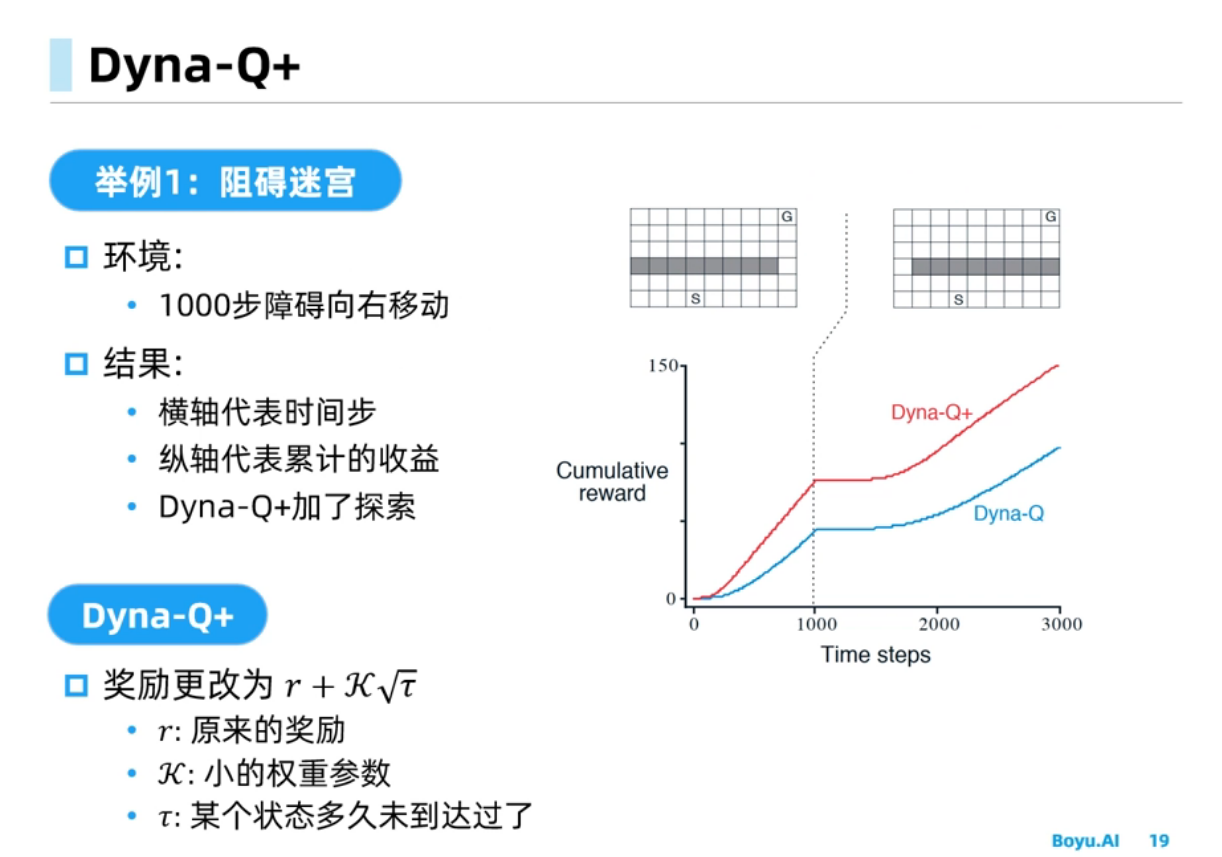
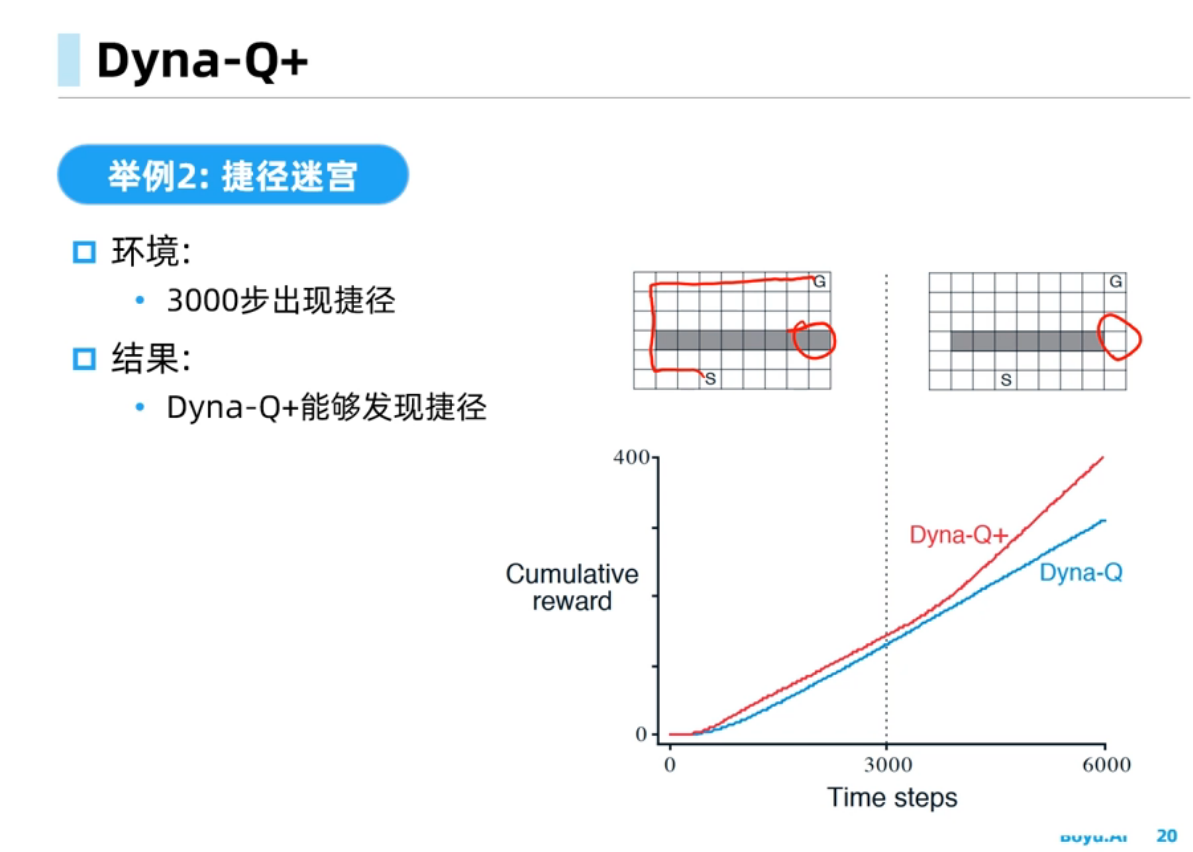
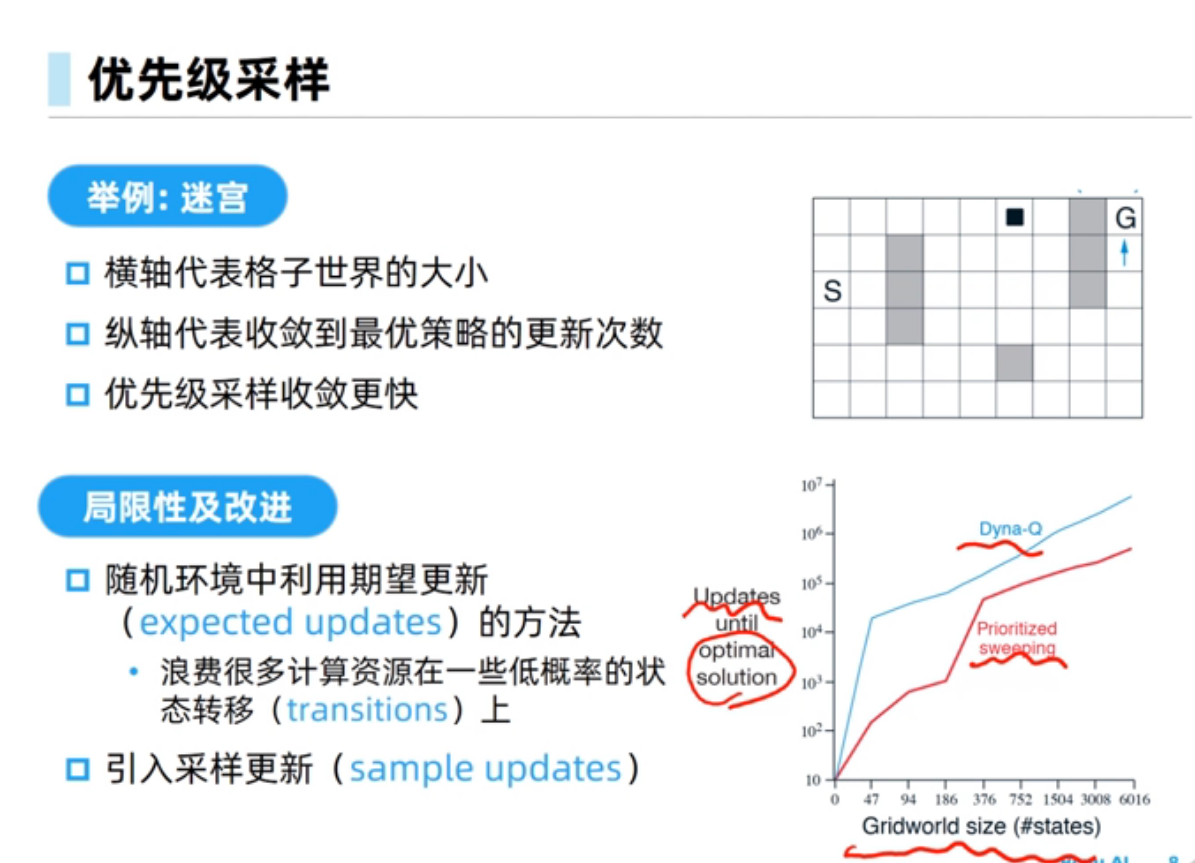
Dyna-Q中规划会受到模型偏差的影响,经验需求量比较小,规划可以使得策略能够收敛的更快, Dyna-Q+可以在环境改变时能够快速反应得到更好的策略
环境本身去建模,称为环境模型。
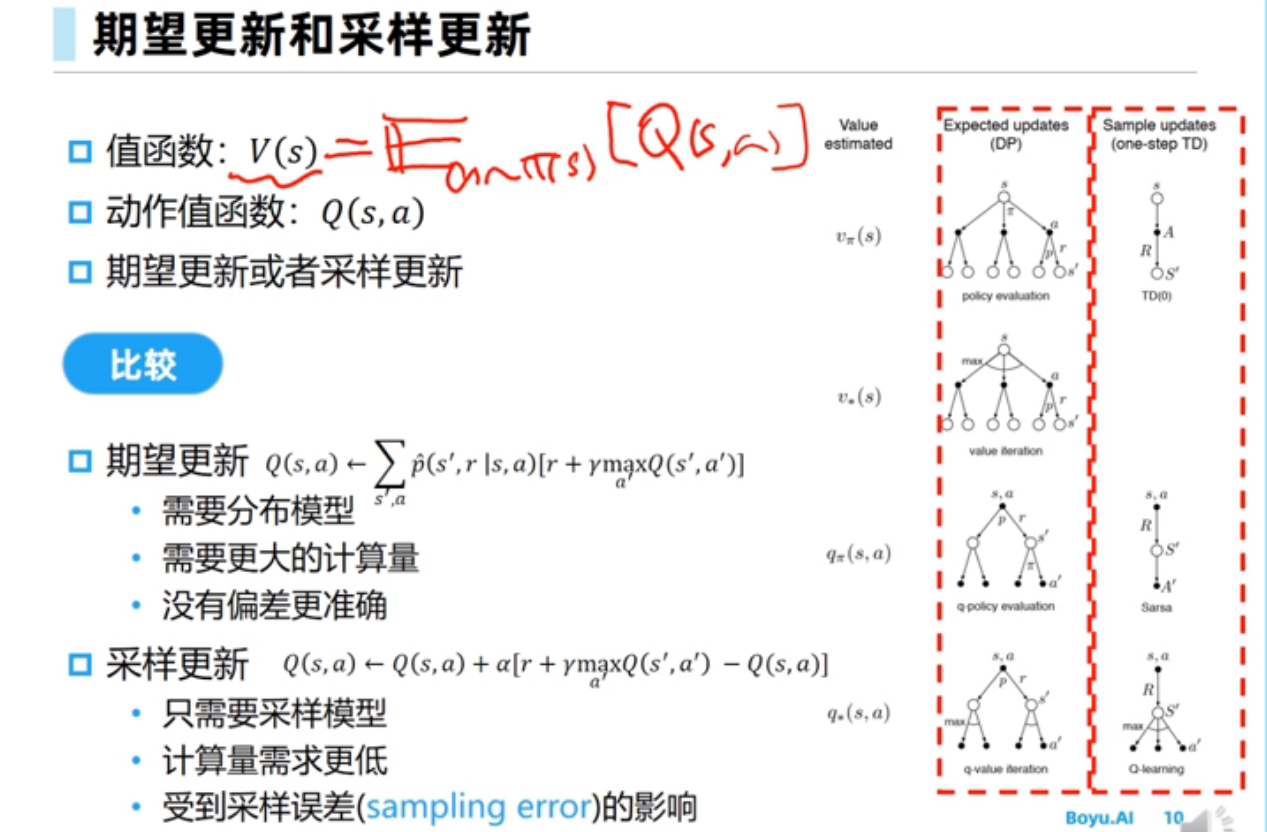
分布模型可以看做白盒,样本模型可以视作为黑盒



只有$S,A$是真实的,$R,S’$是模型给出的,被称为模拟经验。然后进行Q-planning更新$Q(S,A)$




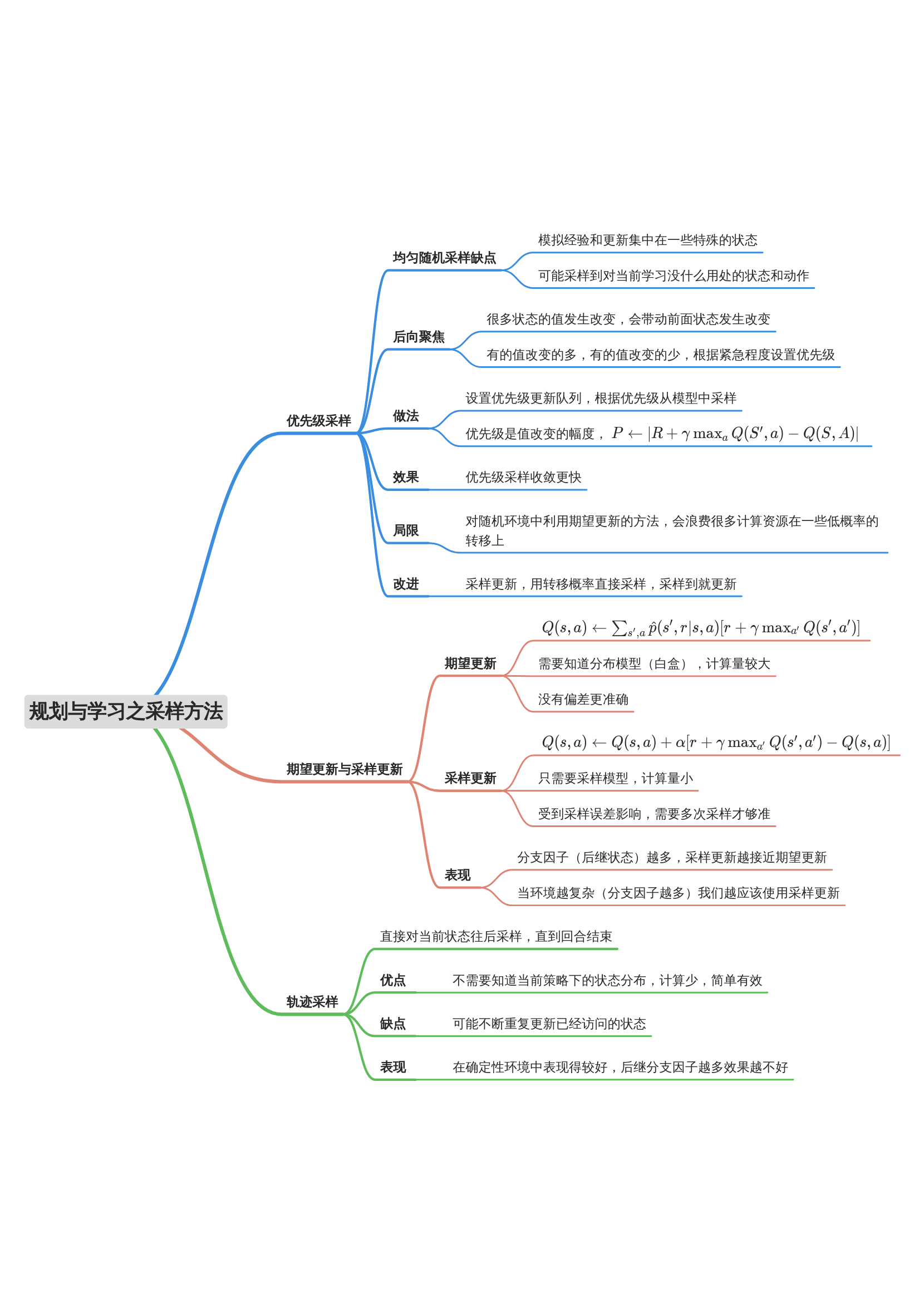
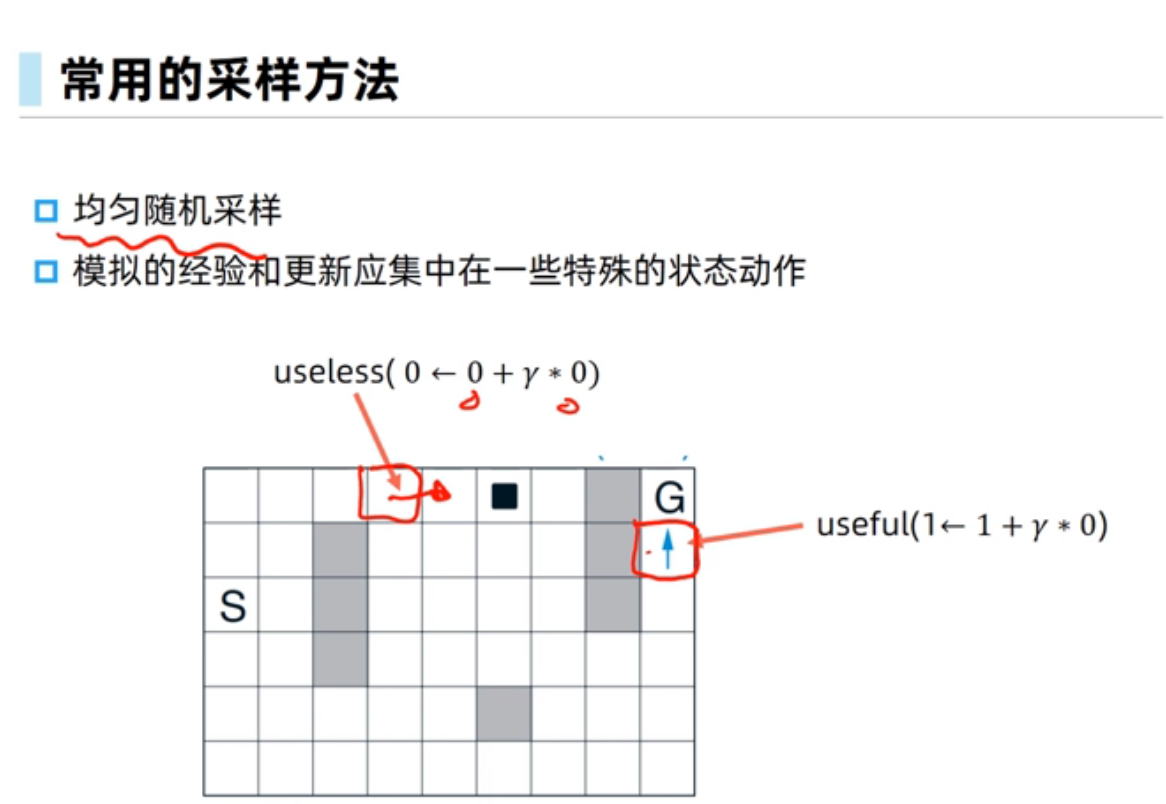
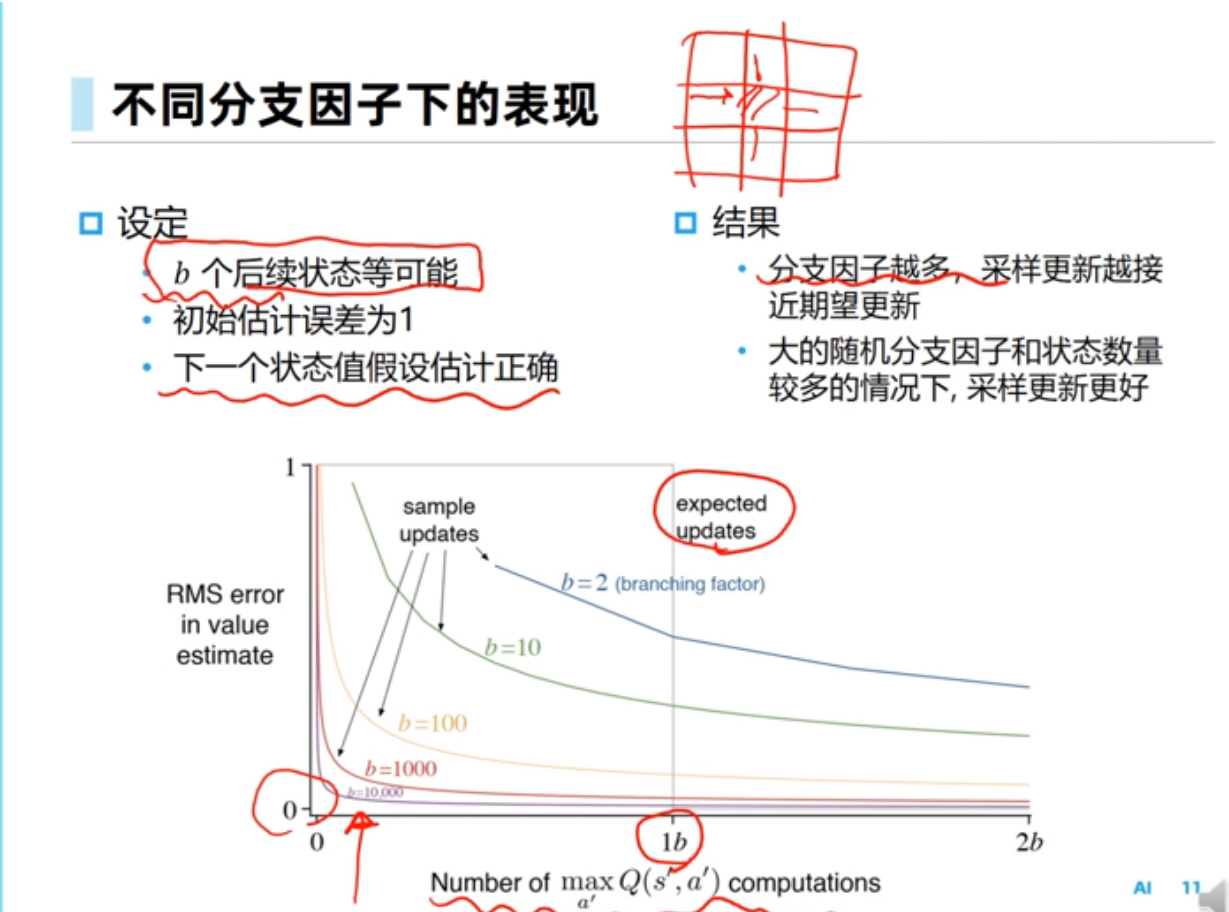
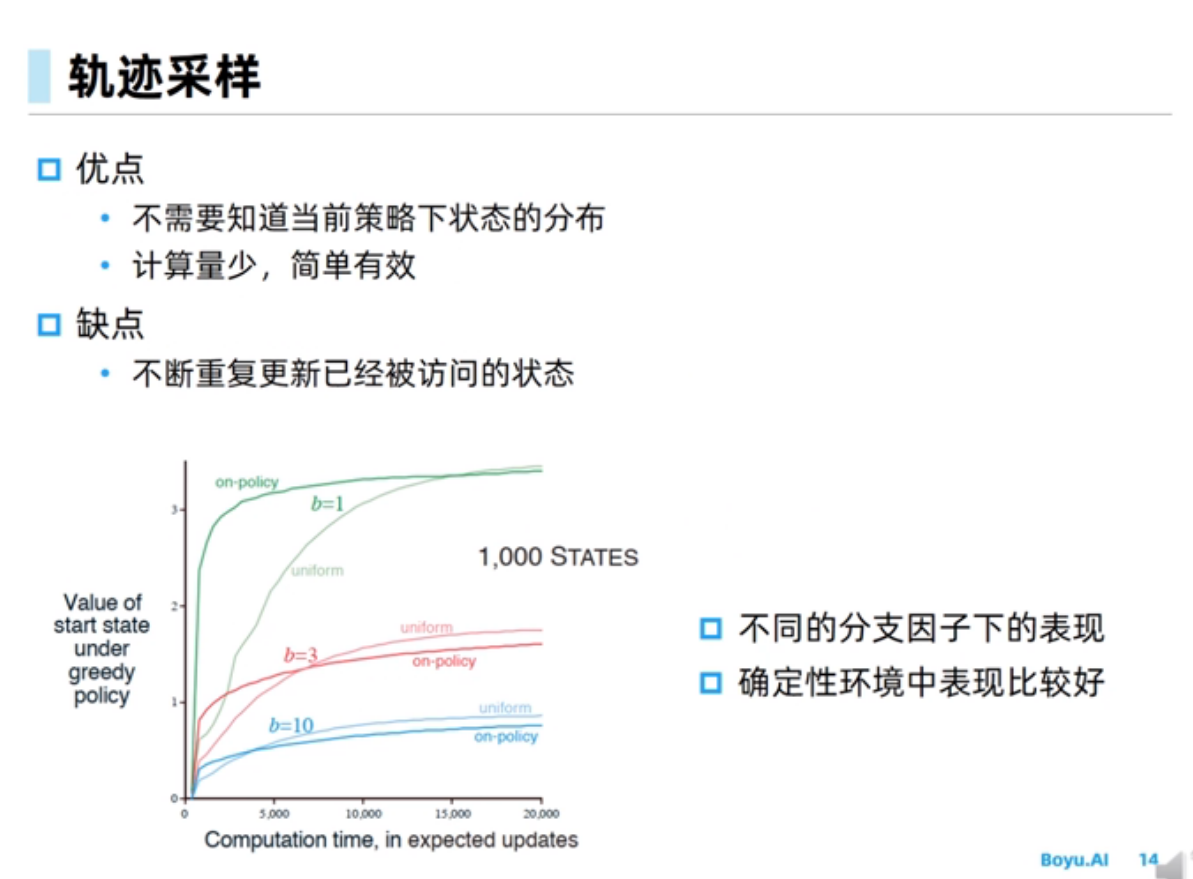
采样方法



