In the field of machine learning, when it comes to extracting relationships between variables, we often use Pearson correlation. The problem is that this measure only finds linear relationships, which can lead sometimes to a bad interpretation of the relation between two variables. Nevertheless, other statistics measure non-linear relationships, such as mutual information.
Therefore, in this post, we are going to explain mutual information, how it is calculated, and an example of its use.
Mutual Information
The Mutual Information between two random variables measures non-linear relations between them. Besides, it indicates how much information can be obtained from a random variable by observing another random variable.
It is closely linked to the concept of entropy. This is because it can also be known as the reduction of uncertainty of a random variable if another is known. Therefore, a high mutual information value indicates a large reduction of uncertainty whereas a low value indicates a small reduction. If the mutual information is zero, that means that the two random variables are independent.
But, how is mutual information calculated?
The following formula shows the calculation of the mutual information for two discrete random variables.
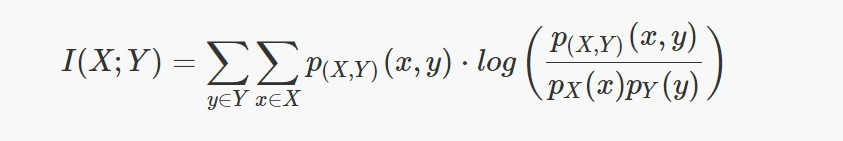
Where $p_x$ and $p_y $are the marginal probability density functions and $p_{xy}$ the joint probability density function.
Whereas to compute the mutual information for continuous random variables the summations have to be replaced by the integrals.
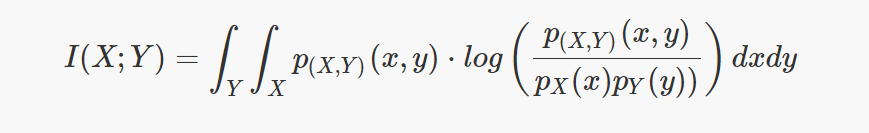
As explained before, it is related to entropy. This relation is shown in the following formula:
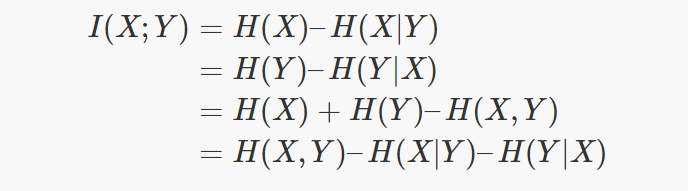
Entropy (H) measures the level of expected uncertainty in a random variable. Therefore, H(X) is approximately how much information can be learned of the random variable X by observing just one sample.
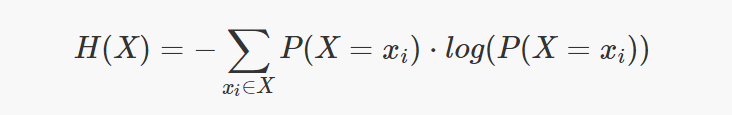
The joint entropy measures the uncertainty when considering together two random variables.
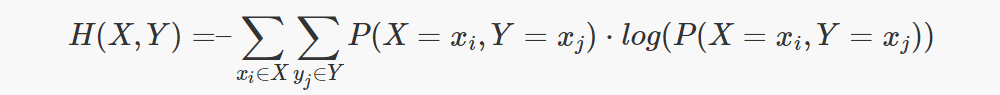
The conditional entropy measures how much uncertainty has the random variable X when the value of Y is known.
