anaconda package工具包
Anaconda(官方网站)就是可以便捷获取包且对包能够进行管理,同时对环境可以统一管理的发行版本。Anaconda包含了conda、Python在内的超过180个科学包及其依赖项。
命令行语句
在Anconda Prompt中输入
conda create -n pytorch python=3.8.1 # 这里pytorch 为环境名称 conda activate pytorch # 切换到此环境 conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch # 在这个环境安装 python import torch torch.cuda.is_available()#输出应为True #环境备份 conda create -n pytorch_copy --clone pytorch #删除环境 conda env remove -n 环境名称 or #在linux中激活conda环境 # 激活 anaconda 环境 source activate # 退出 anaconda 环境 source deactivate or # 在windows中直接使用的话,需要添加anaconda 环境变量,比如我这儿是 #C:\software\Anaconda3和C:\software\Anaconda3\Scripts 这两个放进Path中 #windows 查看环境 conda info -e #进入环境 activate py38torch1切换环境
使用Anaconda切换python环境
- 首先,用conda env list 或者 coda info -e 查看python环境的名称
- 然后,如果只有base环境,可以用conda create -n 环境自定义名字 python=版本数比如3.9,3.7
- 最后,有了其他环境后,就可以用conda activate 自定义的环境名 来切换环境了。
- 补充一点,直接用conda activate 退出当前环境,到base环境,python -V 或 –vison,查看版本;
整理:
- conda env list conda info -e
- conda create -n name python=number
- conda env remove -n 环境名称
- conda activate name
- python –version python -V
尝试能不能想起这些代码的意思吧,可不要为python版本而烦恼啦