此处策略变为随机


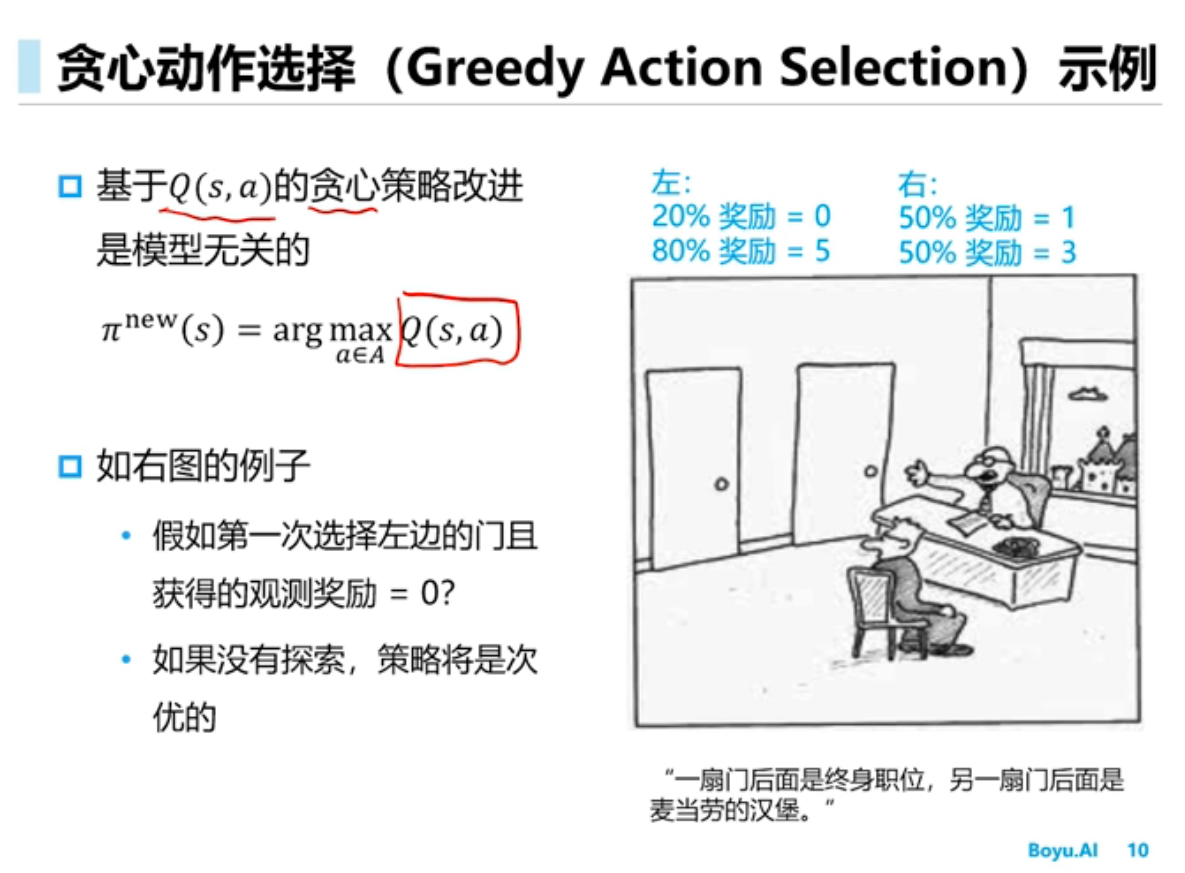
模型无关控制方法






$\epsilon$-贪心策略探索中,以$\epsilon$概率随机选择一个动作,而以$1 - \epsilon$的概率选择贪心动作



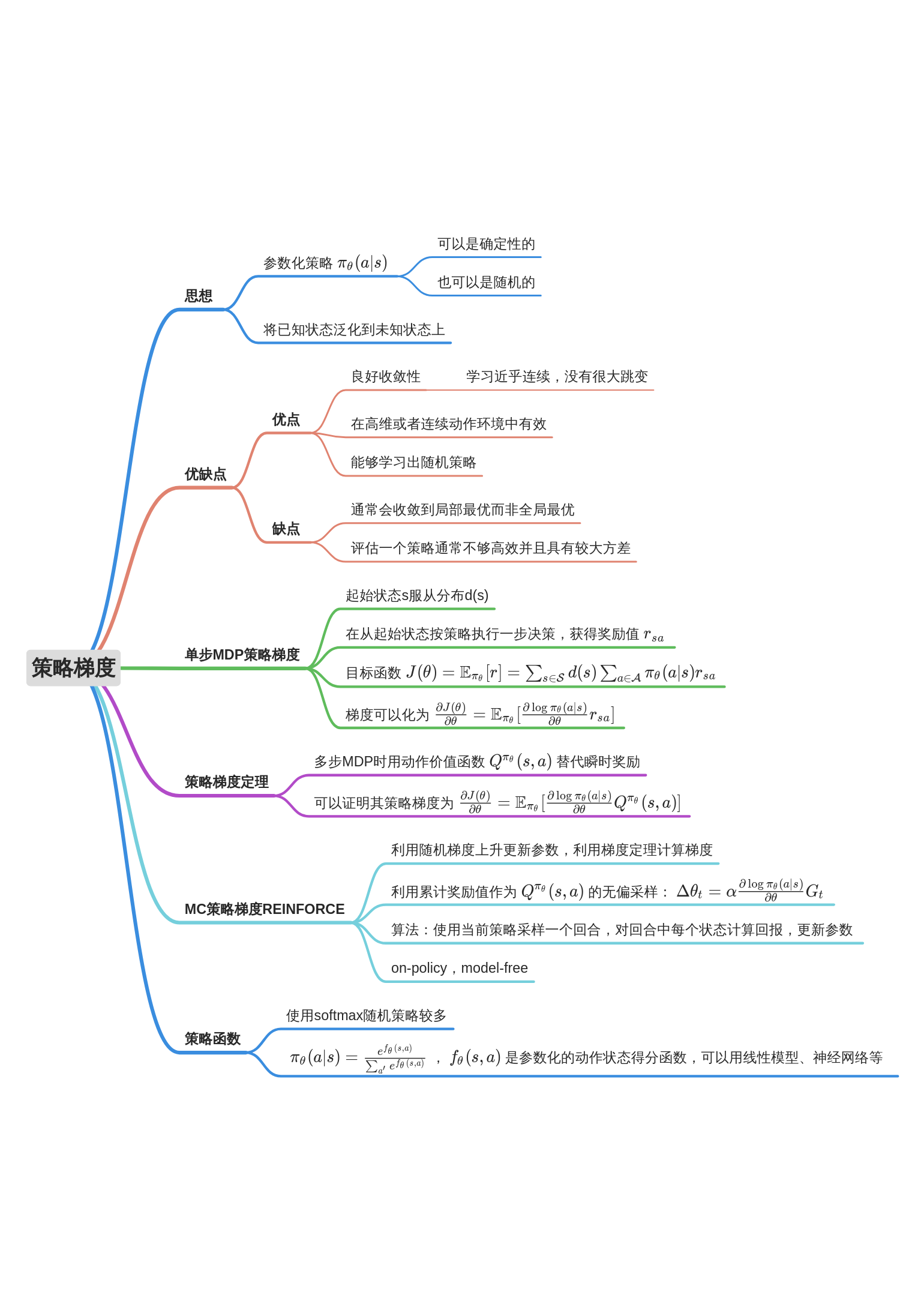
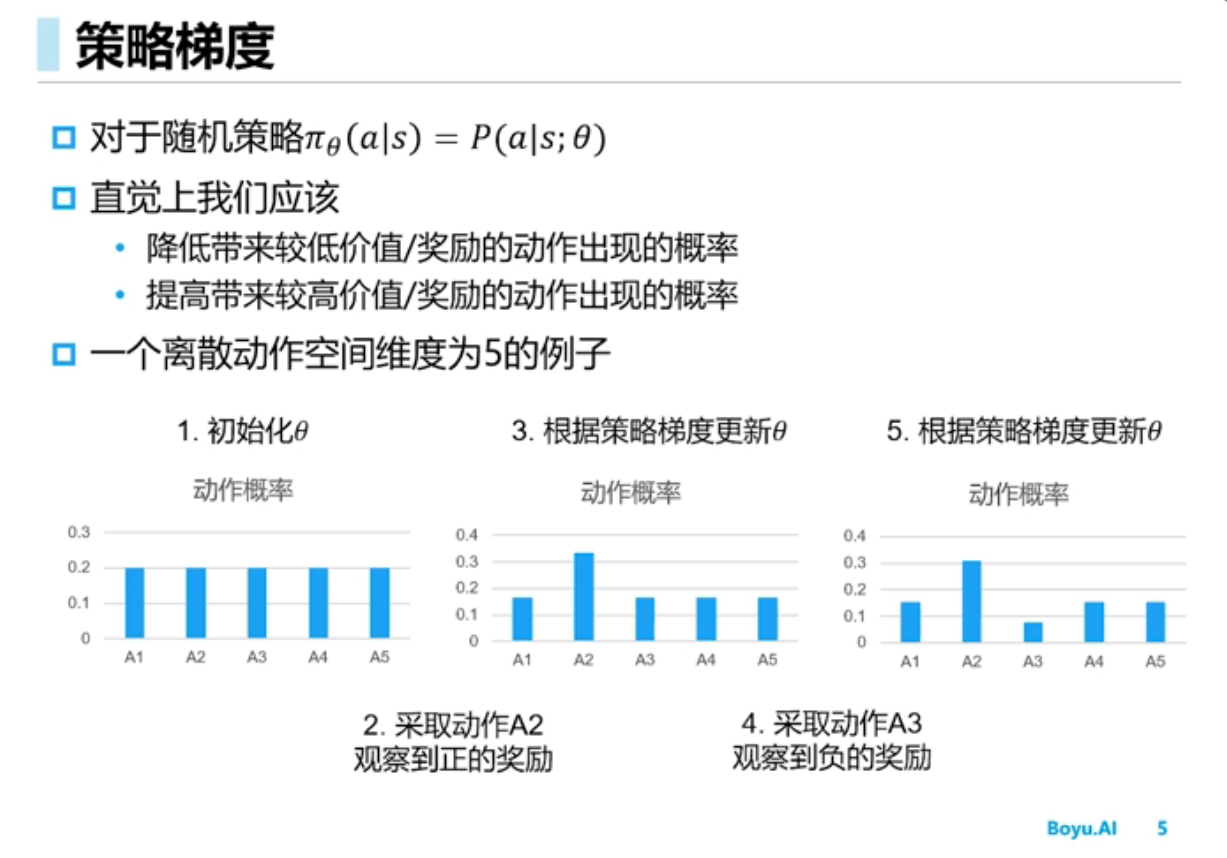
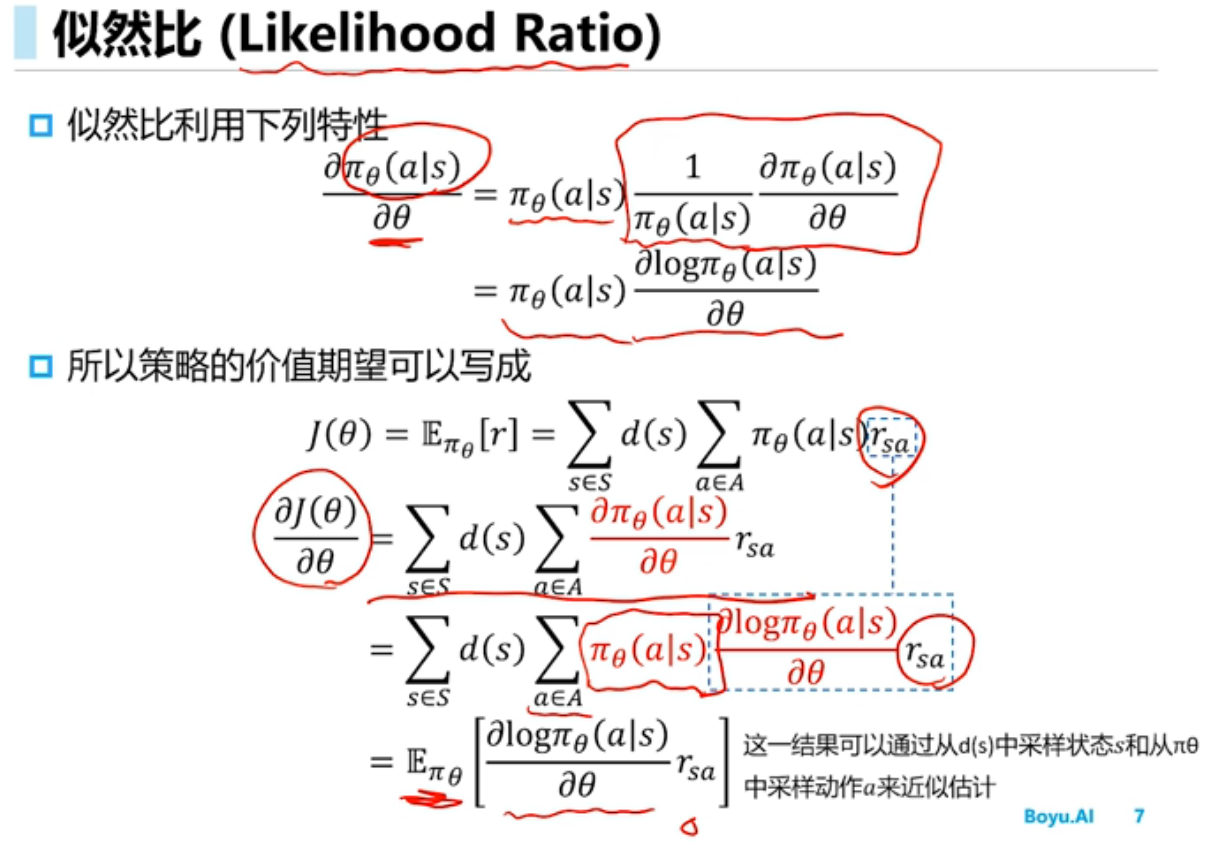
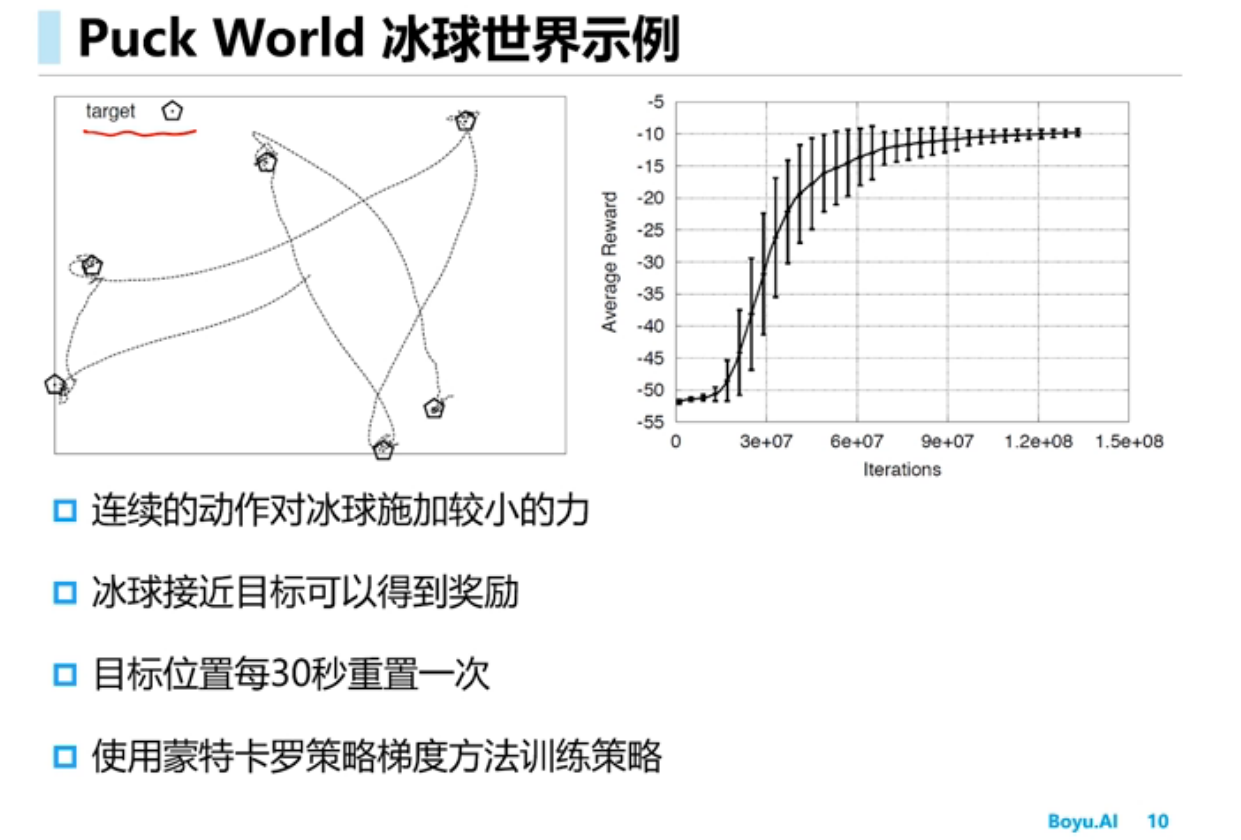
策略梯度(Policy Gradient)
很好的参考文献




小trick




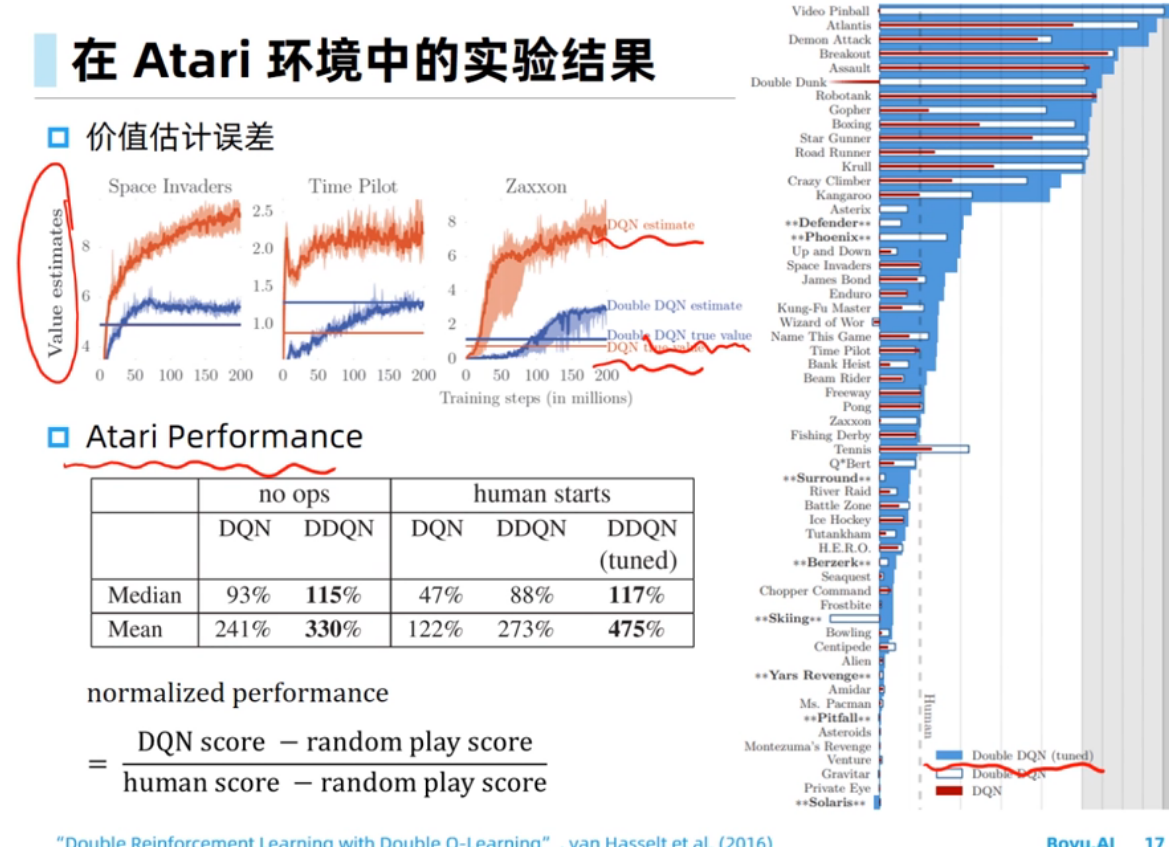
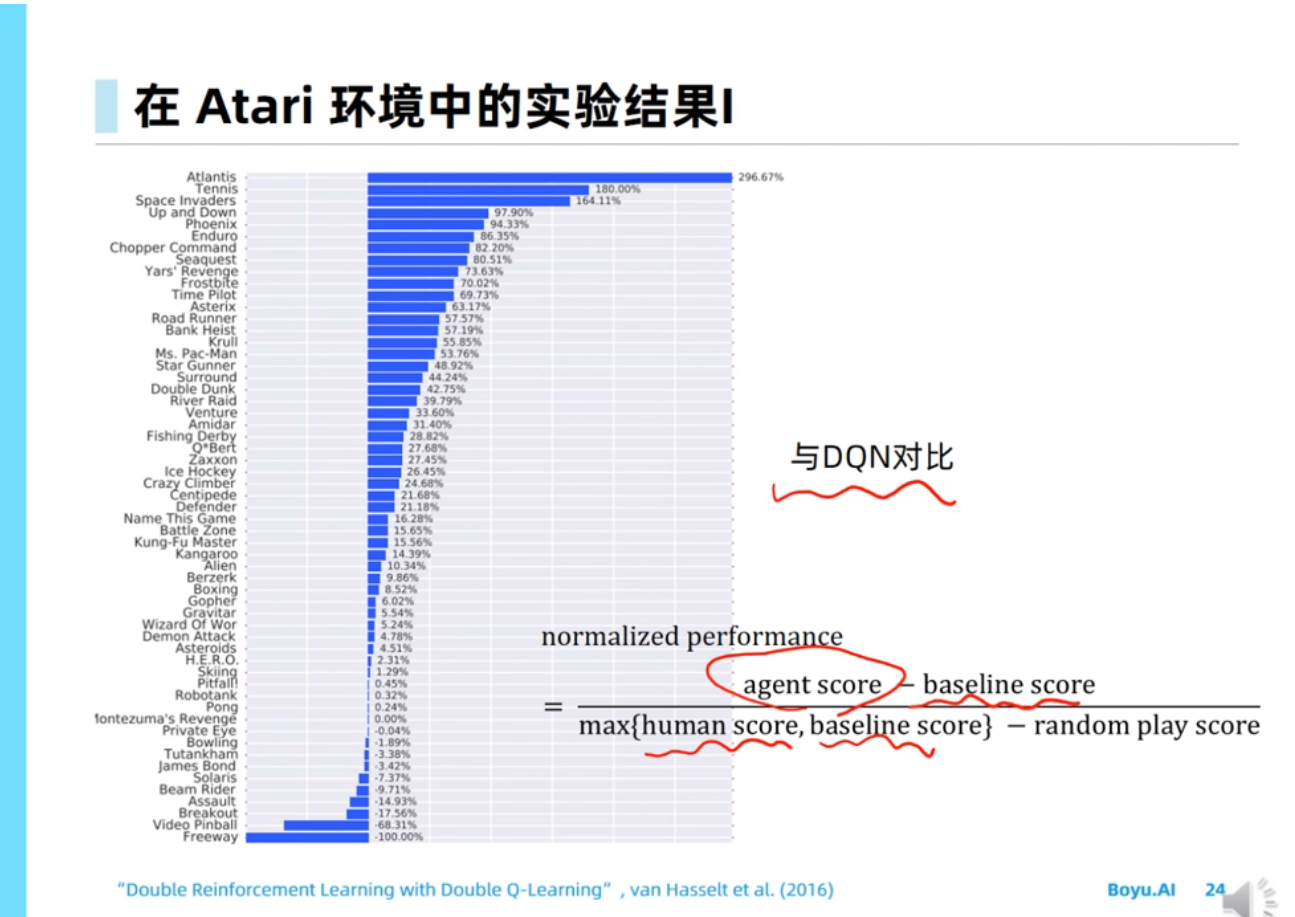
深度Q网络
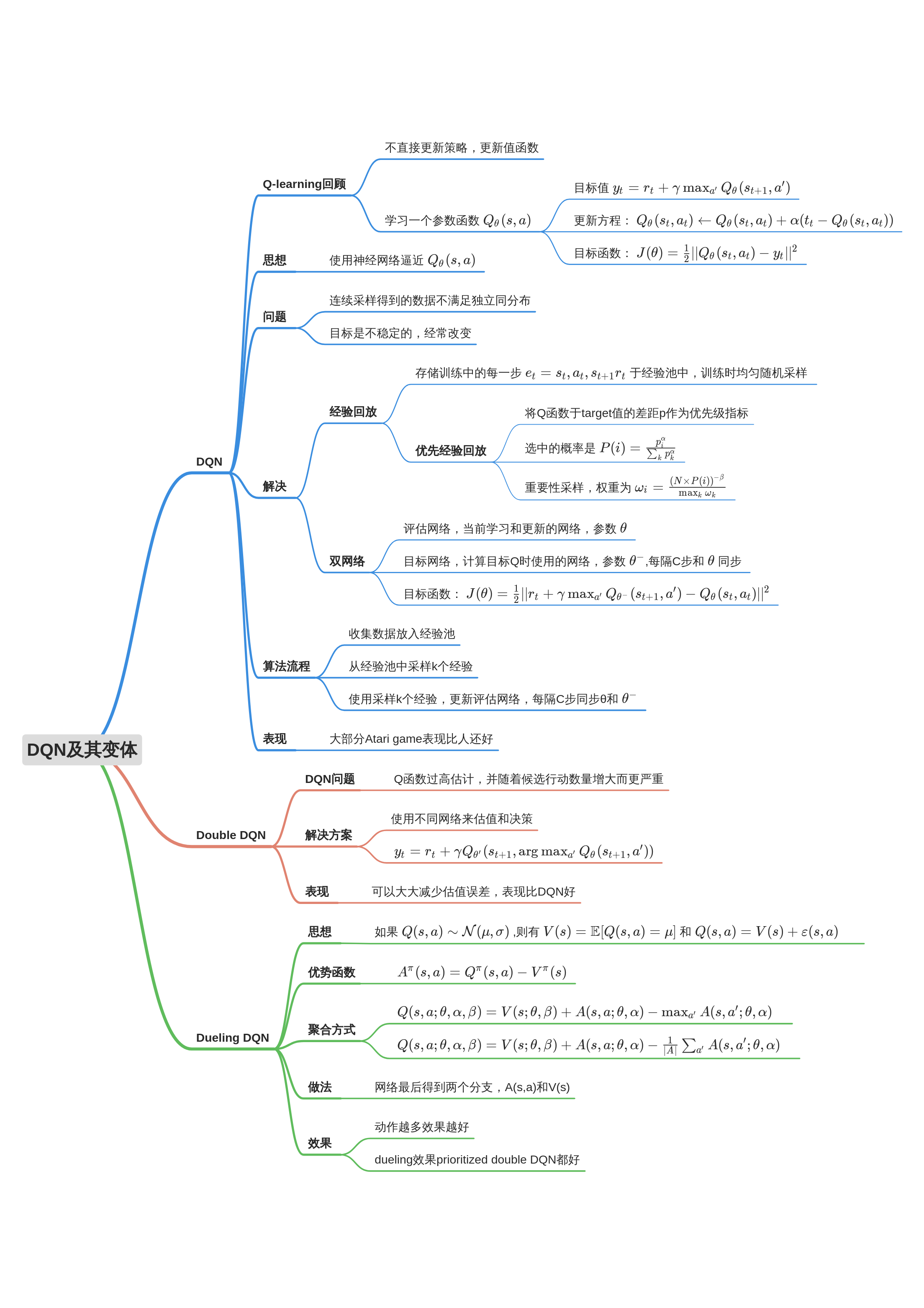



原本的DQN中是根据均匀分布采样数据,而优先经验回放机制根据p_t的大小来采样,就会带来data bias的问题;于是引入重要性采样就是先以每个样本p_t的大小确定选择样本的概率,再在更新Q的学习率上把采样到这个样本的概率除回去,这样就能把采样到数据的分布修改为原来的均匀分布。