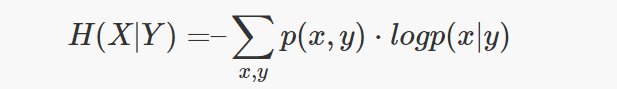
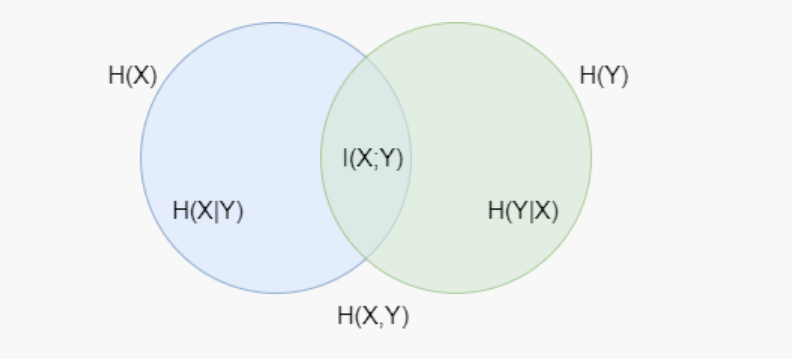
For better understanding, the relationship between entropy and mutual information has been depicted in the following Venn diagram, where the area shared by the two circles is the mutual information:
Properties of Mutual Information
The main properties of the Mutual Information are the following:

Since mutual information has only lower boundaries, sometimes it is difficult to interpret the obtained result. Looking at the equation that relates mutual information with entropy and the Venn diagram, we can see that it is possible to obtain the maximum value of the mutual information.
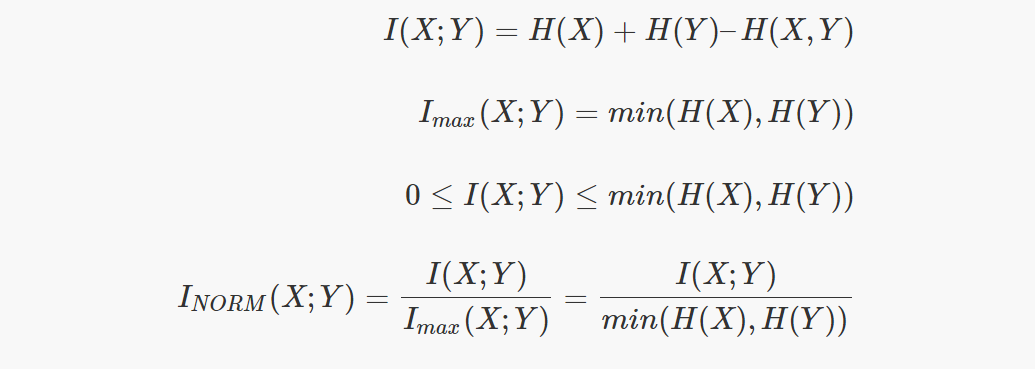
So, what is the difference between Mutual Information and correlation?
The main difference is that correlation is a measure of linear dependence, whereas mutual information measures general dependence (including non-linear relations). Therefore, mutual information detects dependencies that do not only depend on the covariance. Thus, mutual information is zero when the two random variables are strictly independent.
Uses
In the field of machine learning, one of its main uses is in decision trees. It is used for looking for the optimum split of the features to choose the nodes that compose the tree (also called information gain).
Another use is for feature selection. When having a big dataset with a big range of features, mutual information can help to select a subset of those features in order to discard the irrelevant ones.
In other fields, mutual information is also widely used. For example, in telecommunications, it is used to calculate the channel capacity.
Example
Let’s see an example of how mutual information can be used for feature selection. For that purpose, we are going to generate a synthetic dataset and then, calculate the mutual information between the features and the target. Then, the features with higher scores will be the selected ones.
Using the make_classification function of the python library scikit-learn, we generate a synthetic dataset, which is a binary classification problem. This function allows us to choose the number of informative, repeated, redundant, and random features.
Once generated the dataset with 6 informative features, 1 redundant, 2 repeated, and 1 random, we calculate the mutual information between each feature and the target. Using the mutual_info_classif also of scikit-learn, we obtain the following results:

As can be seen, features 7 and 8 have the same mutual information as 2 and 5, respectively, so they are the repeated ones. Furthermore, features 9 and 10 have a mutual information value of 0, indicating that they are both independent of the target, so they are random features. Moreover, the rest of the features are the informative ones and the redundant ones. Note that only by calculating the mutual information between the features and the target, we can no distinguish between informative and redundant features.
Conclusions
In this post, we have seen what is mutual information, how it is calculated, its differences with correlation, and an example of how to use it for feature selection.