更换清华源,and excute
conda config --set ssl_verify False
pyTorch加载数据
Dataset类 & Dataloader
Dataset 是一个抽象类
from torch.utils.data import Dataset from PIL import Image import os class MyData(Dataset): def __init__(self,root_dir,lable_dir): self.root_dir = root_dir self.lable_dir = lable_dir self.path = os.path.join(self.root_dir,self.lable_dir) self.img_path = os.listdir(self.path) def __getitem__(self, idx): img_name = self.img_path[idx] img_item_path = os.path.join(self.root_dir,self.lable_dir,img_name) img = Image.open(img_item_path) lable = self.lable_dir return img,lable def __len__(self): return len(self.img_path) def main(): root_dir = "dataset/train" ants_lable_dir = "ants" bees_lable_dir = "bees" ants_dataset = MyData(root_dir,ants_lable_dir) # img , lable = ants_dataset.__getitem__(0) # img.show() bees_dataset = MyData(root_dir,bees_lable_dir) datas = ants_dataset + bees_dataset print(type(datas)) if __name__ == "__main__": main()
TensorBoard
显示训练过程中的一些数据
查看事件:tensorboard –logdir=事件文件文件夹名 [–port=指定显示端口名]
if __name__ == "__main__":
# main()
writer = SummaryWriter("logs")
for i in range(100):