双网络结构指的是使用评估网络和目标网络,其目的是缓解拟合的Q函数的频繁更新。
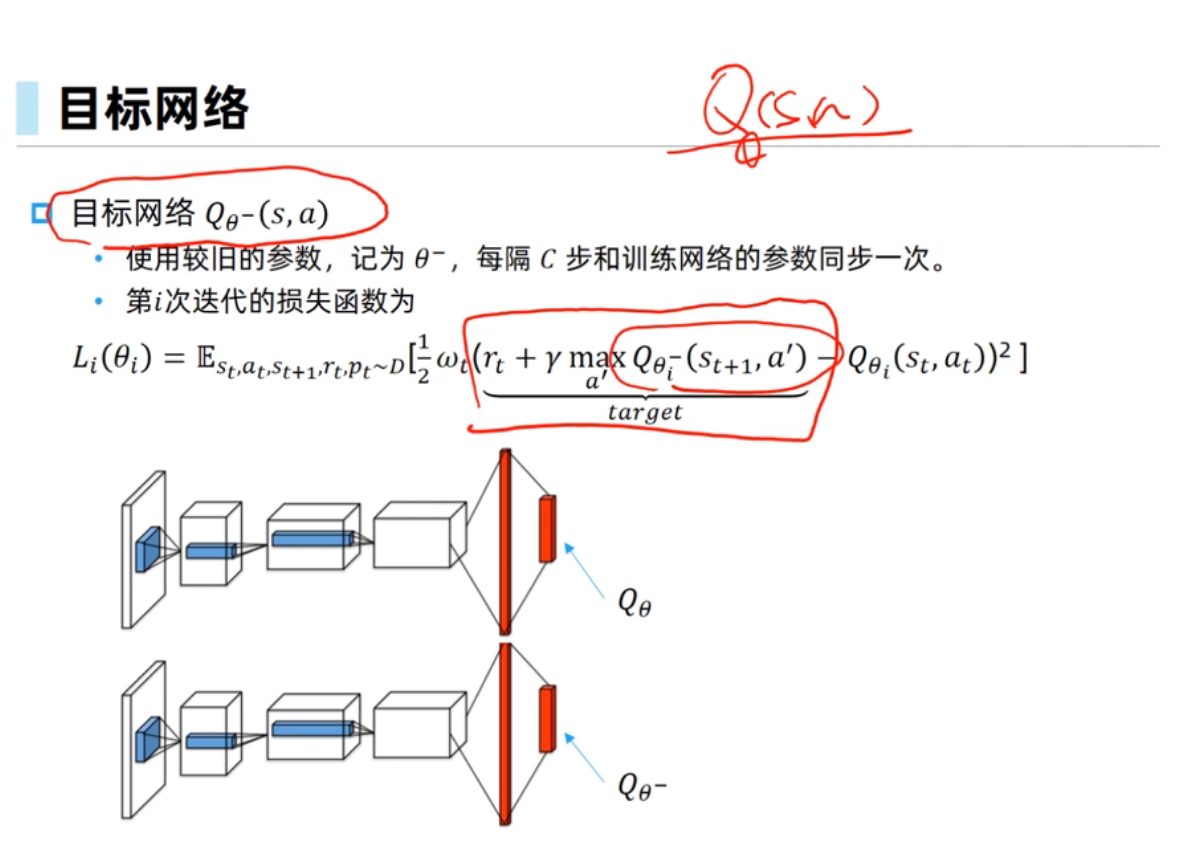


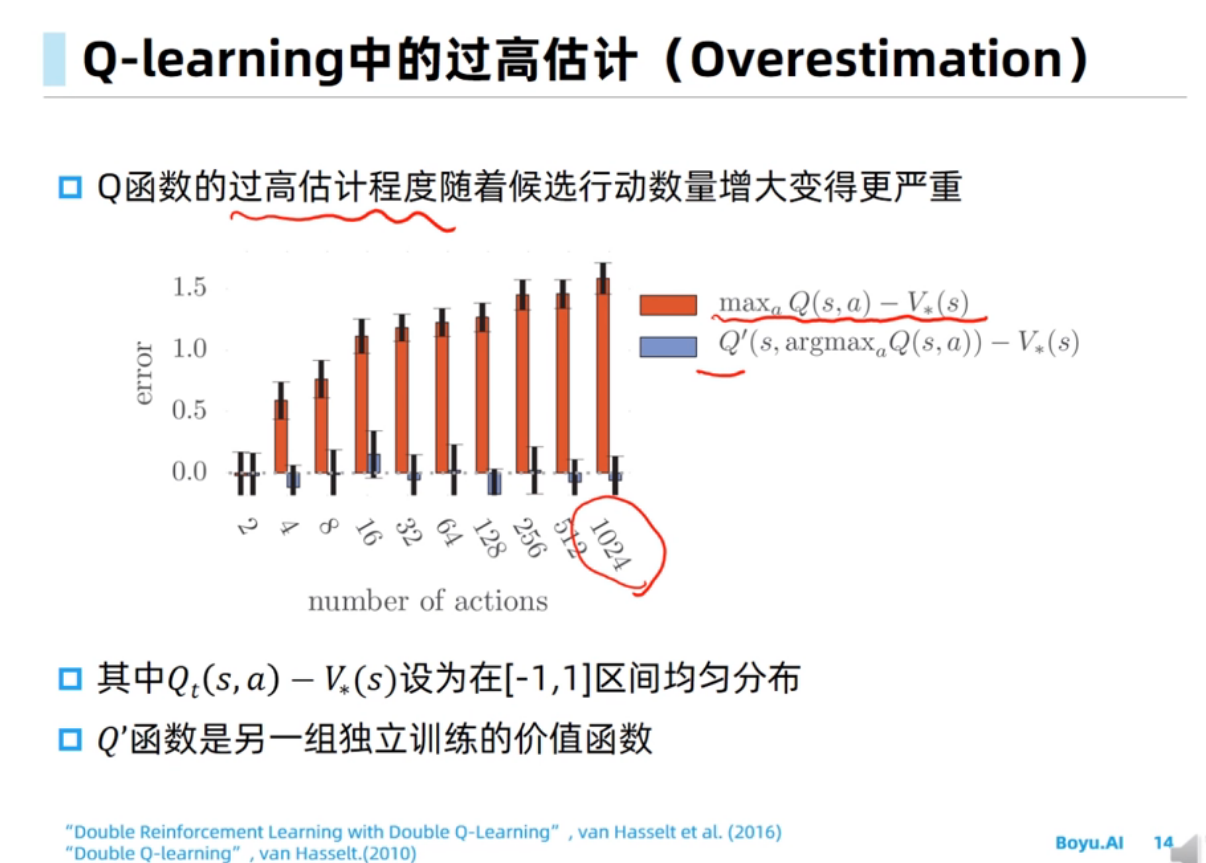
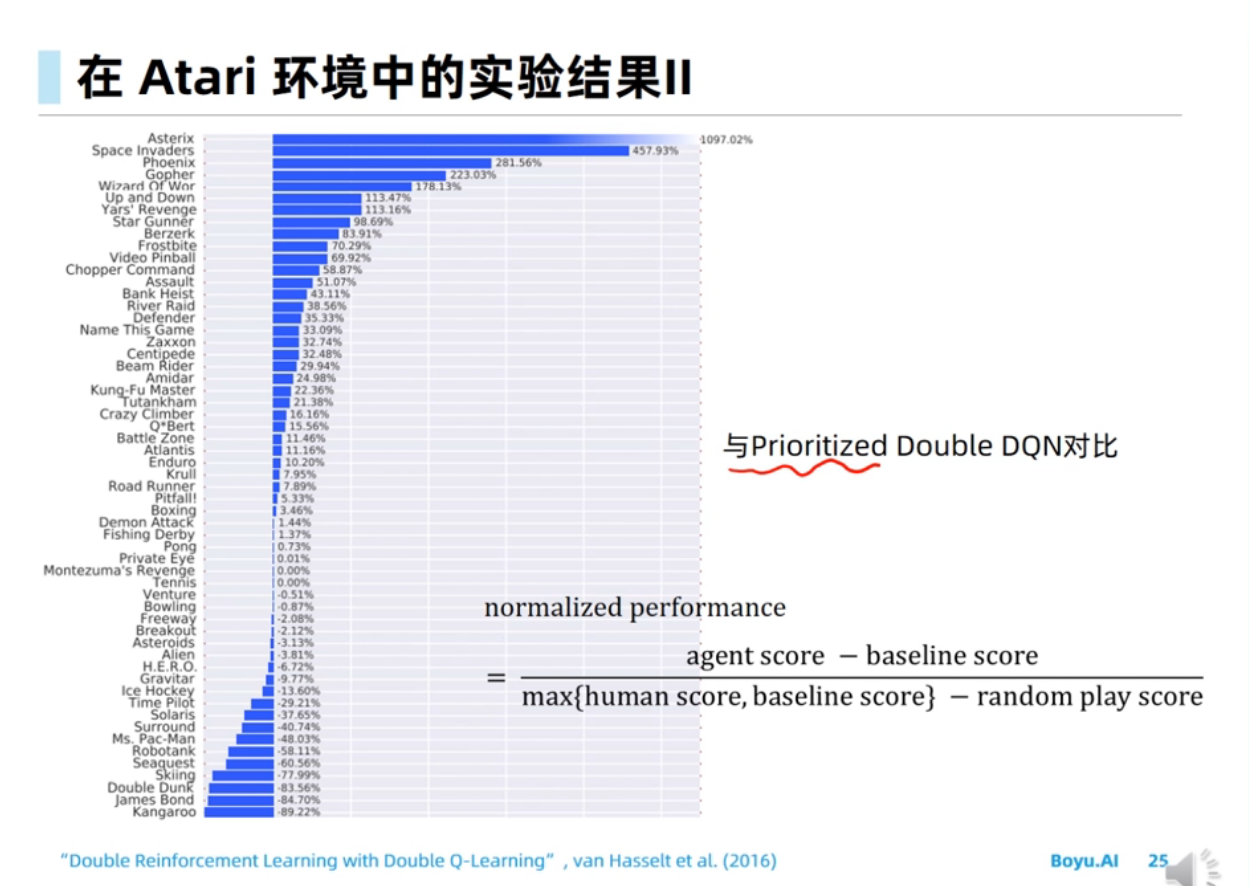
过估计问题是由Target值计算中的maxmax操作导致的。

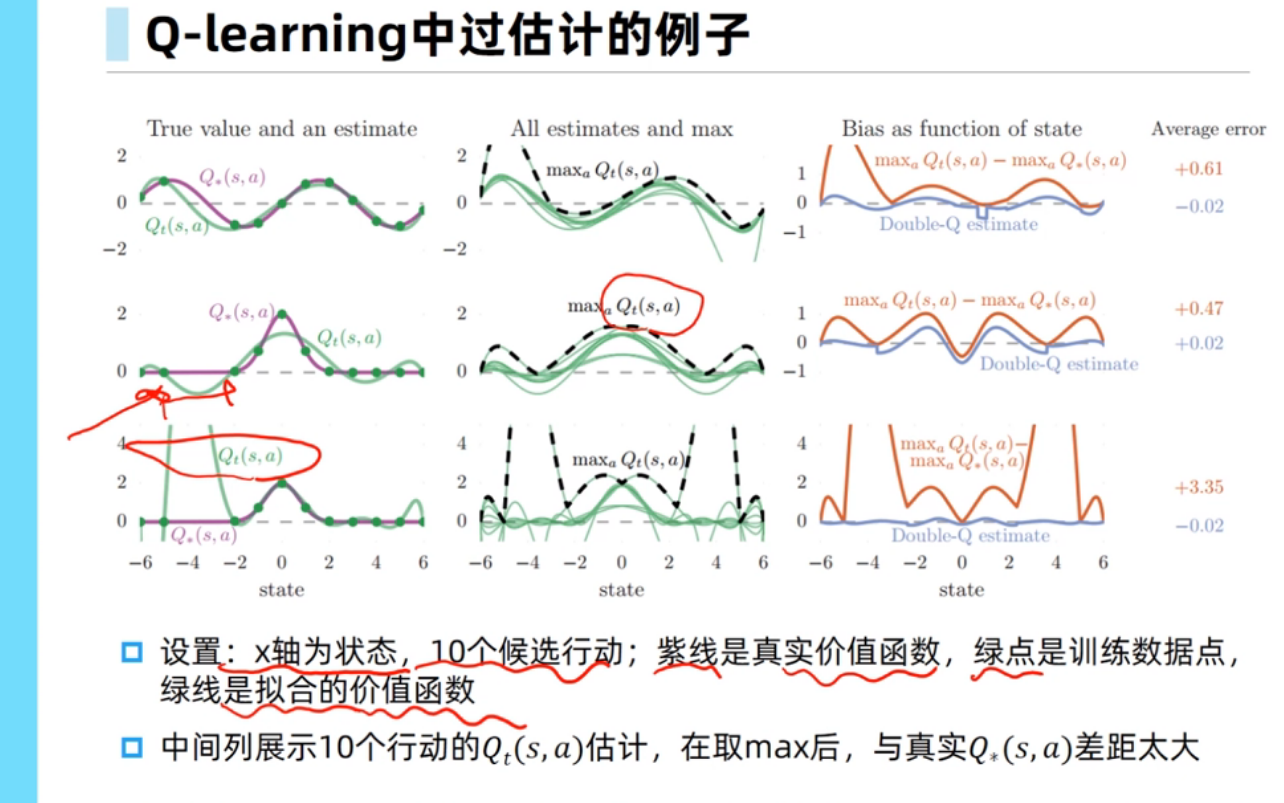

 、
、
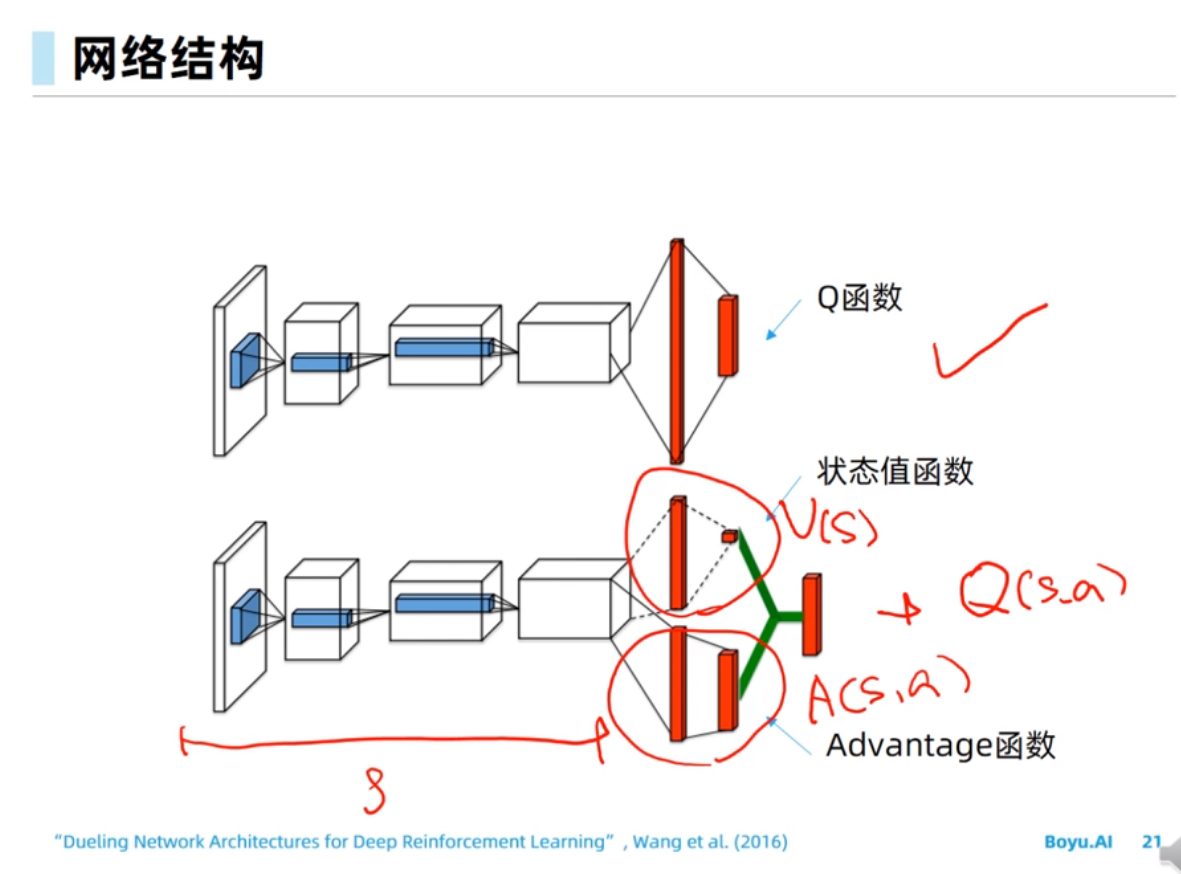
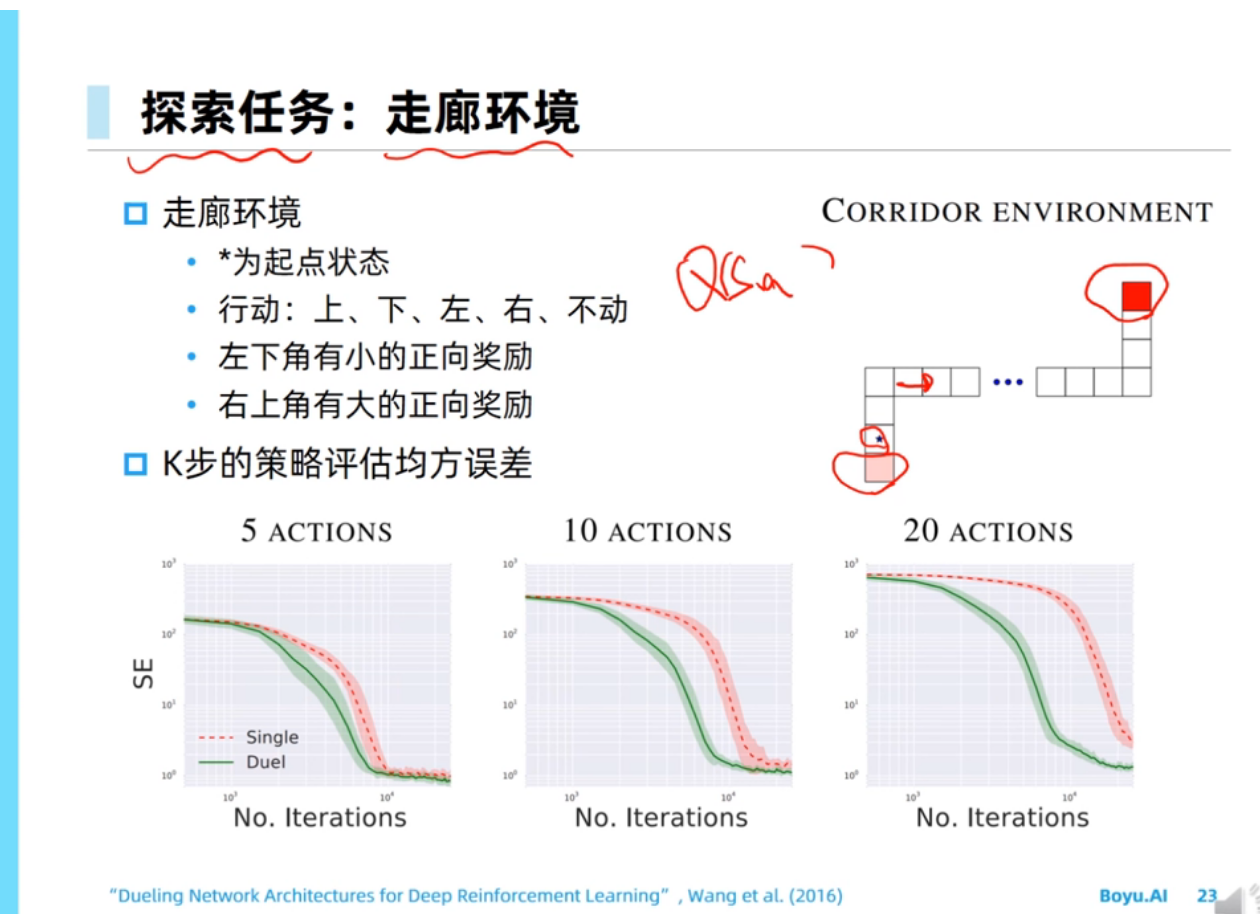
dueling dqn能够通过advantage函数把方向感建模出来,这句话我不是非常理解。在我看来,单纯的Q(s,a)也是能够建模出方向感的,因为不同action对应的q函数的差值和advantage函数的差值应该是一样的?
首先,当reward都是正数的时候,Q(s,a)也肯定只会是正数,也就是都是正向的。
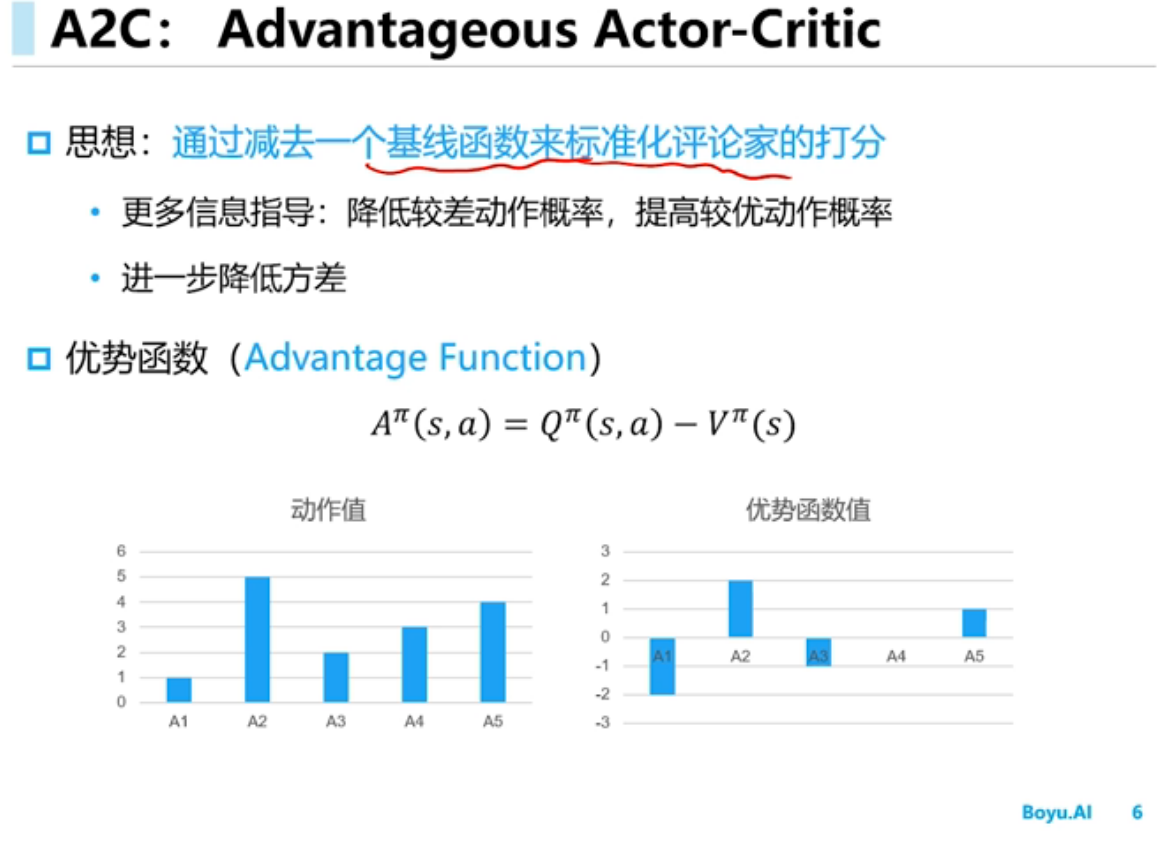
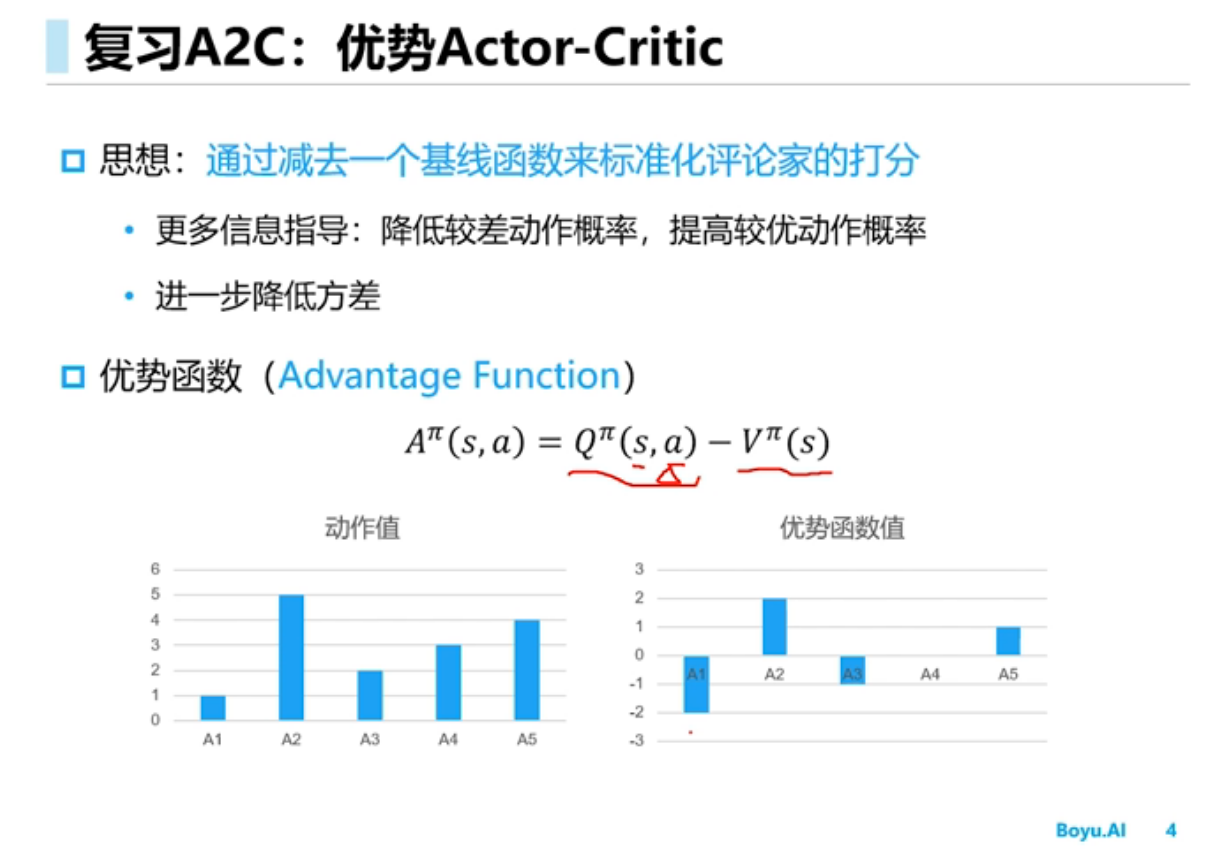
Advantage函数重点在建模 Q(s,a) 相对于 V(s) (或者其他baseline function)的residual,它的学习目标就是那个residual。当residual比较小而V Q值比较大的时候,直接学Q(s,a)就不容易捕捉到这些微小的residual信号从而使得Q网络估计不精确。而Q(s,a) = V(s) + A(s,a),所以argmax_a Q(s,a) 其实就是 argmax_a A(s,a),所以对residual的学习至关重要。
对Q的建模不如A有方向感,这其实更加体现在policy gradient(actor critic)上面。在上述reward总是正数的情况下,Q(s,a)都是正数,所以policy gradient时,每个action其实都是加分的,最后被softmax给normalize一下。这时就好比action们在赛跑,谁跑的更快,谁接下来的pi(a|s)概率就越大。而对A(s,a)建模,即使在上述reward总是正数的情况下,也各有正负,这时A(s,a)为负数的就对应着pi(a|s)的概率下降,为正数的对应着概率上升,就很合理,对学习算法很友好。