writer.add_scalar("y=x",i,i)
tensorboard --logdir=logs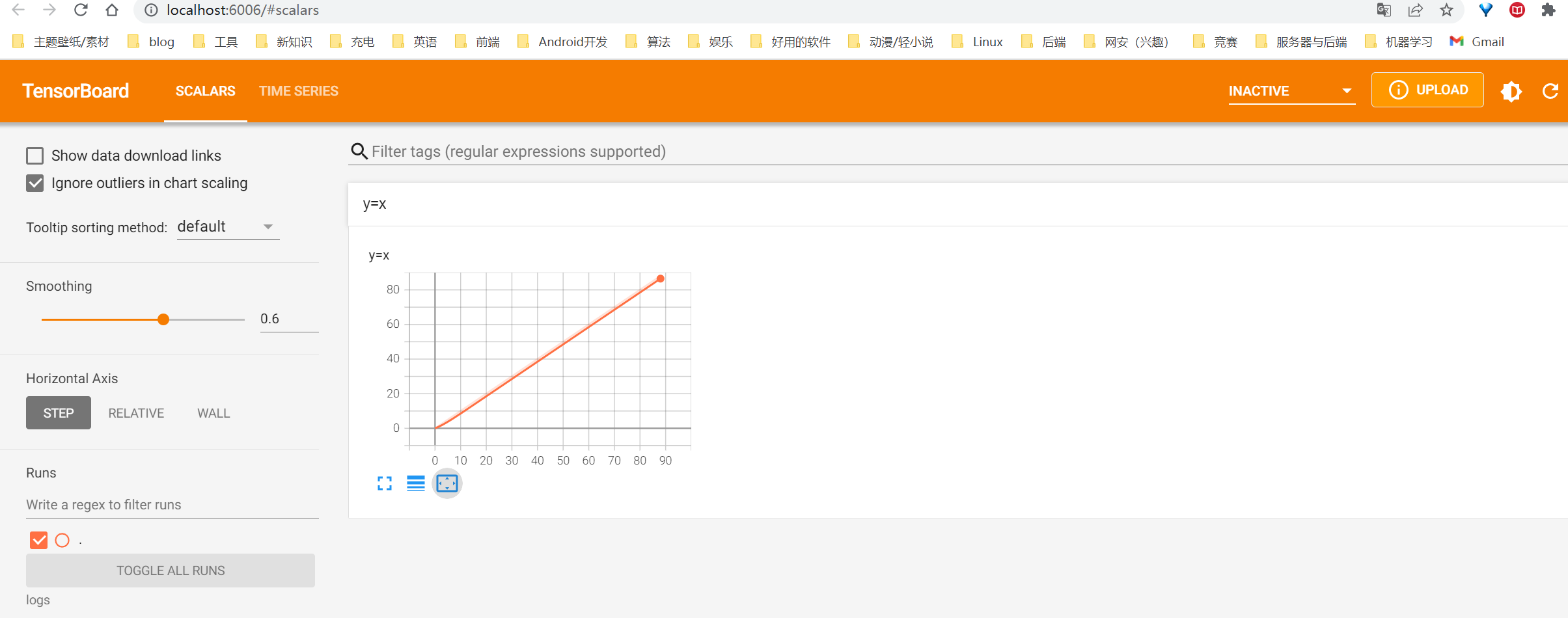
writer = SummaryWriter("logs")
img_path = "dataset/train/ants/0013035.jpg"
img = Image.open(img_path)
img_array = np.array(img)# 接受类型不支持PIL.image ,需转换
writer.add_image("test",img_array,1,dataformats="HWC")
writer.close()
#import cv2
# if __name__ == "__main__":
# img_path = r"dataset/train/ants/0013035.jpg"
# cv_img = cv2.imread(img_path) # <class 'numpy.ndarray'>
# writer = SummaryWriter("logs")
# writer.add_image("cv2",cv_img,dataformats="HWC")
# writer.close()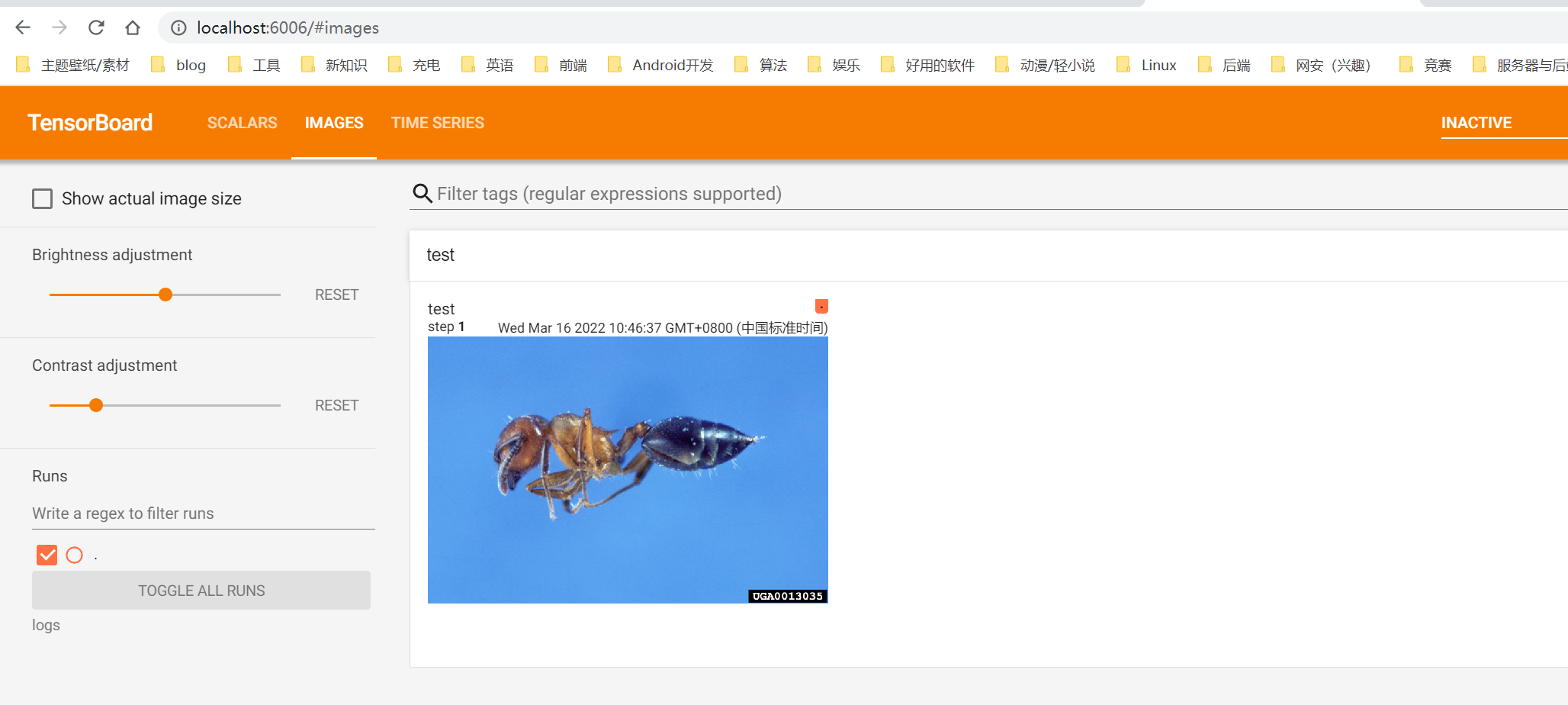
TransForms
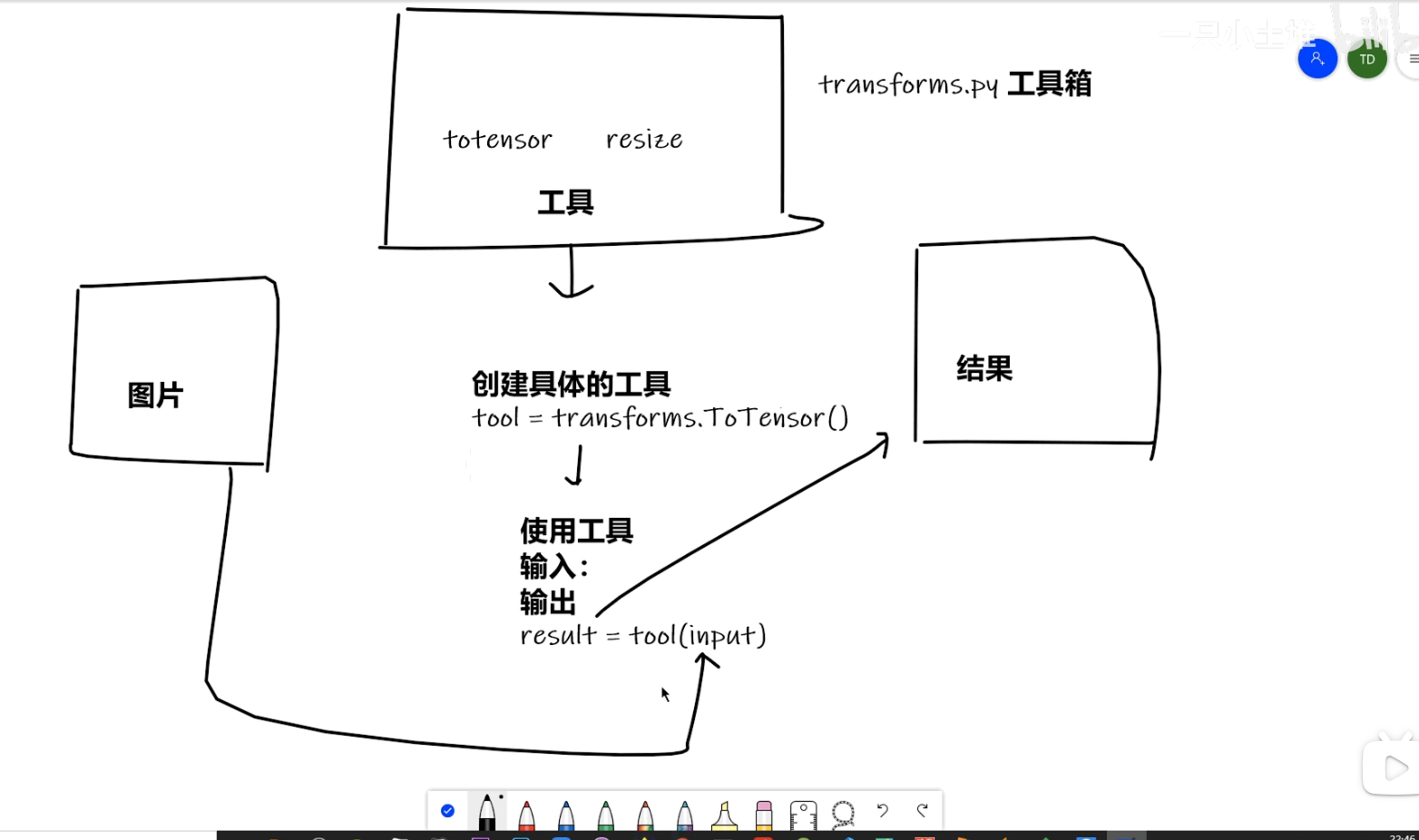
通过transforms.ToTensor去看两个问题
transforms 该如何使用(python)
img_path = r"dataset/train/ants/0013035.jpg" img = Image.open(img_path) writer = SummaryWriter("logs") tensor_trans = transforms.ToTensor() tensor_img = tensor_trans(img) writer.add_image("Tensor_img",tensor_img) writer.close()为什么我们需要Tensor数据类型
Resize()的使用
if __name__ == "__main__":
trans_totensor = transforms.ToTensor()
img_path = r"dataset/train/ants/0013035.jpg"
img = Image.open(img_path)
print(img.size)#(768, 512)
trans_resize = transforms.Resize((212,212))
# img PIL -> resize -> img_resize PIL
img_resize = trans_resize(img)
#img_resize PIL -> totensor -> img_resize tensor
img_resize = trans_totensor(img_resize)
print(type(img_resize))torchvision中的数据集的使用
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose(
[torchvision.transforms.ToTensor()] # 将图片转化为Tensor类型
)
train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)
# print(test_set[0])
#
# print(test_set.classes)
#
# img,traget = test_set[0]
# print(img)
# print(traget)
#
# img.show()
writer = SummaryWriter("P10")
for i in range(10):
img,target = test_set[i]
writer.add_image("test_set",img,i)
writer.close()
#########################
import torch
import torchvision.transforms as transforms
import torchvision.models as models
from PIL import Image
img_path = 'path/to/image.jpg'
# 定义图像转换
transform = transforms.Compose([
transforms.Resize(256), # 调整图像大小为256x256
transforms.CenterCrop(224), # 中心裁剪为224x224
transforms.ToTensor(), # 将图像转换为张量
transforms.Normalize(
mean=[0.485, 0.456, 0.406], # ImageNet数据集的均值
std=[0.229, 0.224, 0.225] # ImageNet数据集的标准差
)
])
# 加载图像并进行转换
img = Image.open(img_path)
img_tensor = transform(img)DataLoader的使用
#encoding=utf-8
import torchvision
# 准备测试数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
# 测试数据集中第一张图片及target
img,target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader2")
step = 0
for data in test_loader:
imgs,targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("test_data",imgs,step)#这里用的是add_images而不是add_image
step += 1
writer.close()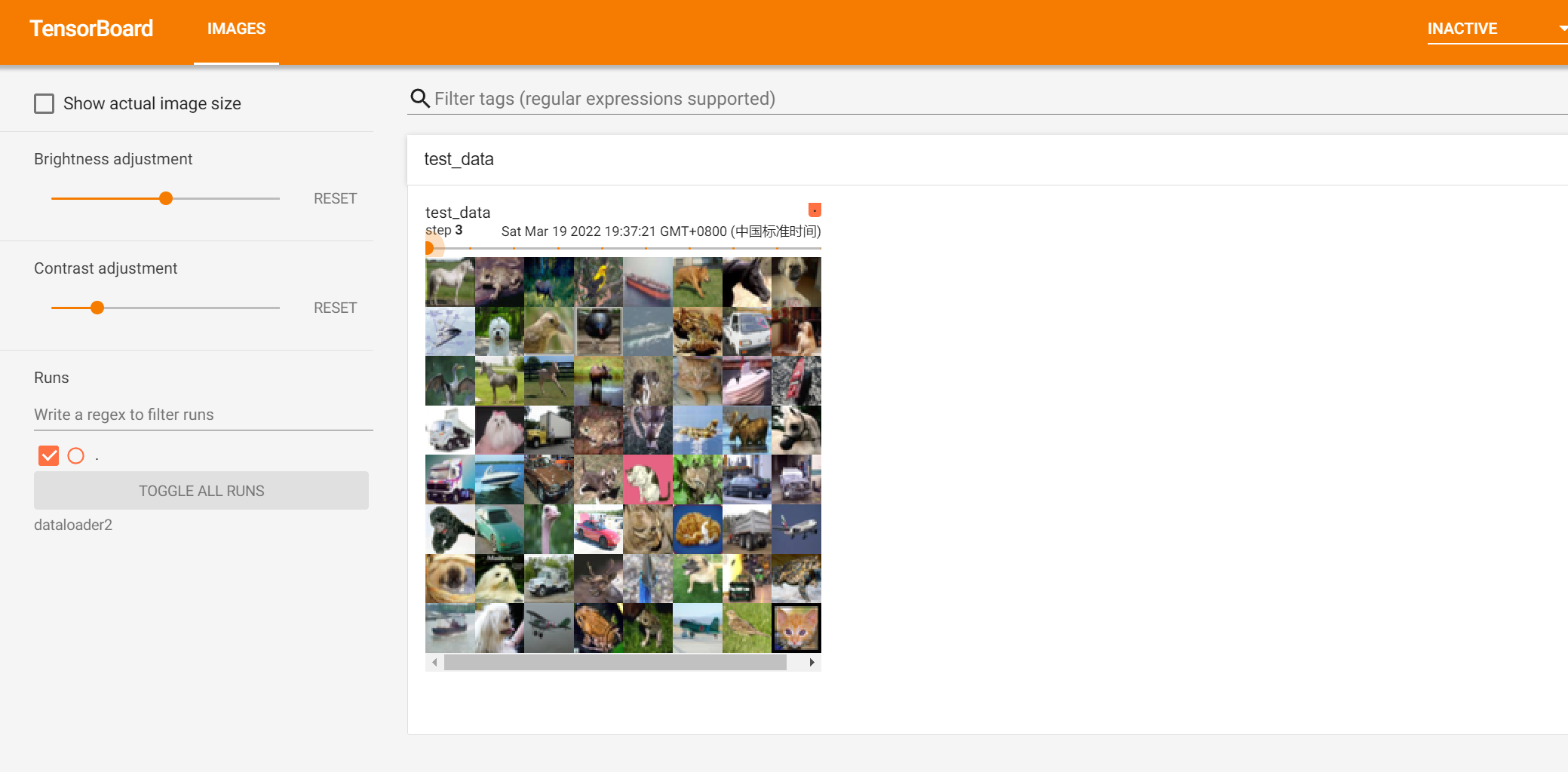
神经网络
基本骨架
nn.module的使用
#encoding=utf-8
import torch
from torch import nn
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
def forward(self,input):
output = input + 1
return output
tudui = Tudui()
x = torch.tensor(1.0)
output = tudui(x)
print(output)Sequential
# Using Sequential to create a small model. When `model` is run,
# input will first be passed to `Conv2d(1,20,5)`. The output of
# `Conv2d(1,20,5)` will be used as the input to the first
# `ReLU`; the output of the first `ReLU` will become the input
# for `Conv2d(20,64,5)`. Finally, the output of
# `Conv2d(20,64,5)` will be used as input to the second `ReLU`
#
#使用顺序创建一个小模型。 当“model”运行时,