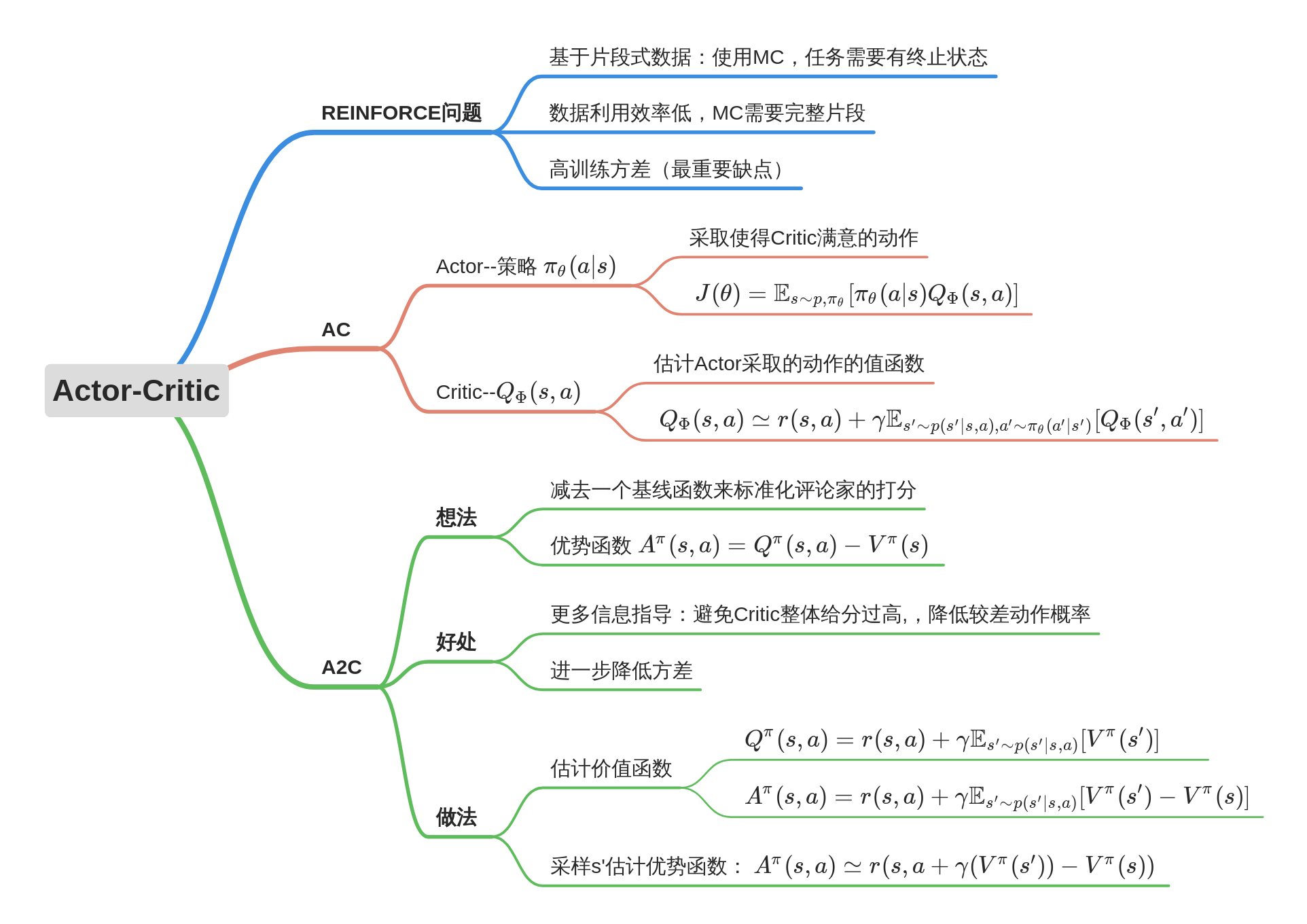
Actor-Critic方法
在PG算法中,计算Q(s,a)可以用REINFORE算法,也可以用AC算法





重要性采样
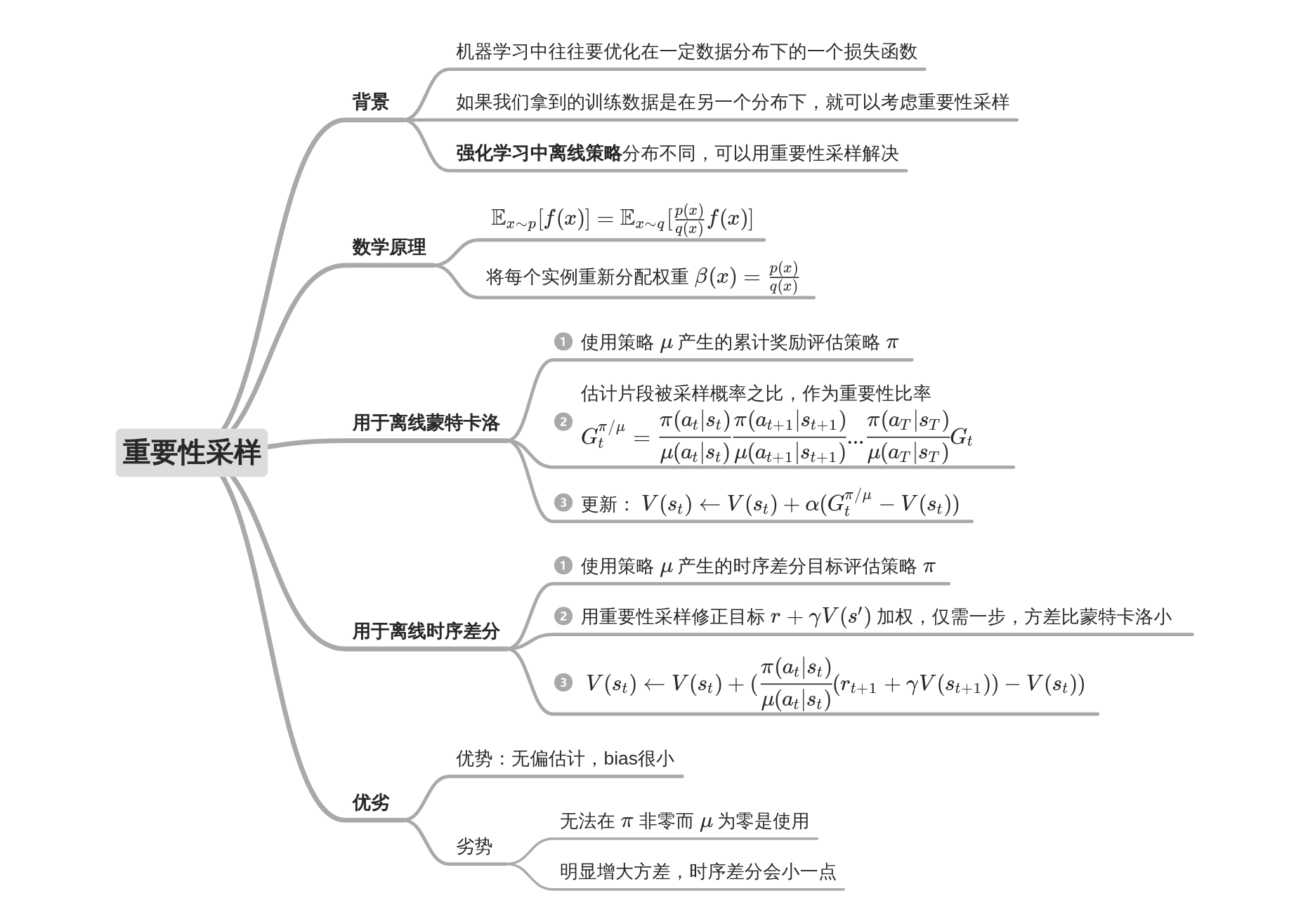
TRPO(PPO同理)的objective给出过程中也用到了importance sampling的思想,可以参考TRPO论文。但它们的确是on-policy算法。
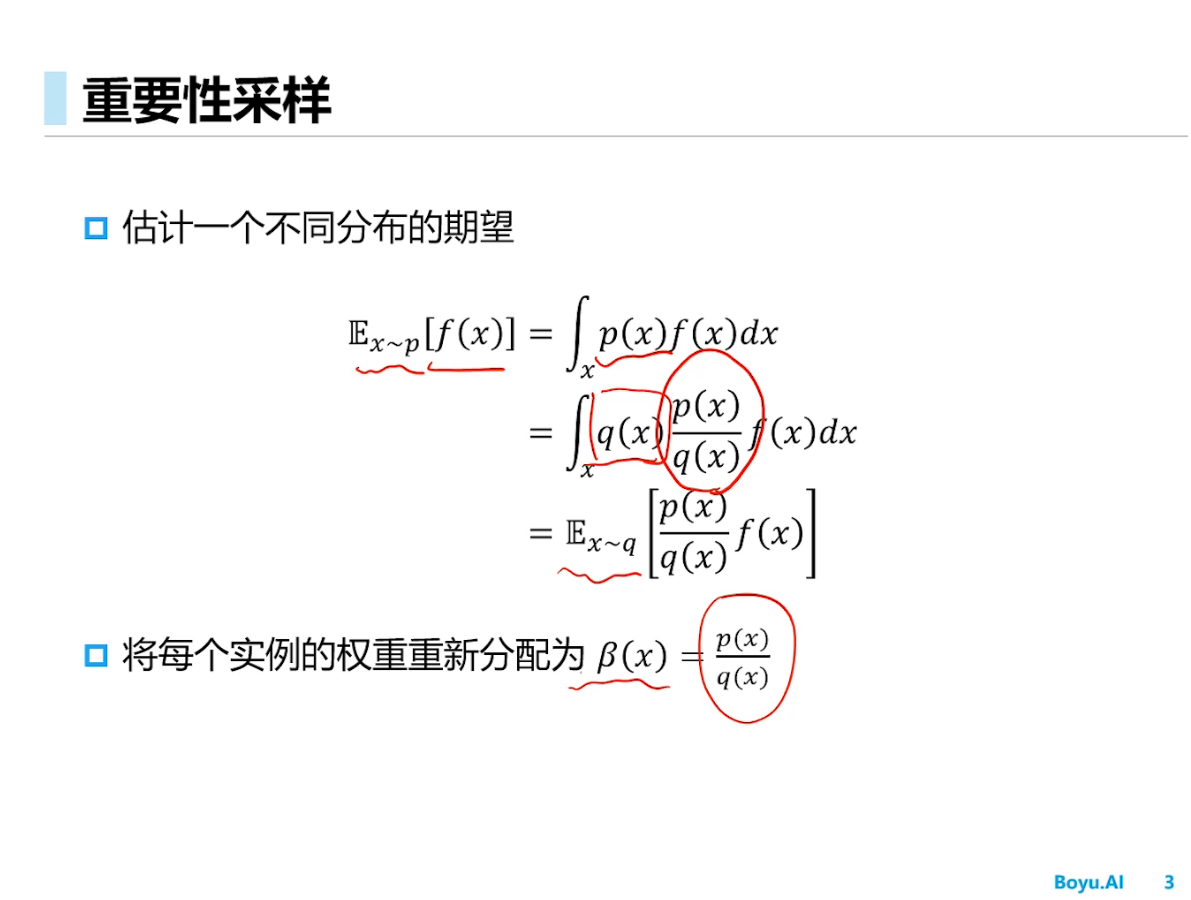

无偏估计,但是方差可能会出现很大的情况


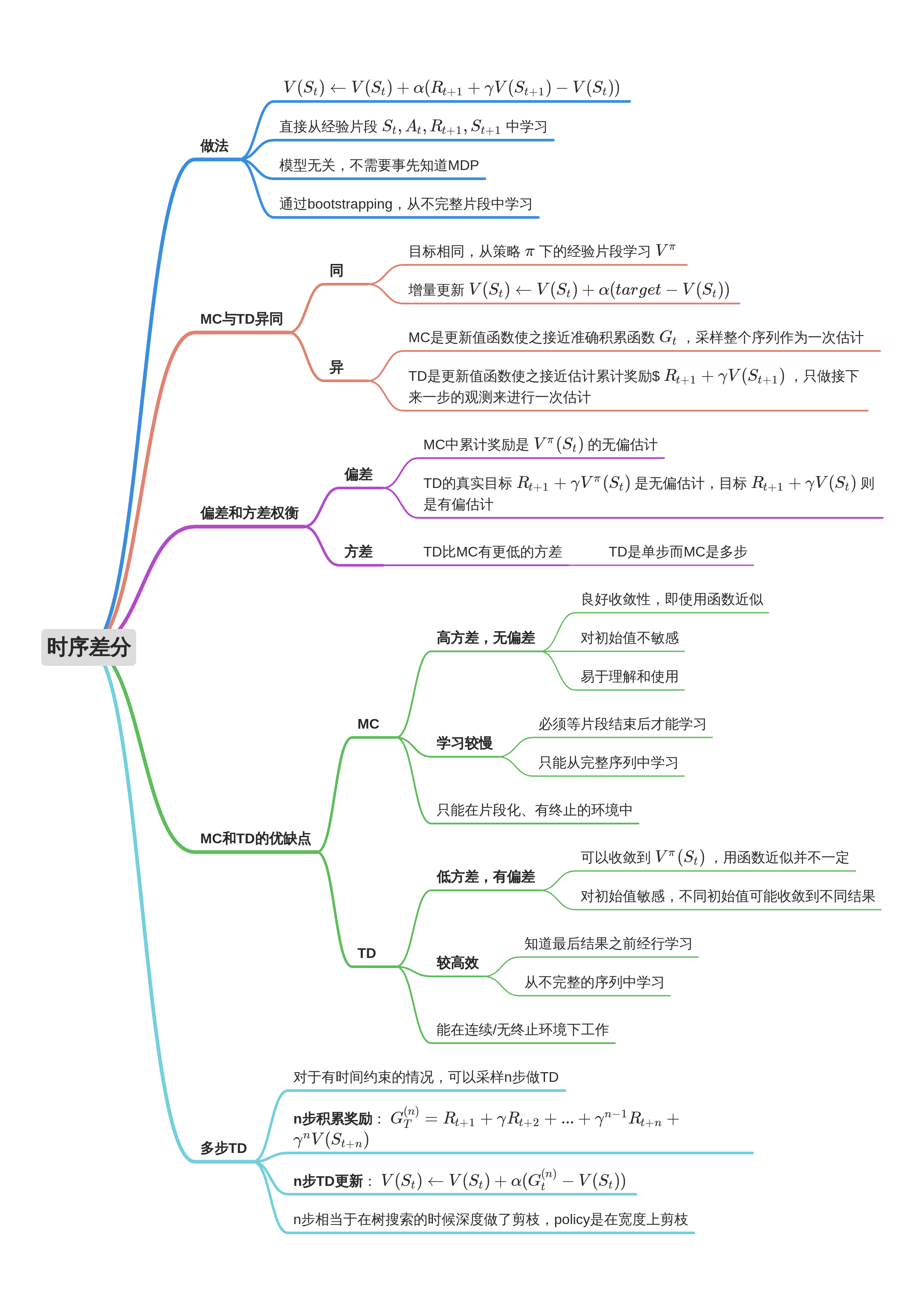
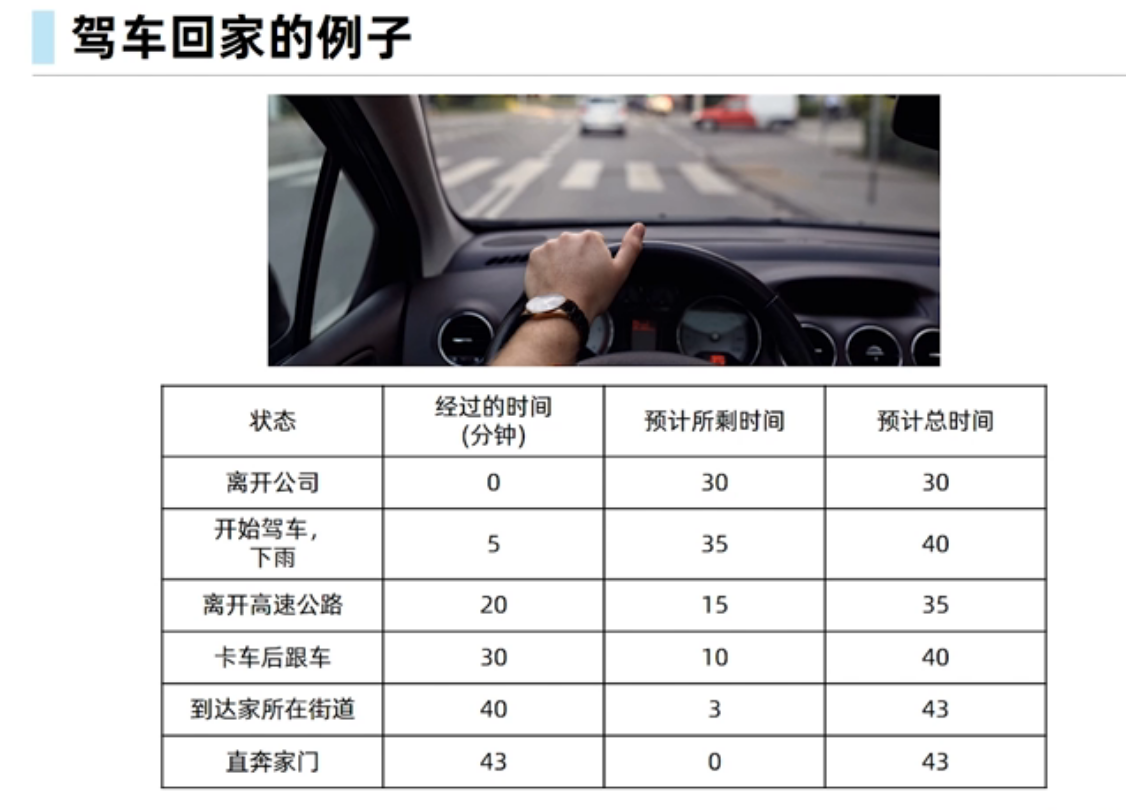
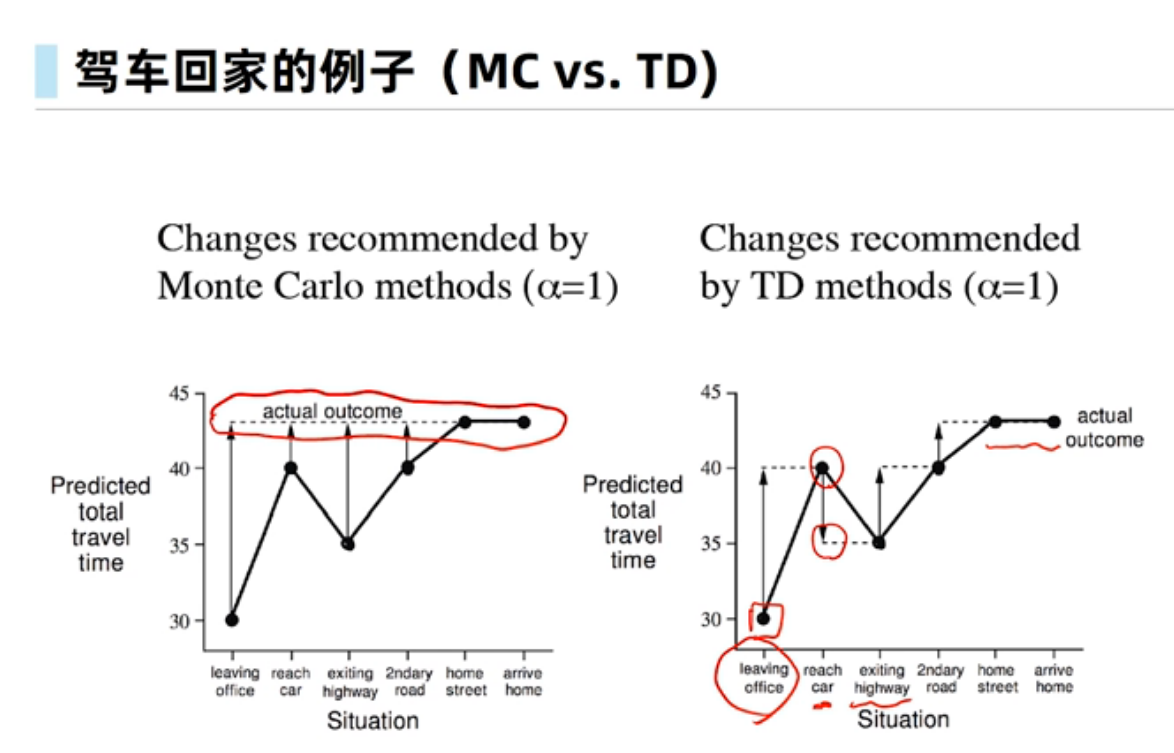
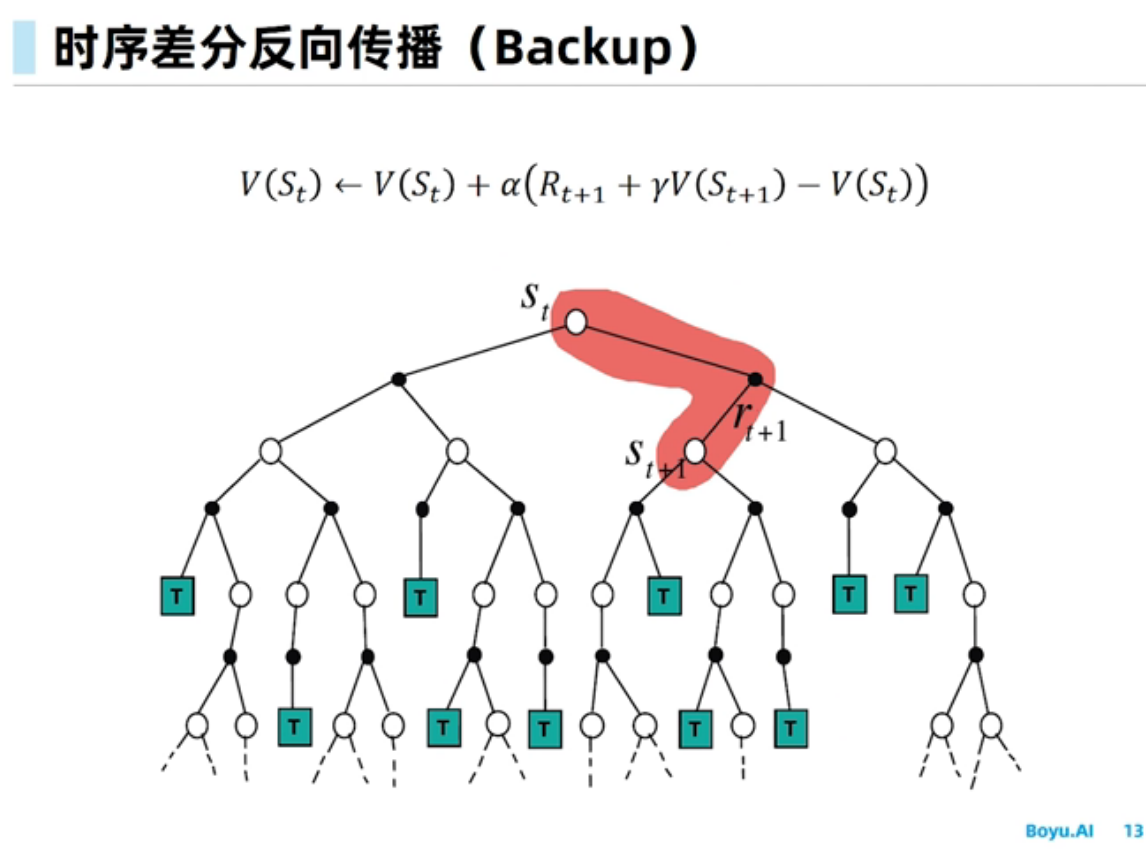
时序差分学习