# input将首先被传递给' Conv2d(1,20,5) '。 的输出
# ' Conv2d(1,20,5) '将用作第一个的输入
#“ReLU”; 第一个“ReLU”的输出将成为输入
#“Conv2d(64 5)”。 最后,输出
# ' Conv2d(20,64,5) '将用作第二个' ReLU '的输入
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# Using Sequential with OrderedDict. This is functionally the
# same as the above code
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
#encoding=utf-8
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class MyNN(nn.Module):
def __init__(self):
super(MyNN, self).__init__()
# self.conv1 = Conv2d(3,32,5,padding=2)
# self.maxpool1 = MaxPool2d(2)
# self.conv2 = Conv2d(32,32,5,padding=2)
# self.maxpool2 = MaxPool2d(2)
# self.conv3 = Conv2d(32,64,5,padding=2)
# self.maxpool3 = MaxPool2d(2)
# self.flatten = Flatten()
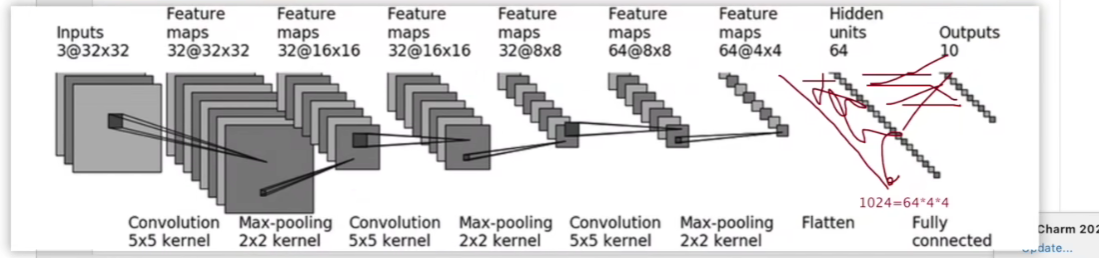
# self.linear1 = Linear(1024,64)
# self.linear2 = Linear(64,10)
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
# x = self.conv1(x)
# x = self.maxpool1(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.conv3(x)
# x = self.maxpool3(x)
# x = self.flatten(x)
# x = self.linear1(x)
# x = self.linear2(x)
x = self.model1(x)