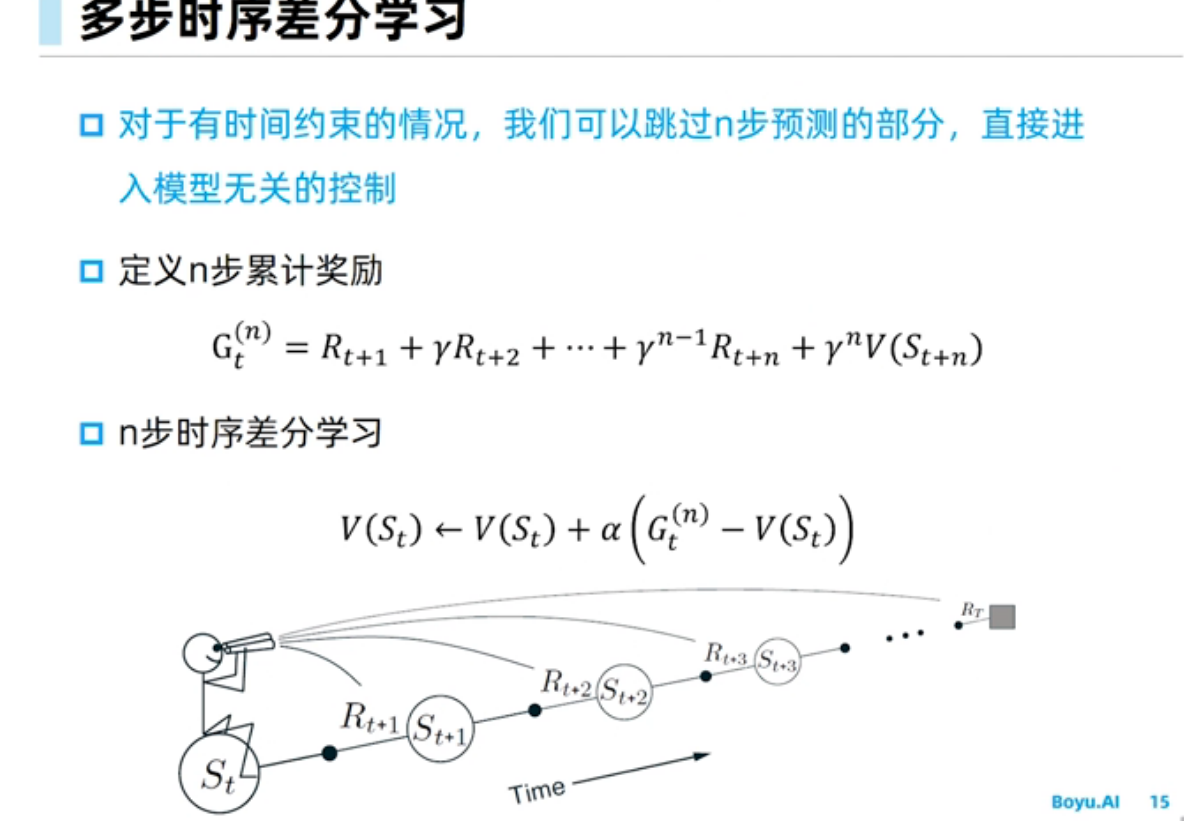
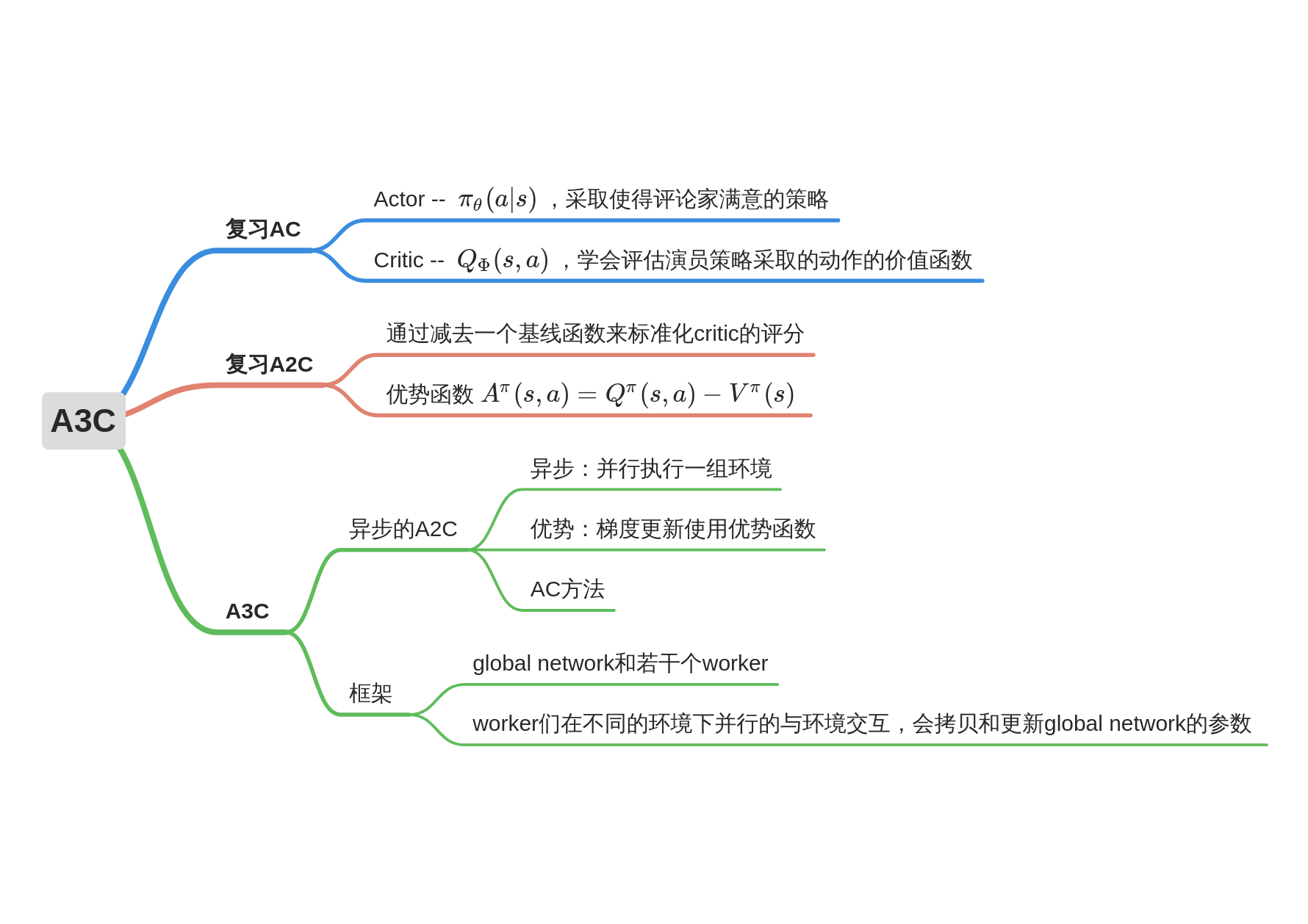
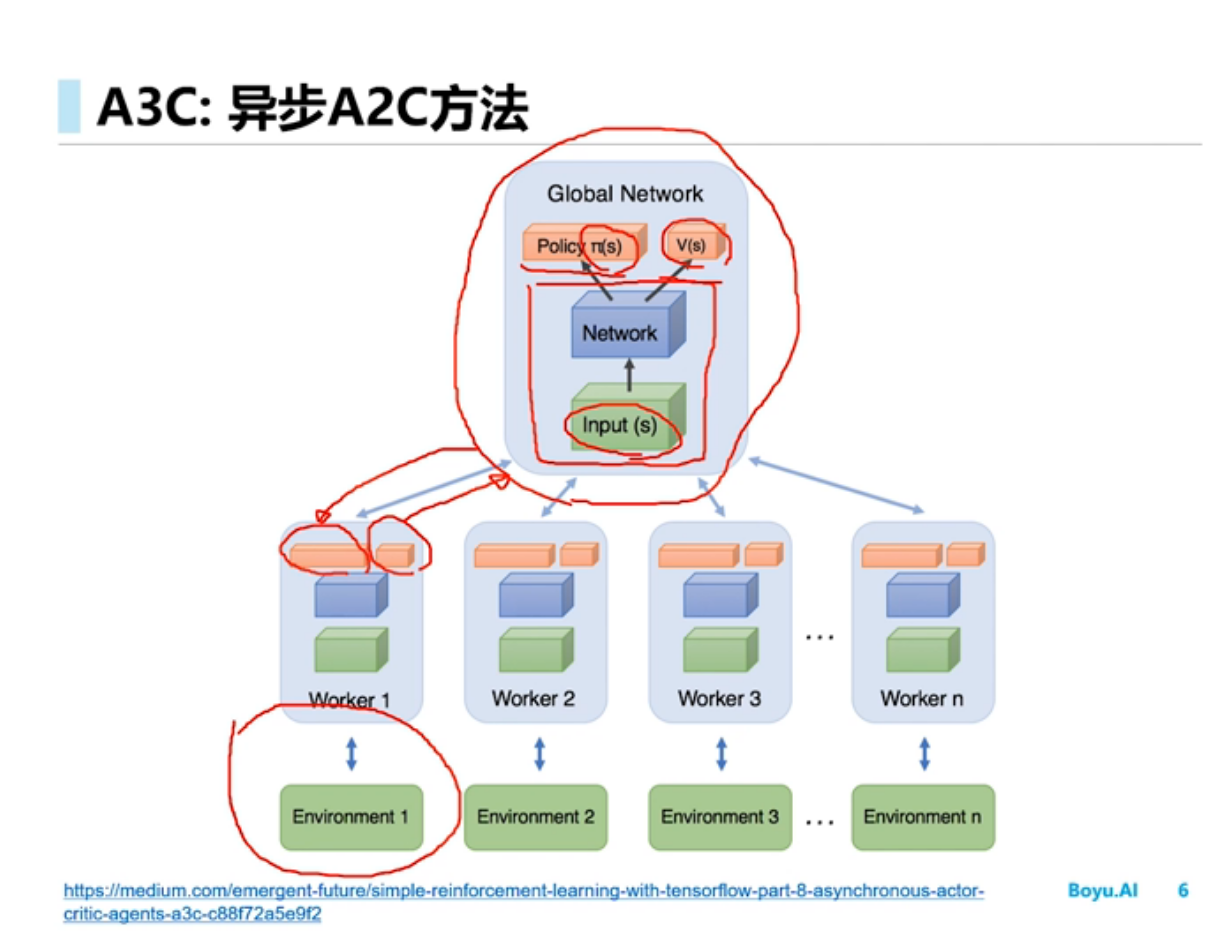
A3C
A3C的创新和厉害之处在于:A3C算法为了提升训练速度采用异步训练的思想,利用多个线程。每个线程相当于一个智能体在随机探索,多个智能体共同探索,并行计算策略梯度,对参数进行更新。或者说同时启动多个训练环境,同时进行采样,并直接使用采集的样本进行训练,这里的异步得到数据,相比DQN算法,A3C算法不需要使用经验池来存储历史样本并随机抽取训练来打乱数据相关性,节约了存储空间,并且采用异步训练,大大加倍了数据的采样速度,也因此提升了训练速度。与此同时,采用多个不同训练环境采集样本,样本的分布更加均匀,更有利于神经网络的训练。



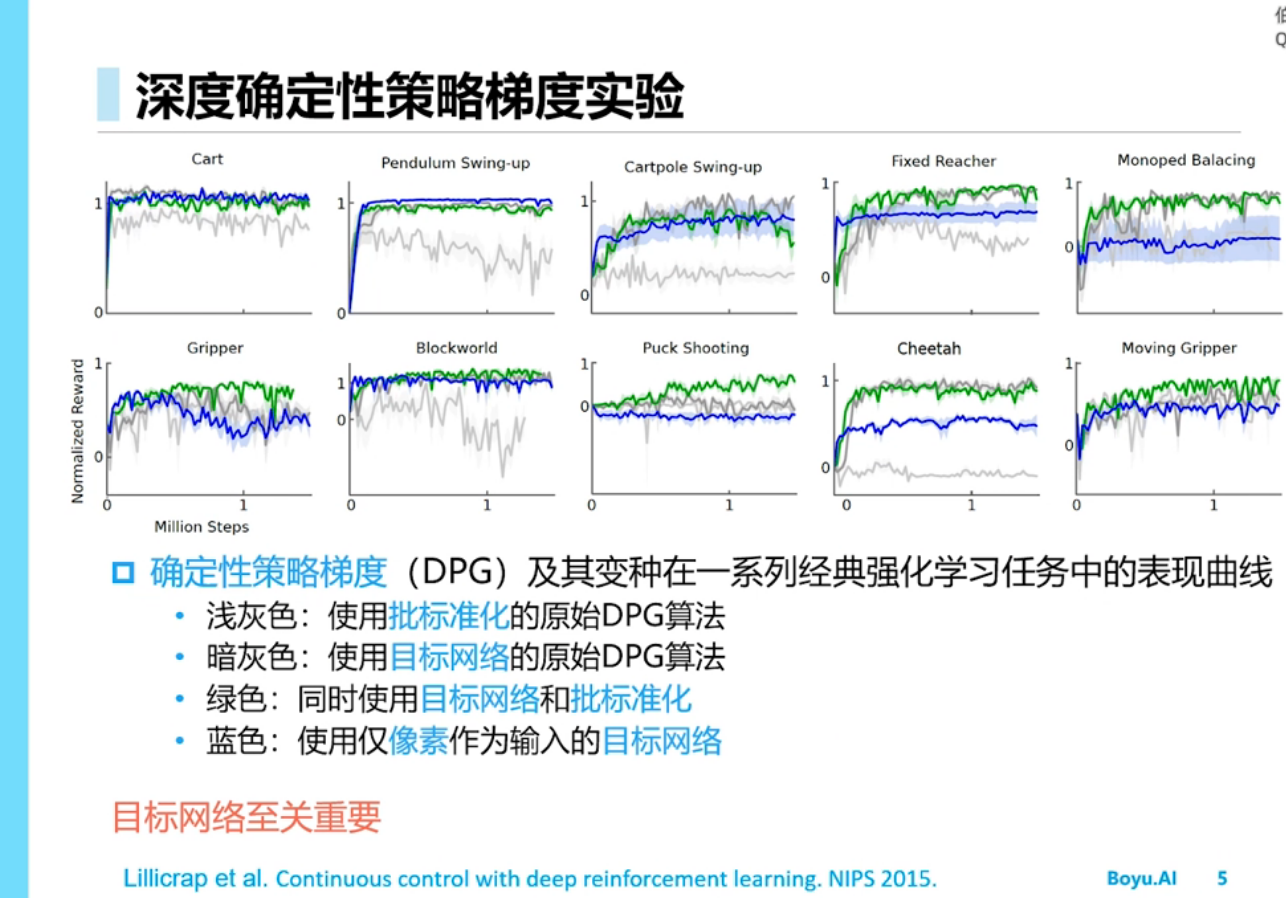
确定性策略梯度(DPG)



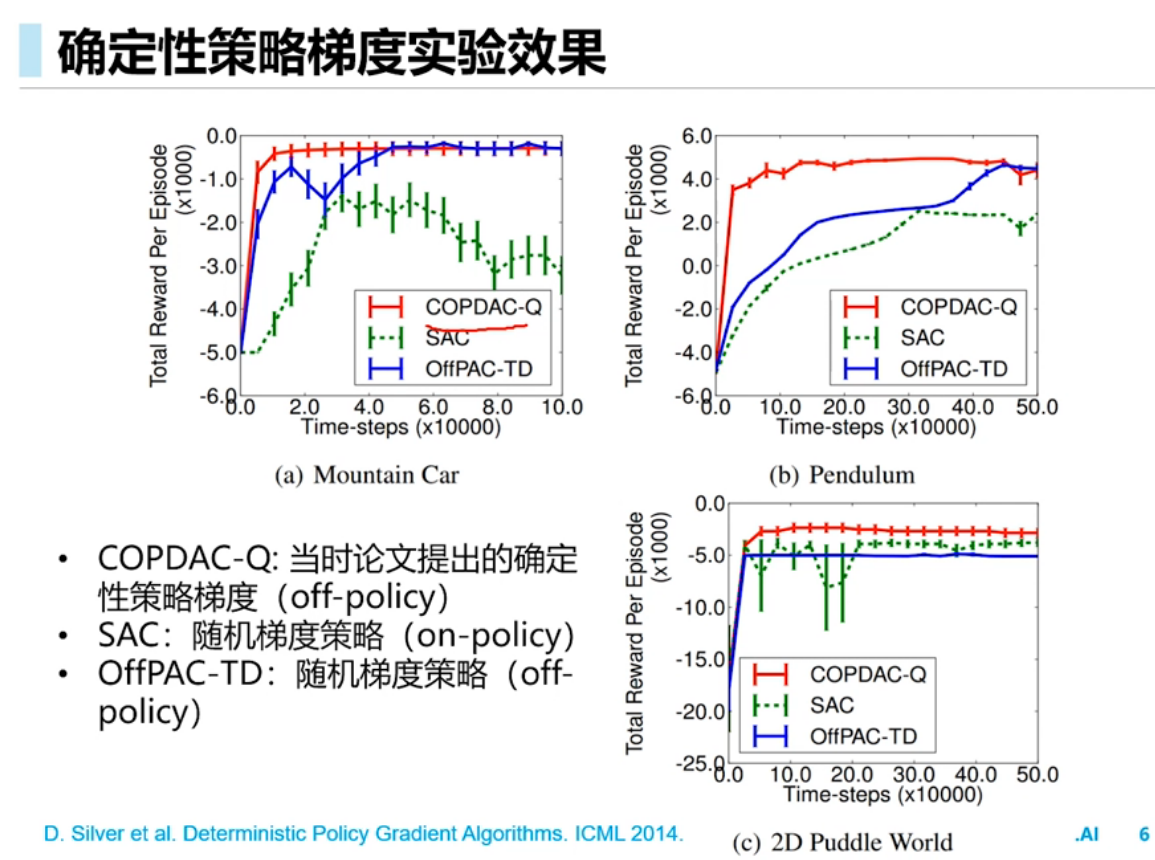
深度确定性策略梯度(DDPG)



信任区域策略优化TRPO
TRPO(以及PPO)算法都是on-policy的算法。On-policy是指,采样使用的policy就是要更新的policy。在TRPO中,用来更新policy的样本都是由当前policy生成的,更新完就丢弃了,所以是on policy的。TRPO的思想是通过局部优化一个近似$\R(\pi)$的下界函数,从而保证每次策略的改进并最终得到最优策略。
策略梯度算法回顾

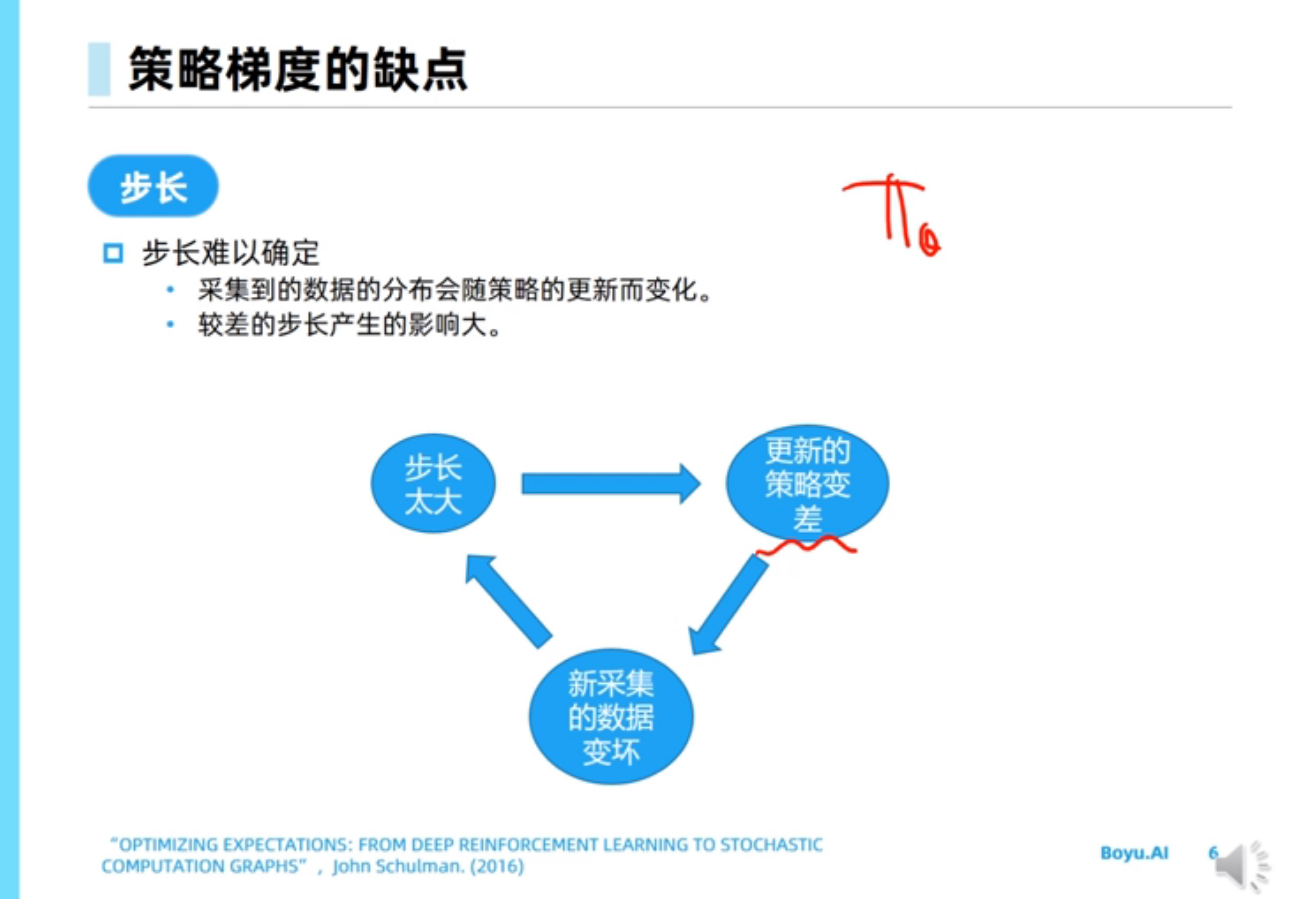
策略梯度算法的缺点
TRPO






通过不断改进$L(\theta)-C\cdot KL$,走到其曲线最顶端$\theta’$,然后在从$\theta’$所在横轴坐标处在$J(\theta’)$上构建新的$L(\theta)$,然后不断更新。
这里C是等于where后面的那个值,D_KL表示KL散度。这里相当是是给出$J(\theta’)$的下界,表示我们策略是一直在往好的地方改进的


PPO
PPO算法按照同策略(on policy)模式更新时,每次更新参数$\theta$的目的是在旧参数$\theta_{old}$的$\epsilon$领域中找到尽可能接近最优解的参数,所以每轮更新参数$\theta$时会用同一批数据更新多次,然后赋值给$\theta_{old}$,详见PPO算法论文或本课程的代码实现。
截断式优化目标意在用截断操作达到限制新旧策略的差异程度。





代码实现:
模仿学习
简介

强化学习中的模仿学习和机器学习中的监督学习有什么相同与区别:
强化学习中的模仿学习(Imitation Learning)和机器学习中的监督学习(Supervised Learning)有一些相同点和区别。
相同点:
- 数据驱动:它们都是基于数据的学习方法,需要使用大量的数据样本进行训练。
- 目标导向:它们都有一个明确的目标,即通过学习从输入到输出的映射来实现某种预期的目标。
区别:
- 数据来源不同:监督学习的数据来自于已有的标注数据集,而模仿学习的数据则来自于专家演示的行为轨迹。
- 预测结果不同:监督学习是从输入到输出的映射,即输入数据与输出结果之间的对应关系。而模仿学习是从状态到动作的映射,即给定一个状态,预测出在这个状态下应该采取的动作。
- 应用场景不同:监督学习主要应用于分类和回归等问题,而模仿学习主要应用于控制问题,如机器人控制、自动驾驶等。
- 误差来源不同:监督学习的误差来自于标签与预测值之间的差异,而模仿学习的误差来自于专家演示的行为与模型生成的行为之间的差异。


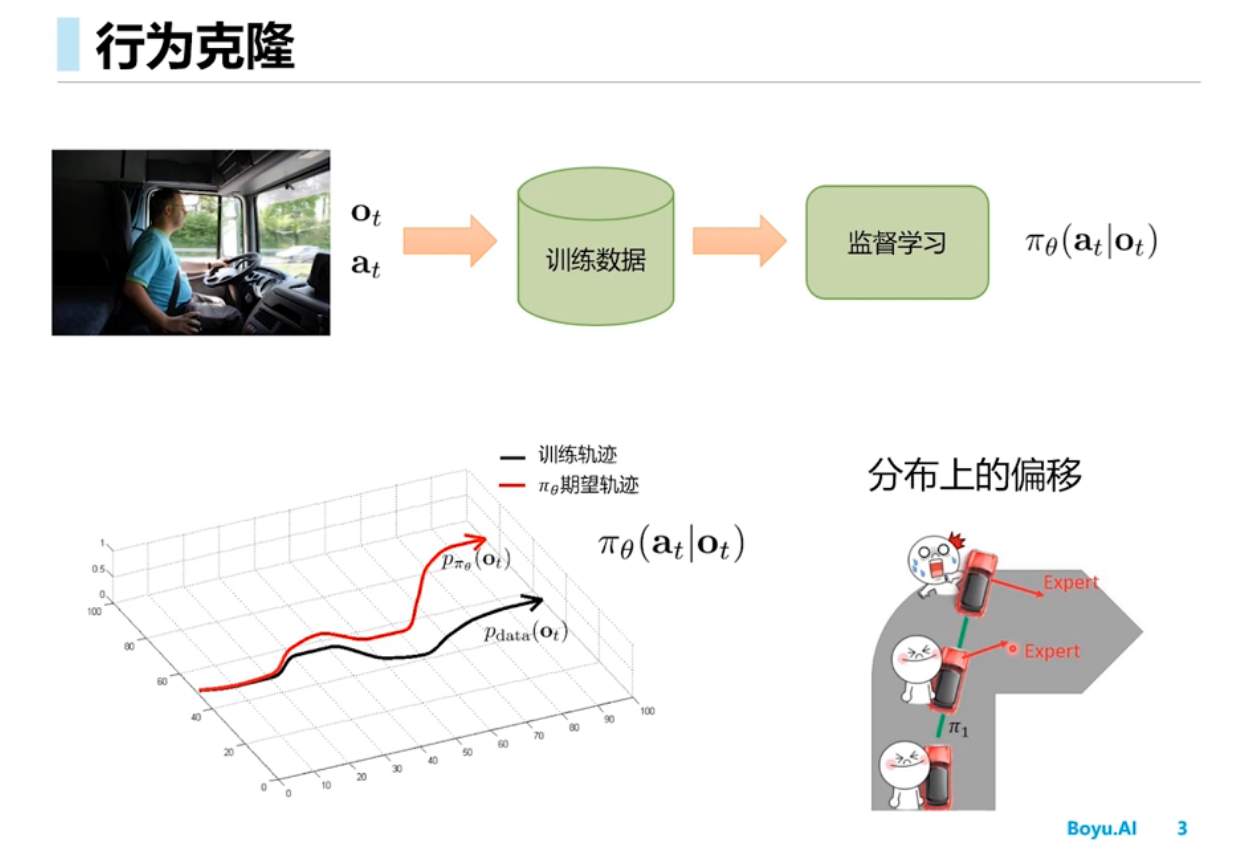
行为克隆
行为克隆可以理解为以状态-动作对为特征值,以下一个状态值为标签的监督学习过程

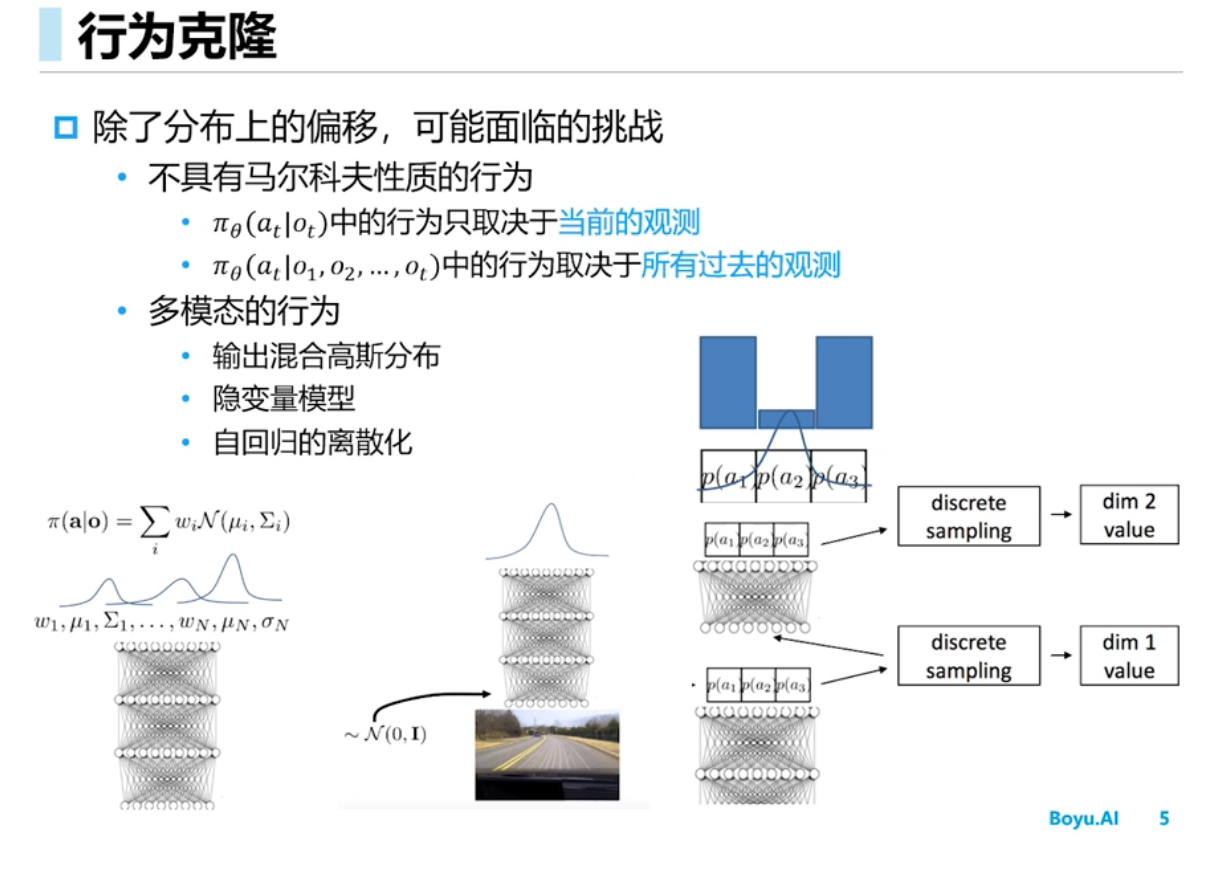
强化学习中多模态的行为指的是什么?
在强化学习中,多模态的行为是指智能体在学习和执行任务时,能够利用多种不同类型的输入信号,从而实现更加丰富和复杂的行为。
在传统的强化学习中,智能体通常只能通过单一的输入信号(例如状态向量)来感知环境,并通过一个单一的输出信号(例如动作向量)来执行动作。但在现实世界中,智能体通常需要同时感知多种不同类型的信息,例如图像、声音、文本等。这些不同类型的信息可以提供不同的视角和丰富的信息,帮助智能体更好地理解环境和任务,并做出更加准确和高效的决策。
因此,利用多模态的行为可以提高智能体的学习能力和任务执行能力。例如,在视觉任务中,智能体可以同时感知图像和语音信号,从而更好地理解环境和执行任务;在语音交互任务中,智能体可以同时感知语音和文本信号,从而更好地理解用户的意图和需求。同时,多模态的行为也带来了更多的挑战和复杂性,例如如何有效地融合不同类型的输入信号和如何处理不同类型的输出信号等。
逆强化学习
逆强化学习找到一个代价函数使得专家策略产生较低的代价,而其他策略产生较高的代价,然后通过使用该代价函数进行正向强化学习,尝试恢复专家策略

奖励函数的相反数可以看做代价函数


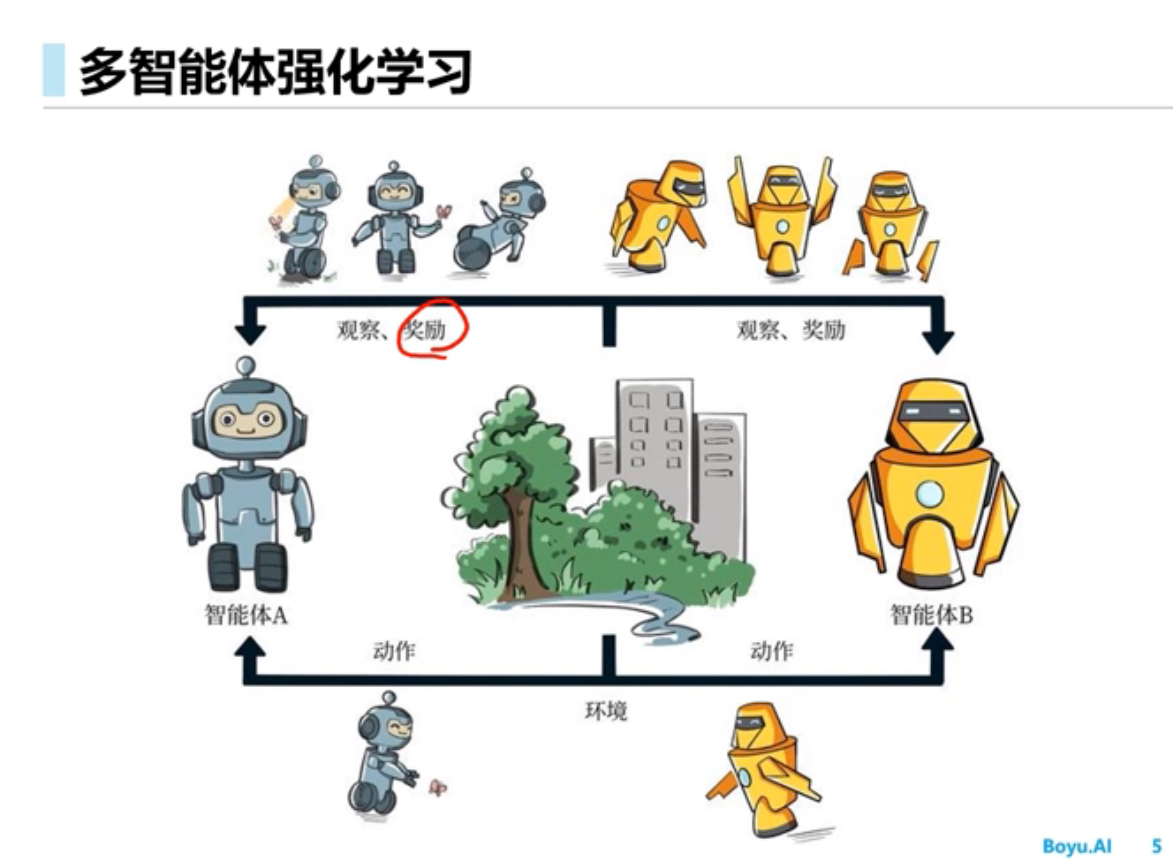
多智能体强化学习
简介
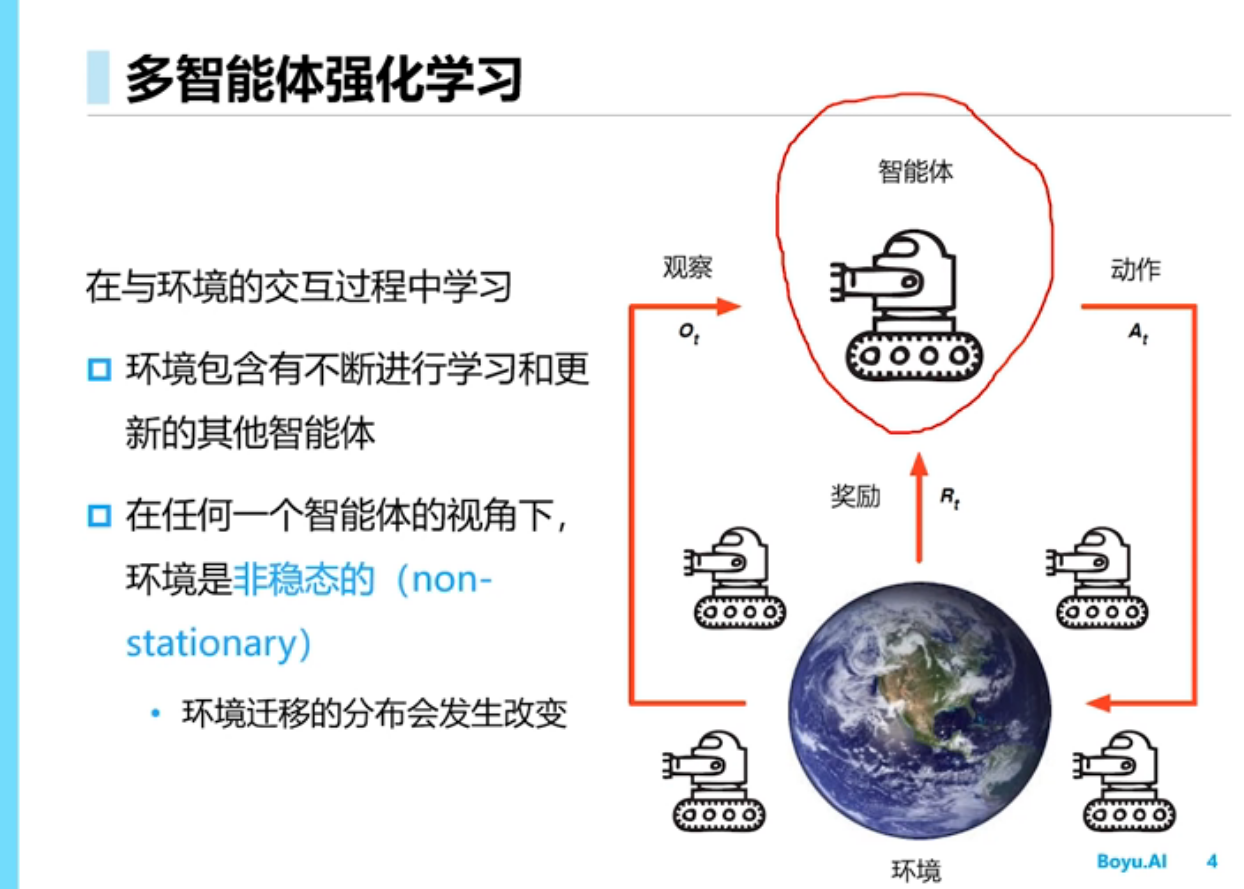
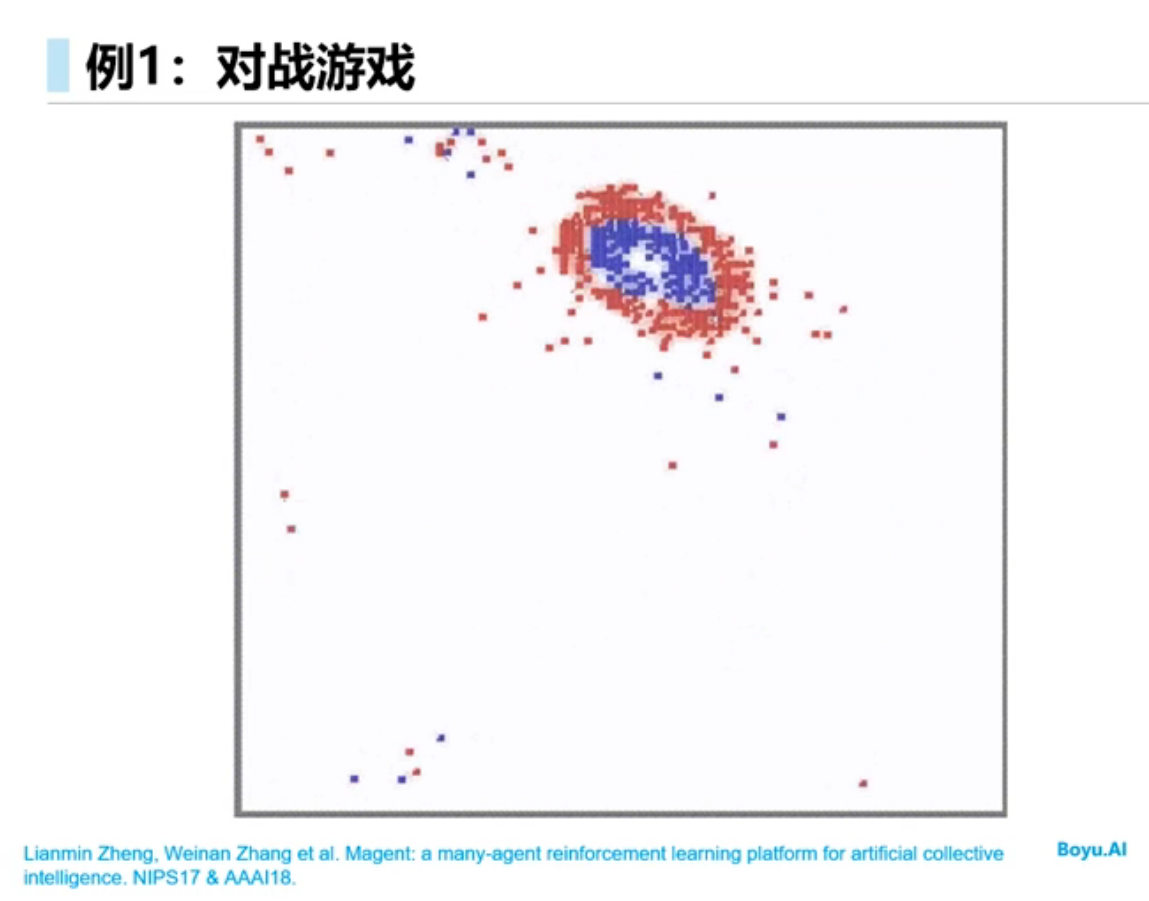



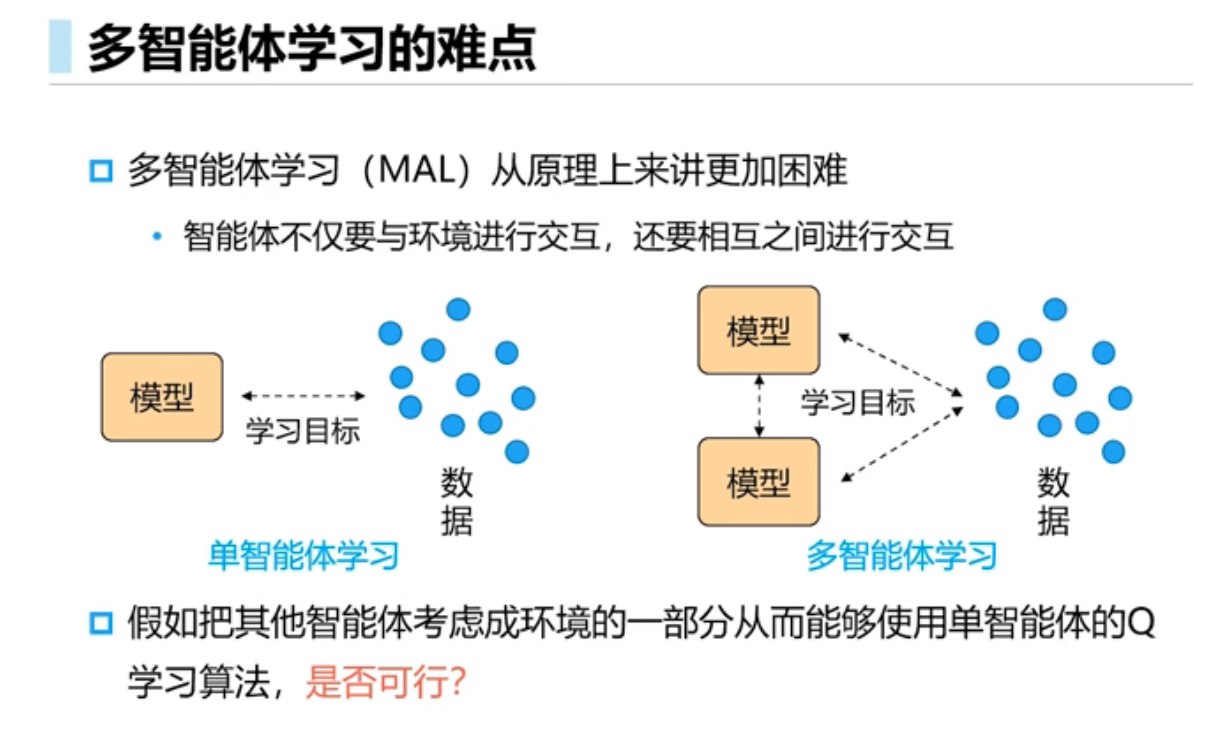
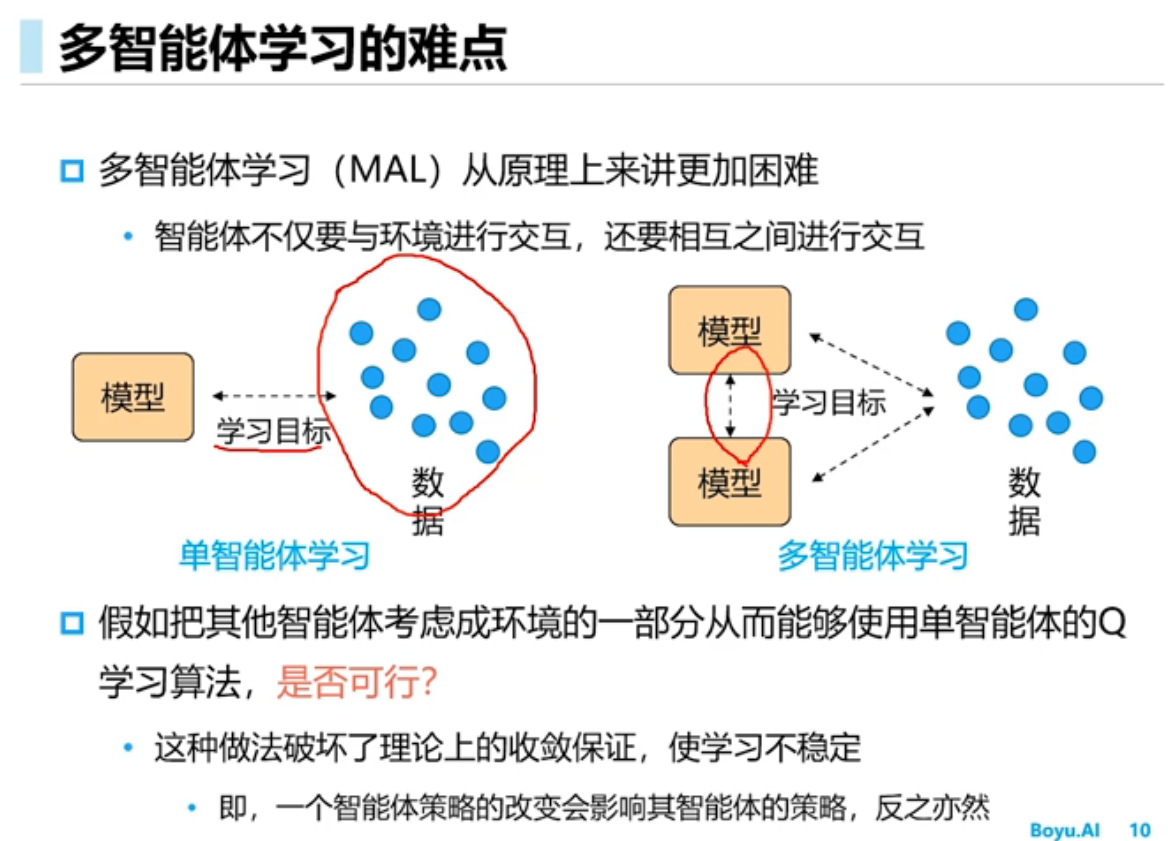
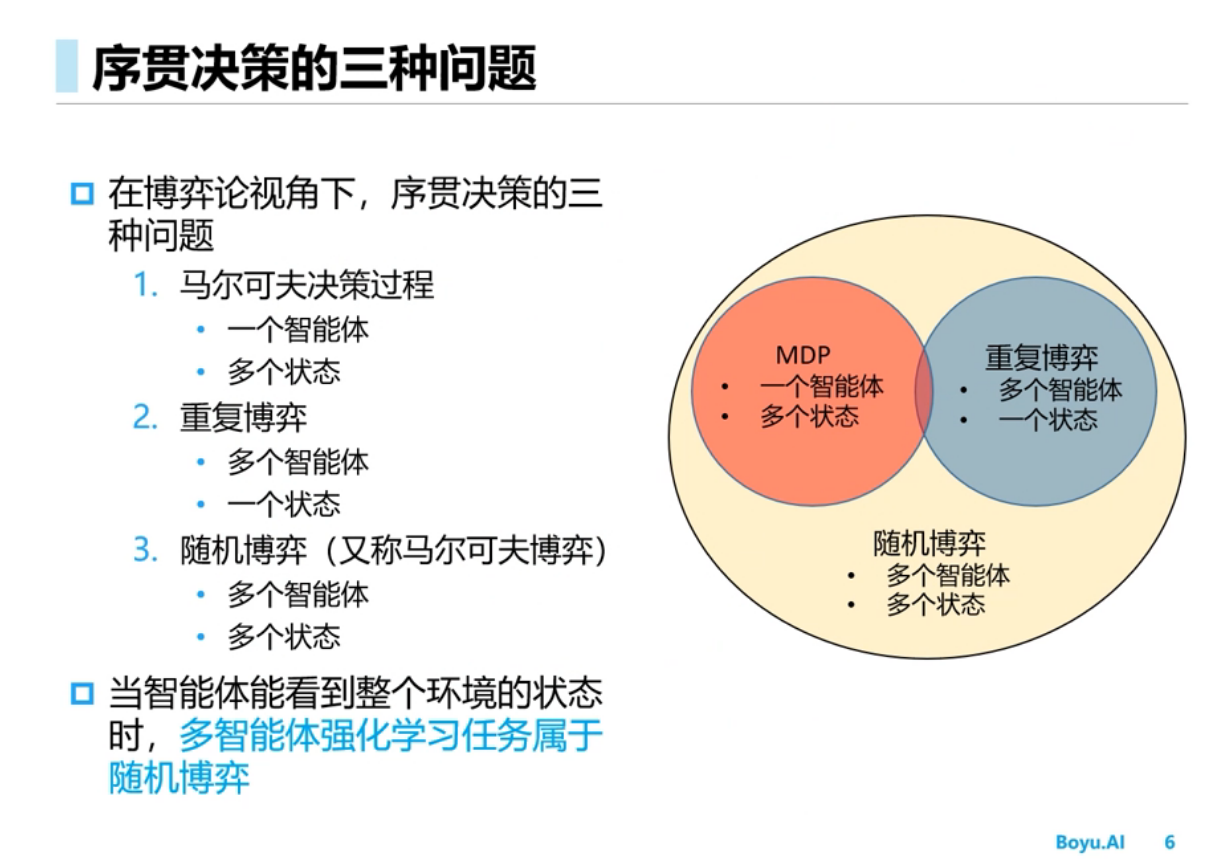
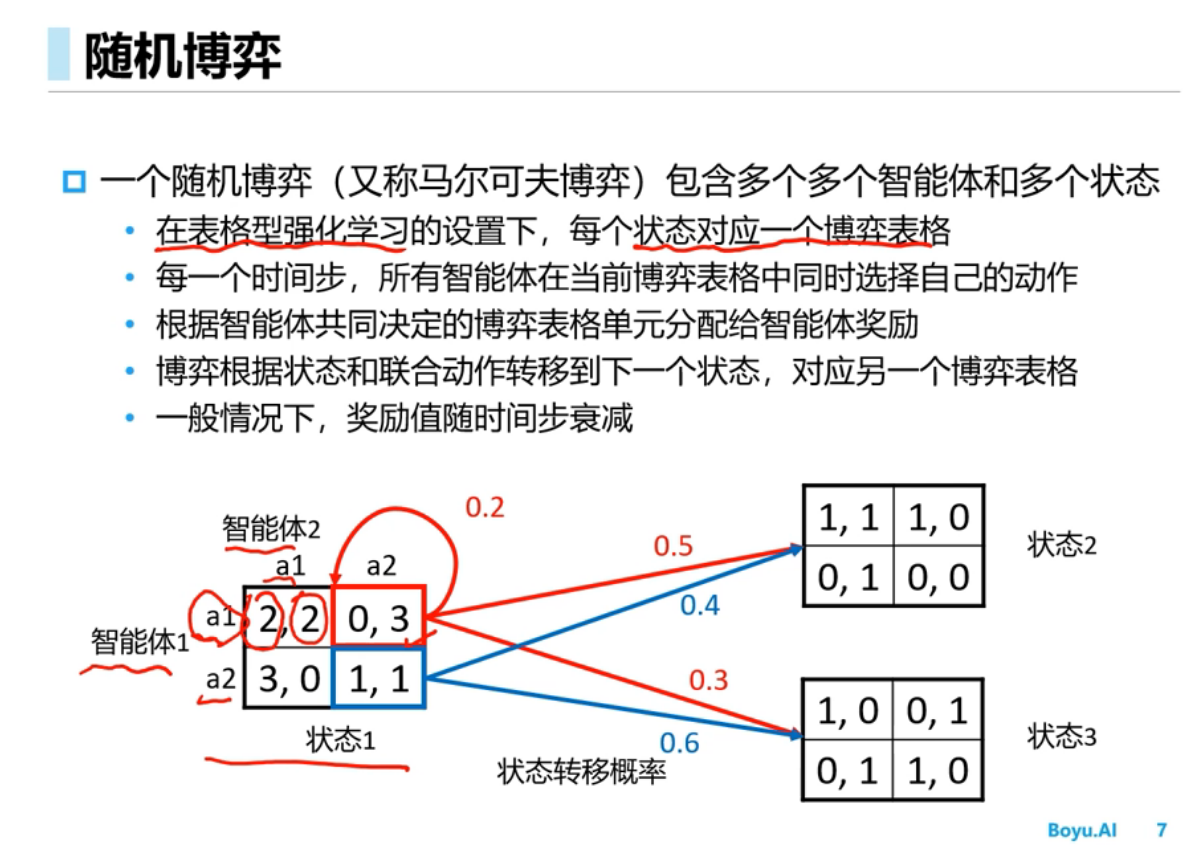
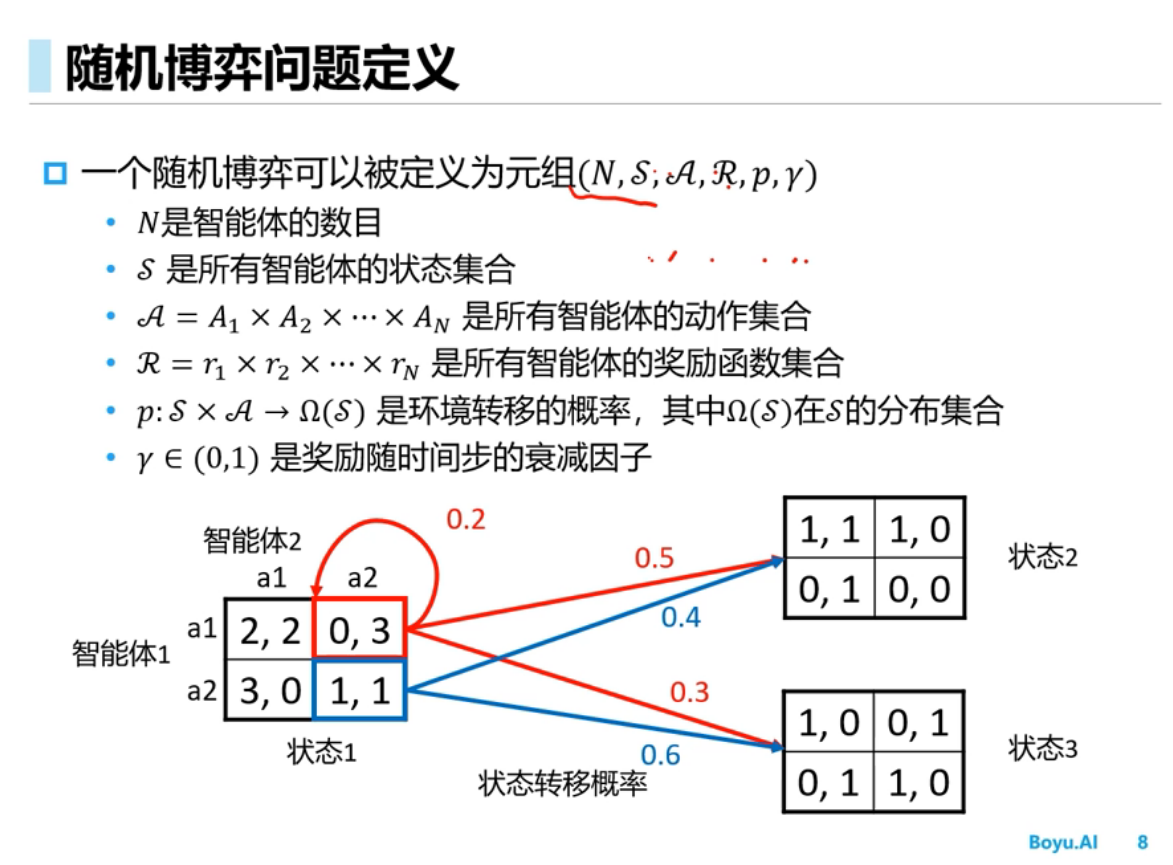
多智能体的环境是非稳态的,智能体不仅和环境交互,智能体之间还要交互,假如把其他智能体当成环境的一部分从而使用单智能体的学习算法,结果不可行,原因是该方法环境不是稳态的,任何一个智能体策略的改变会影响其它智能体的策略,学习不收敛
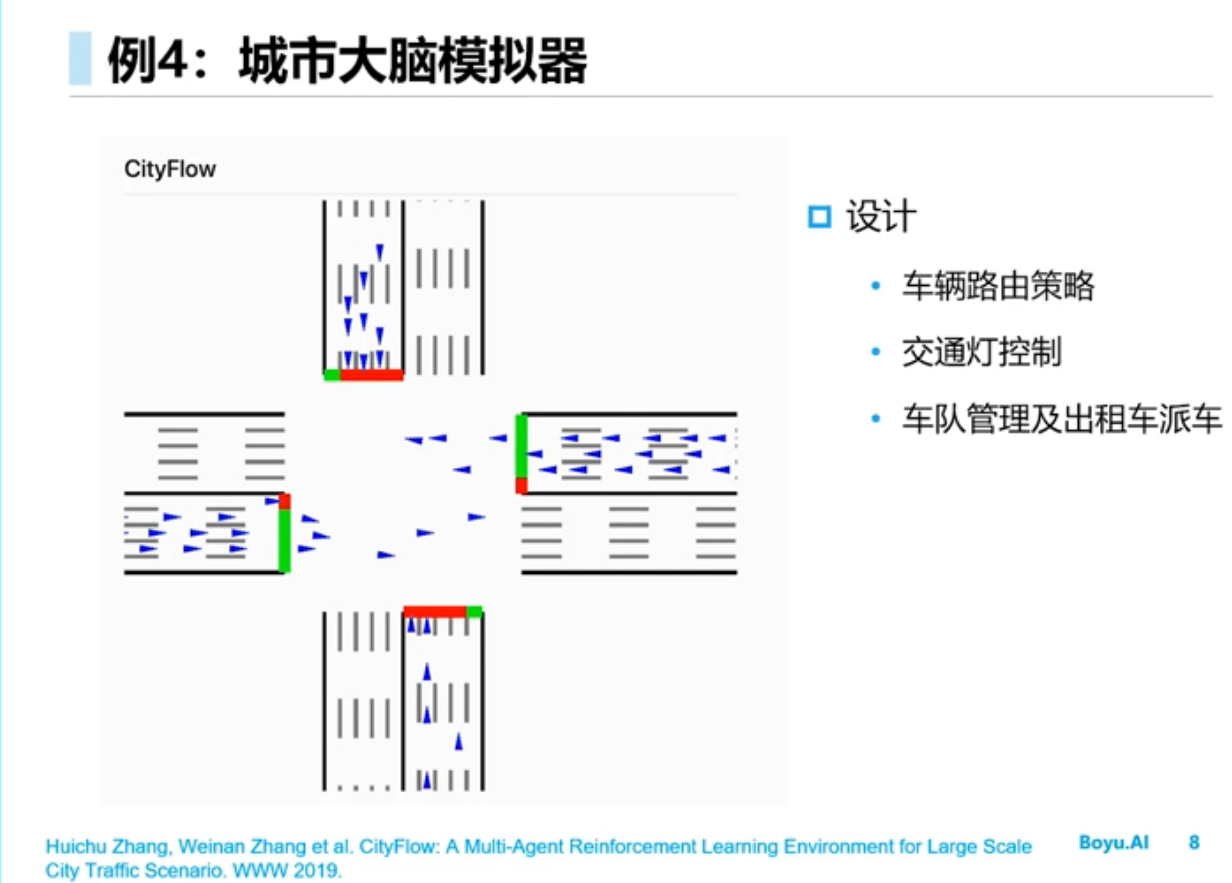
入门