return x
myNN = MyNN()
print(myNN)
'''
MyNN(
(conv1): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv3): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear1): Linear(in_features=1024, out_features=64, bias=True)
(linear2): Linear(in_features=64, out_features=10, bias=True)
)
'''
input = torch.ones((64,3,32,32))
output = myNN(input)
print(output.shape)# torch.Size([64, 10])
writer = SummaryWriter("logs")
writer.add_graph(myNN,input)
writer.close()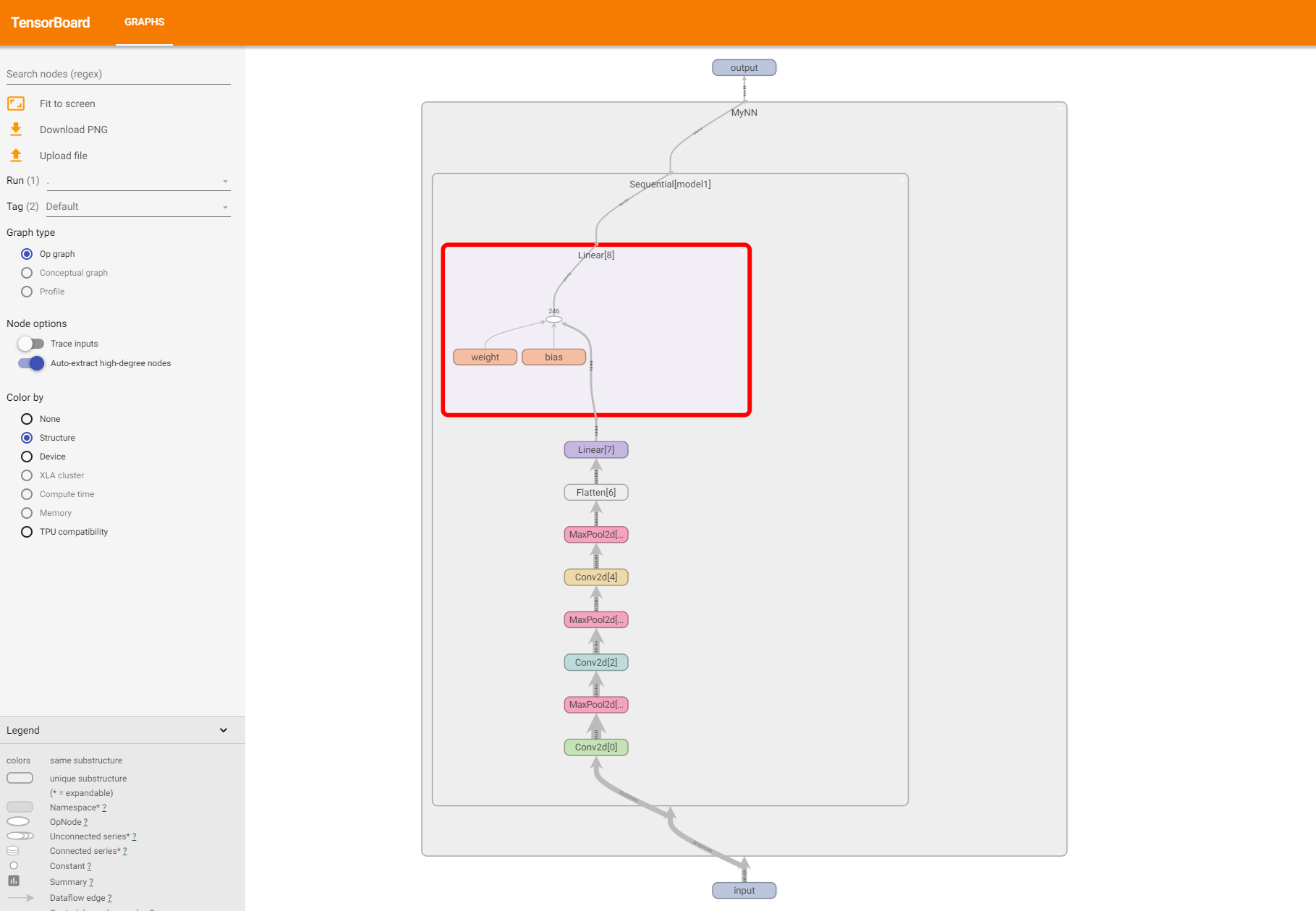
卷积
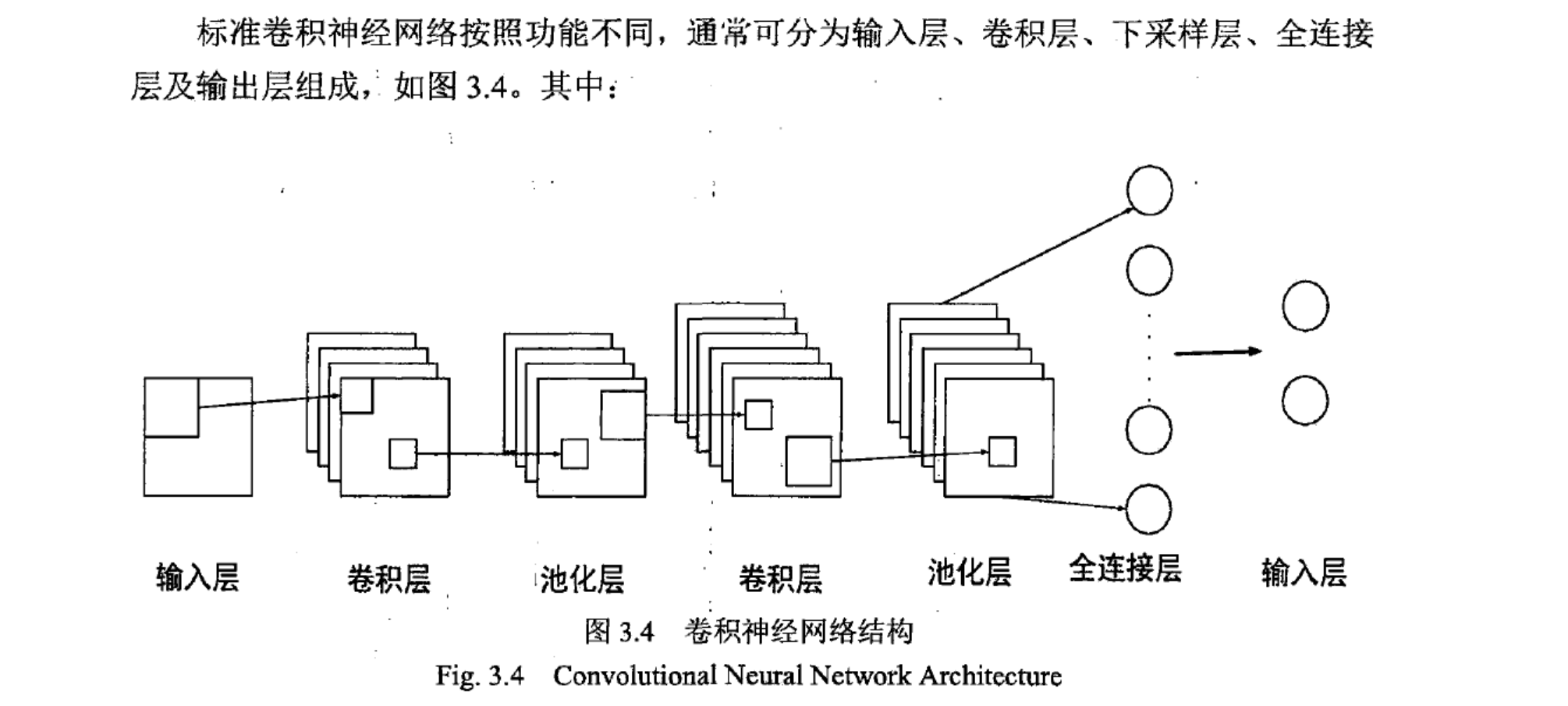
torch.nn.functional参数

#encoding=utf-8
import torch
import torch.nn.functional as F
input = torch.tensor([[1,2,0,3,1],[0,1,2,3,1],[1,2,1,0,0],[5,2,3,1,1],[2,1,0,1,1]])
kernel = torch.tensor([[1,2,1],[0,1,0],[2,1,0]])
# print((input.shape))# torch.Size([5, 5])
# print((kernel.shape))# torch.Size([3, 3])
input = torch.reshape(input,(1,1,5,5))
kernel = torch.reshape(kernel,(1,1,3,3))
# print((input.shape))# torch.Size([1, 1, 5, 5]) (batch-size,channel,hight,width)
# print((kernel.shape))# torch.Size([1, 1, 3, 3])
output = F.conv2d(input,kernel,stride=1)