多智能体环境是非稳态的[稳态的意思是说条件概率分布是不能改变的]



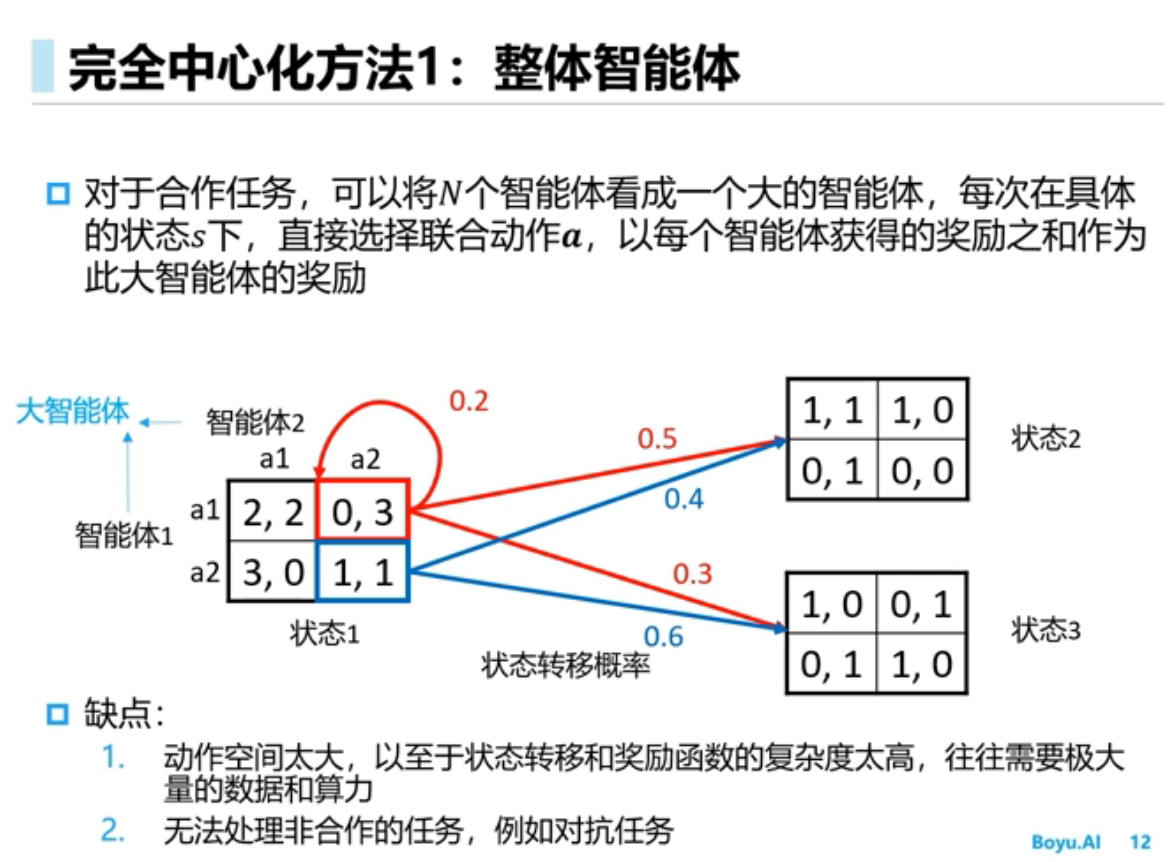



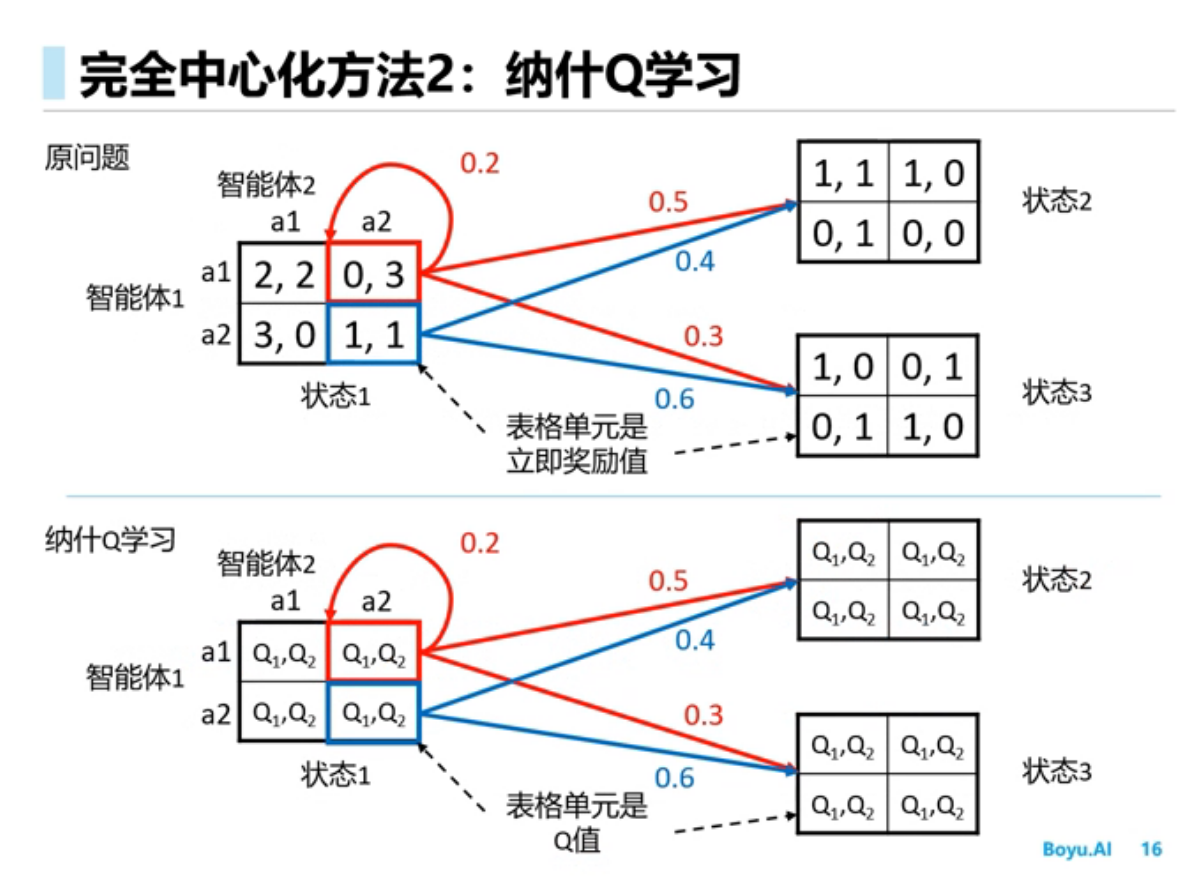



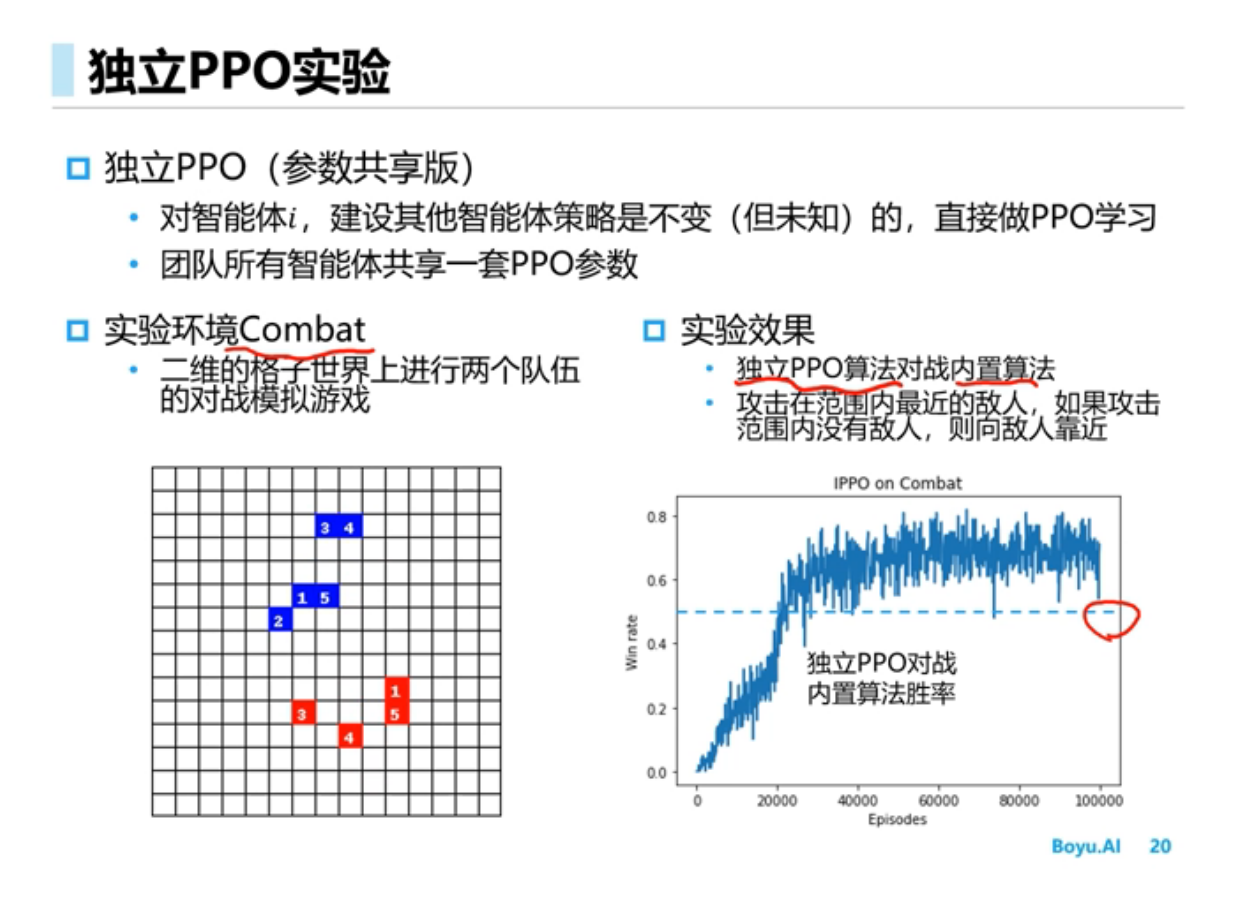
进阶

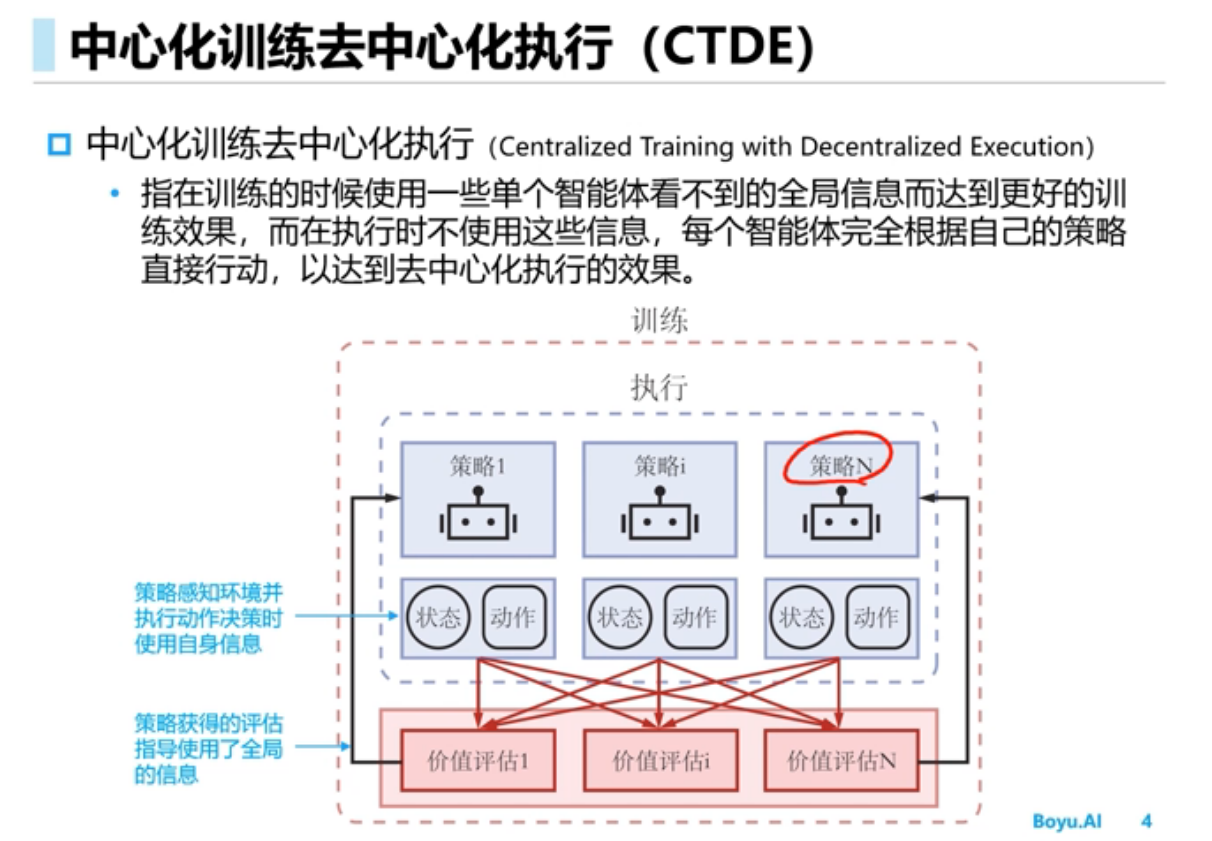


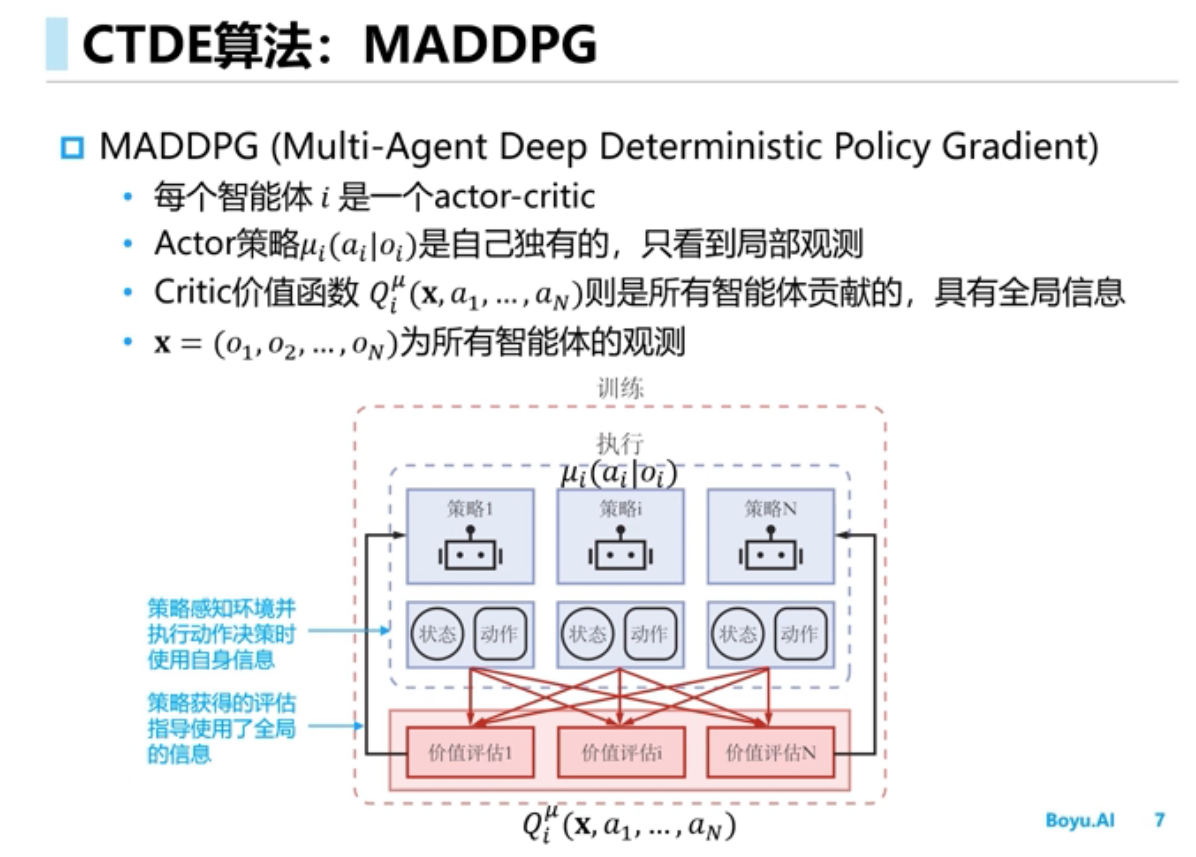


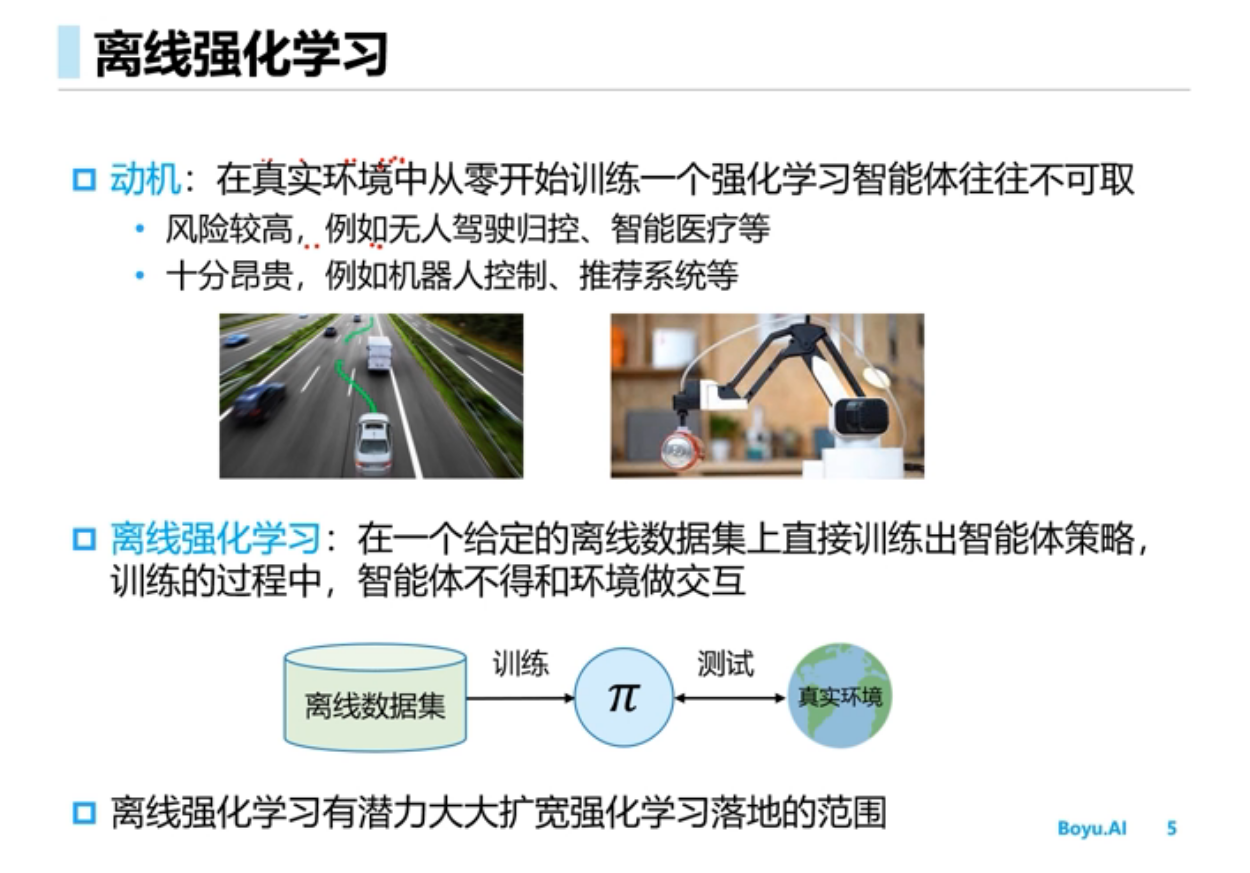
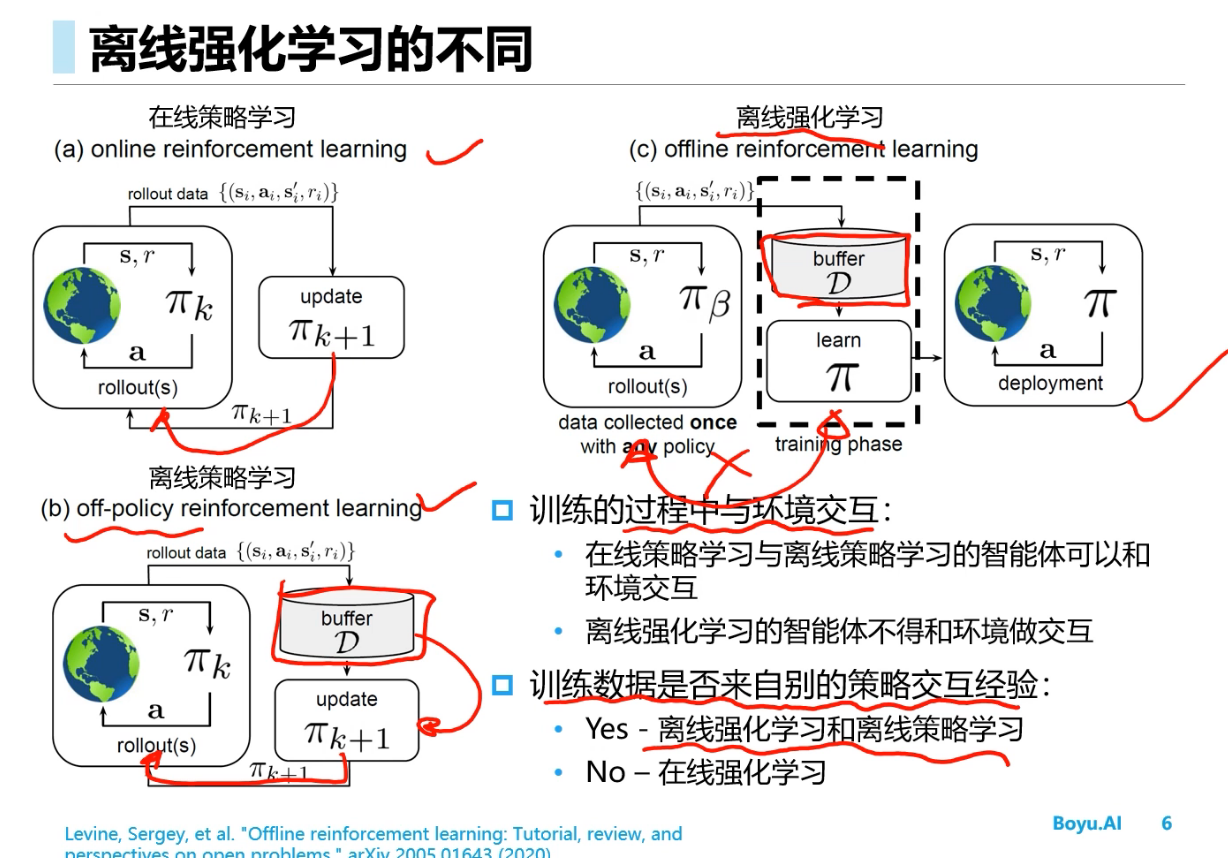
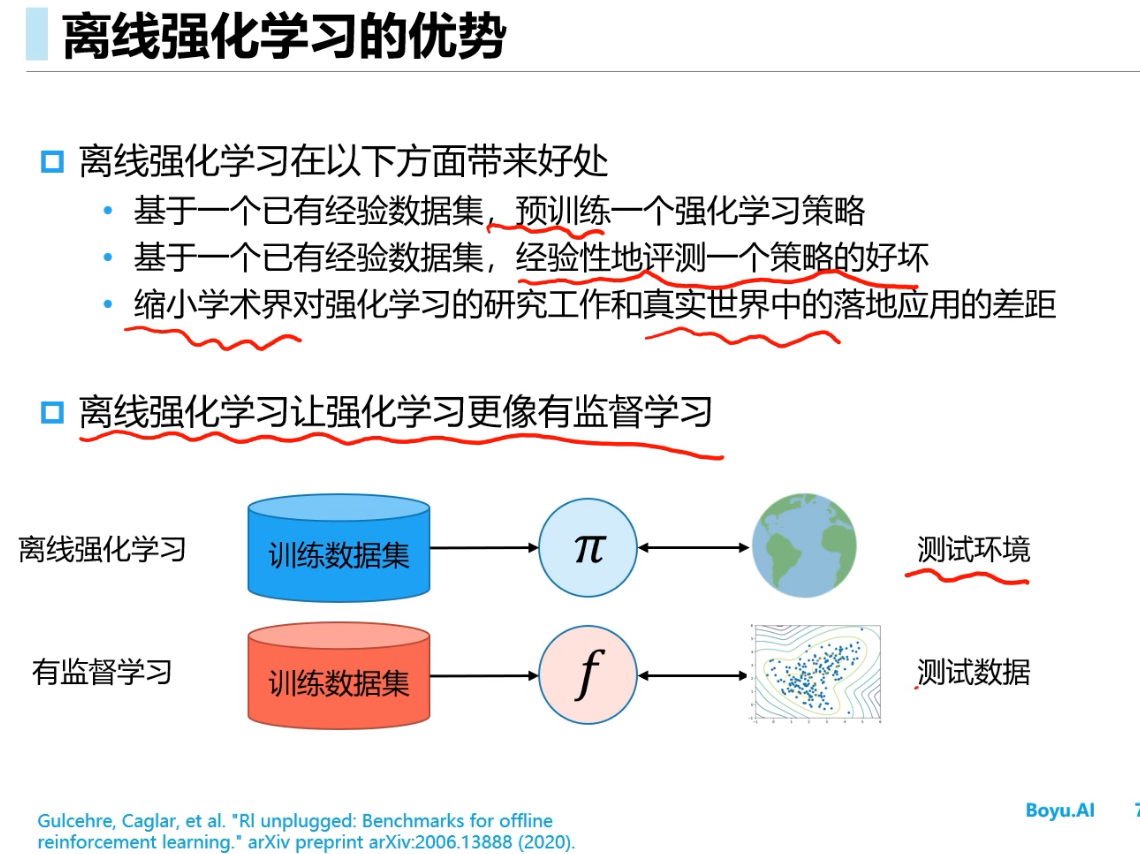
Offline RL(离线强化学习)


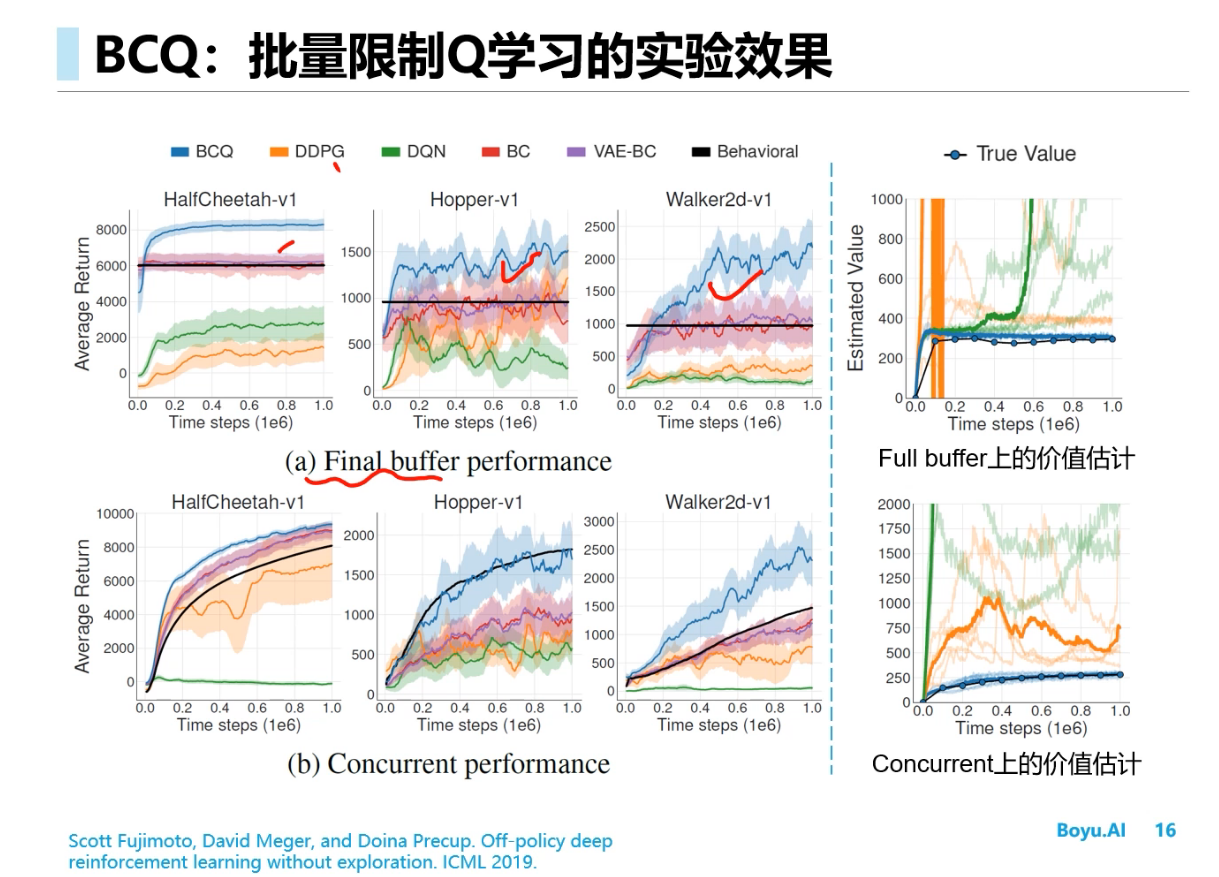
BCQ
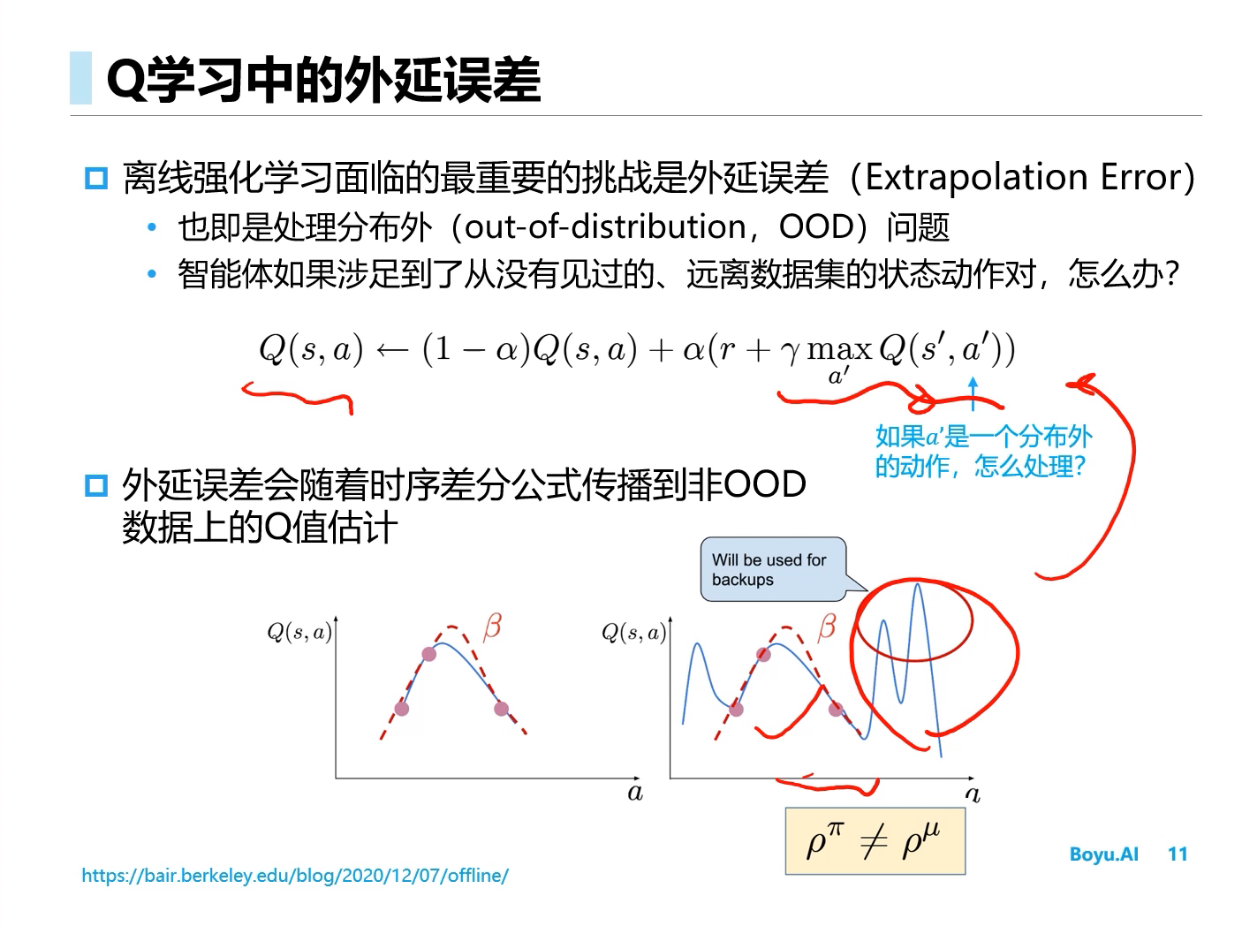
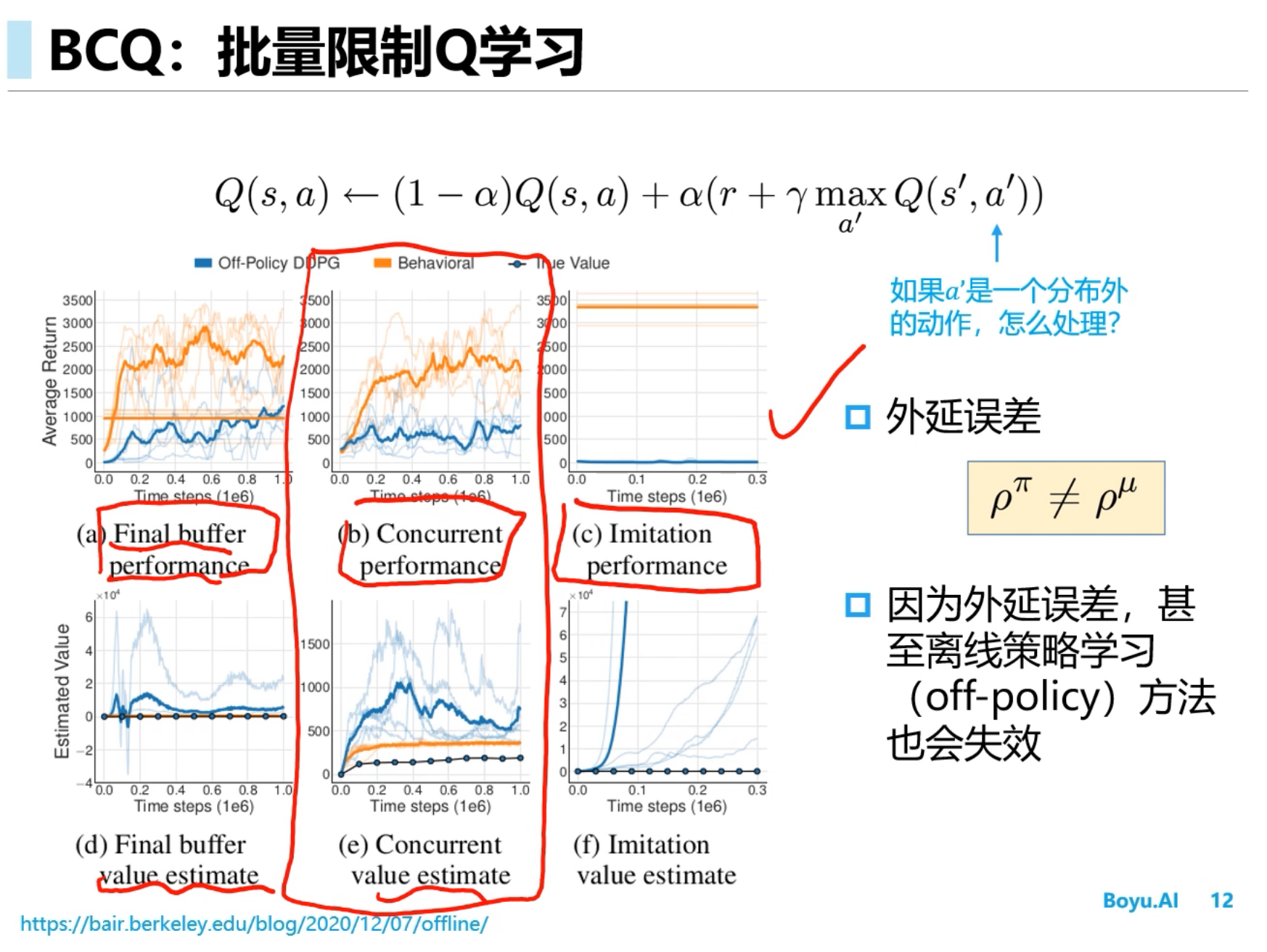
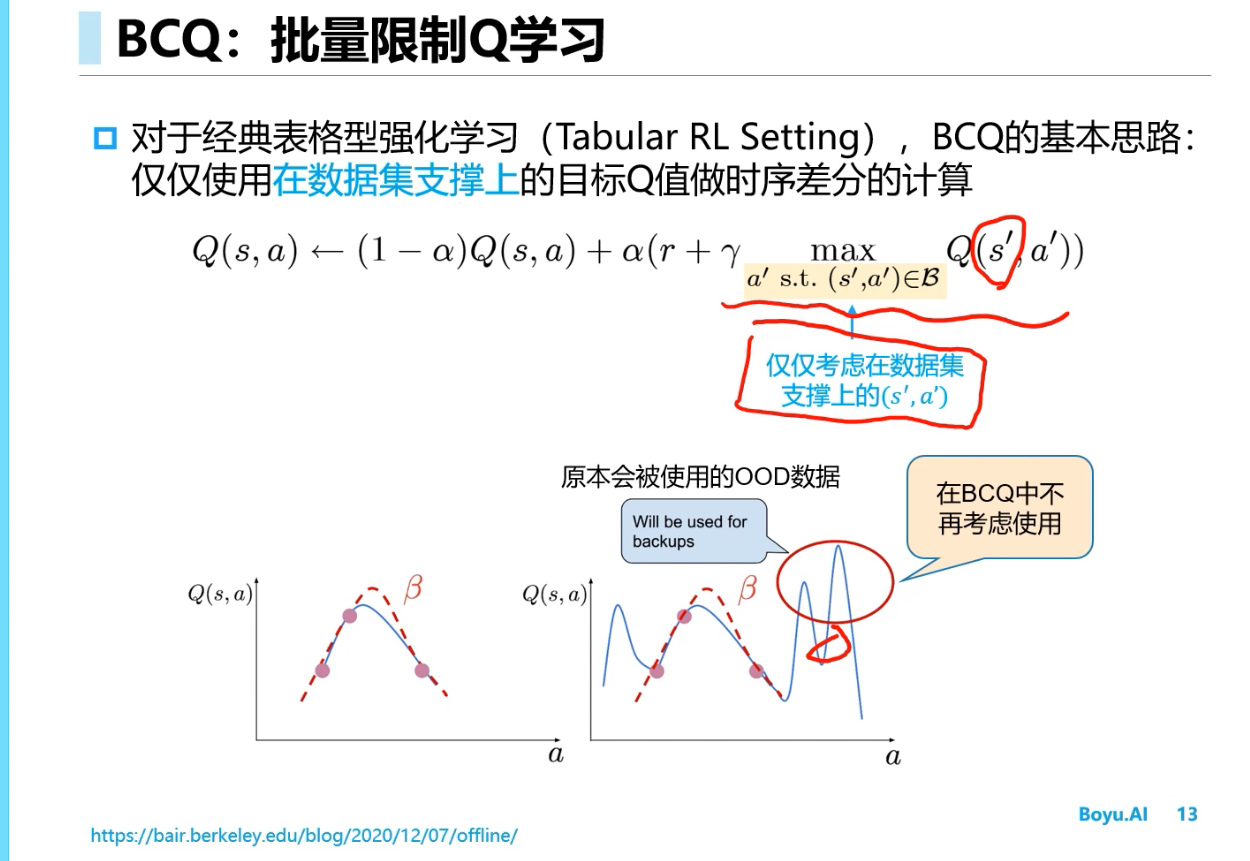

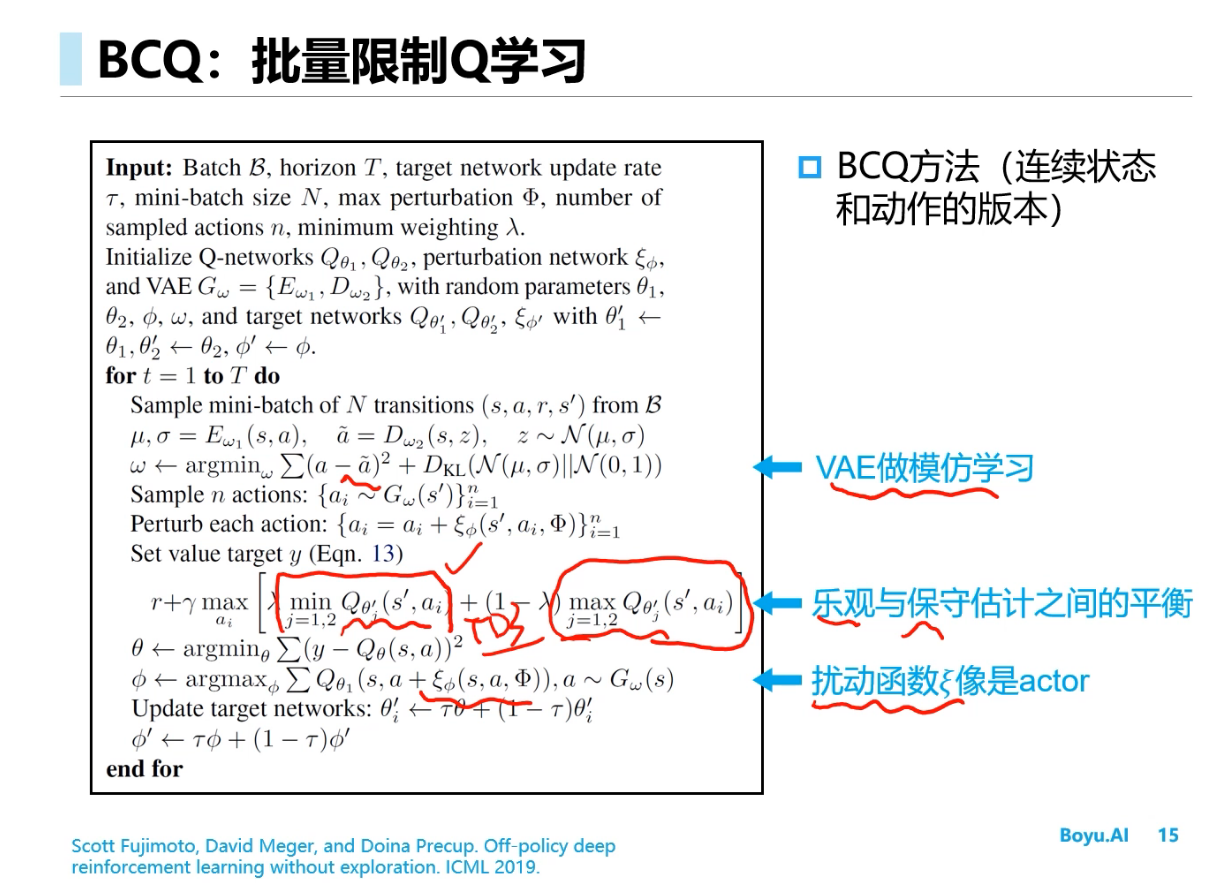
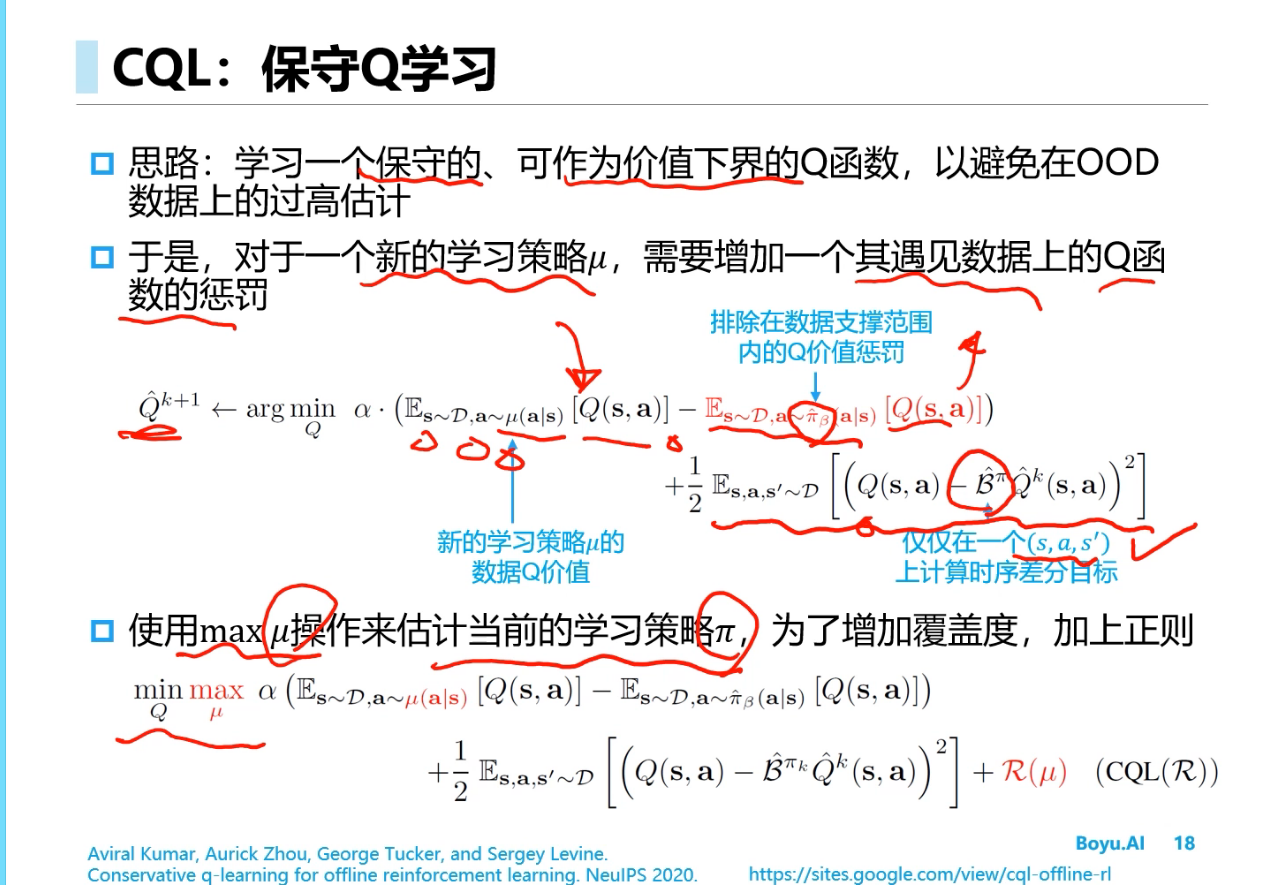
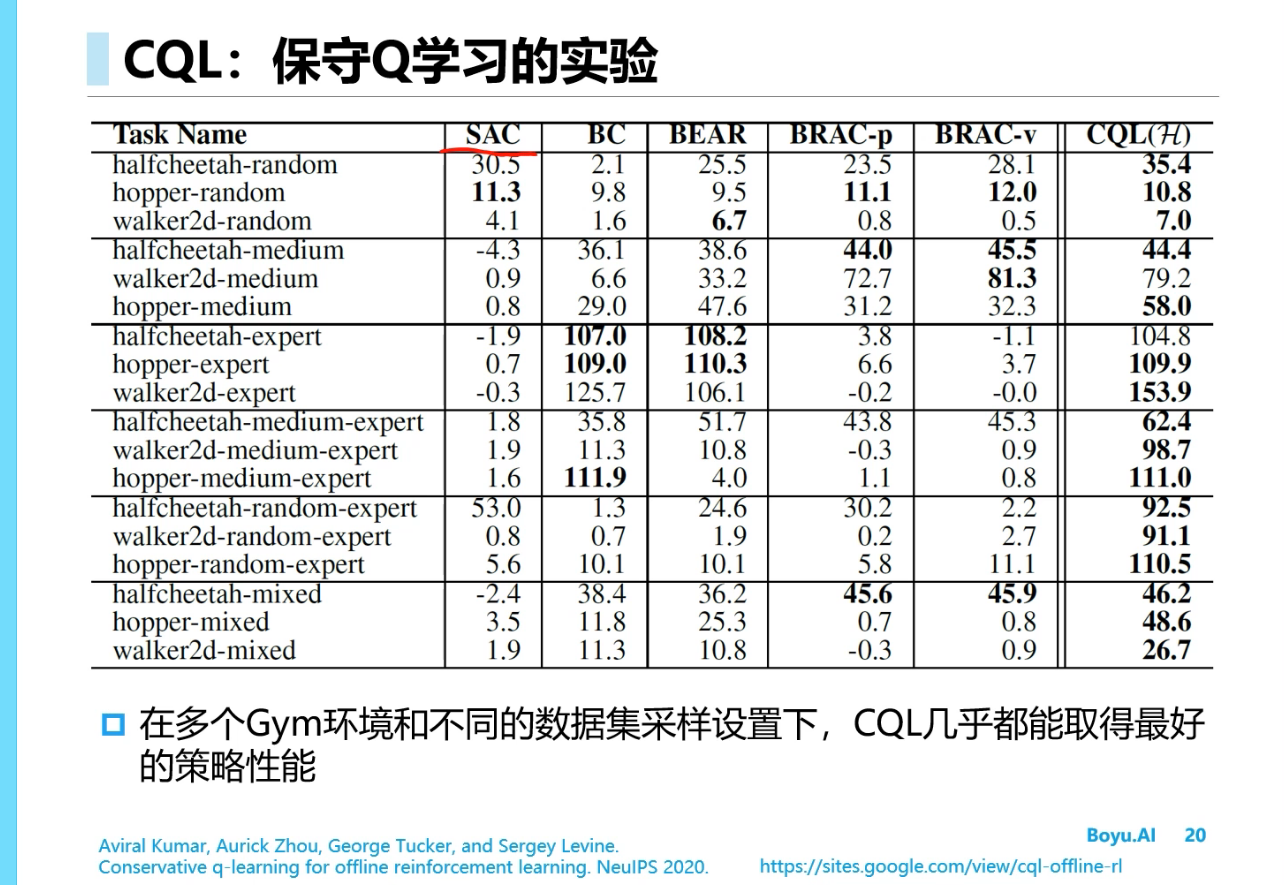
==CQL==

知识Tips
- 深度强化学习可以分类为基于价值的方法、基于随机策略的方法和基于确定性策略的方法,其中基于确定性策略的方法包括了确定性策略梯度(DPG)和深度确定性策略梯度(DDPG)
- 第一,reward设置成[-1, 1]是normalized之后的结果,一般reward的设置是根据reward function或是根据一些经验值,比如在一些经典的迷宫场景中,reward的设置一般是一步-1的reward,作用是鞭策agent加快学习过程,在一些悬崖的地方会设置很大的负reward比如-200,这是因为这些地方会直接导致游戏结束,所以reward会很大,有点类似于自动驾驶中的撞车。不过总体来说reward的设置多数是根据经验并结合reward function。第二,强化学习本身也是一个搜索和优化的过程,肯定存在一些局部最优点,agent在学习的过程中很可能会收敛到局部最优点,解决方法主要是通过exploration来扩大搜索范围,防止agent因为没有见过相关的state而收敛到现有的state,目前也有一种方法是学习anti-goal,可以参考