print(output)
'''
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])
'''
output2 = F.conv2d(input,kernel,stride=2)
print(output2)
'''
tensor([[[[10, 12],
[13, 3]]]])
'''
output3 = F.conv2d(input,kernel,stride=1,padding=1)
print(output3)
'''
tensor([[[[ 1, 3, 4, 10, 8],
[ 5, 10, 12, 12, 6],
[ 7, 18, 16, 16, 8],
[11, 13, 9, 3, 4],
[14, 13, 9, 7, 4]]]])
'''卷积层
#encoding=utf-8
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
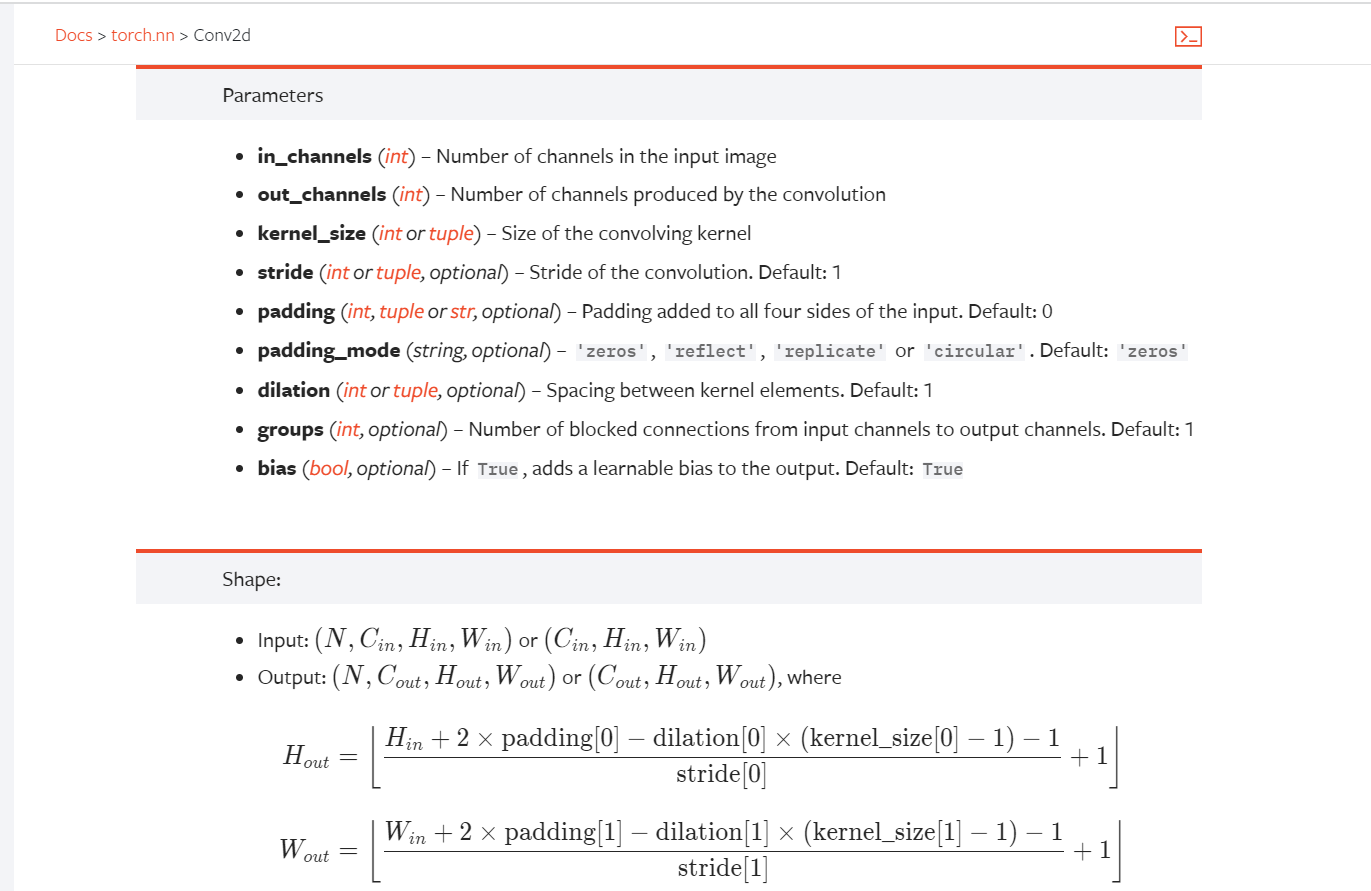
self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)# 卷积层
def forward(self,x):
x = self.conv1(x)# 将x放入卷积层
return x
tudui = Tudui()
print(tudui)
'''
神经网络结构
Tudui(
(conv1): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1))
)
'''
step = 0
writer = SummaryWriter("./logs")
for data in dataloader:
imgs,targets = data
output = tudui(imgs)
print(output.shape) #torch.Size([64, 6, 30, 30])
#torch.Size([64,6,30,30]) -->[xxx,3,30,30]
output = torch.reshape(output,(-1,3,30,30))# -1就保持原来的不变
writer.add_images("input",imgs,step)
writer.add_images("output",output,step)
step += 1
writer.close()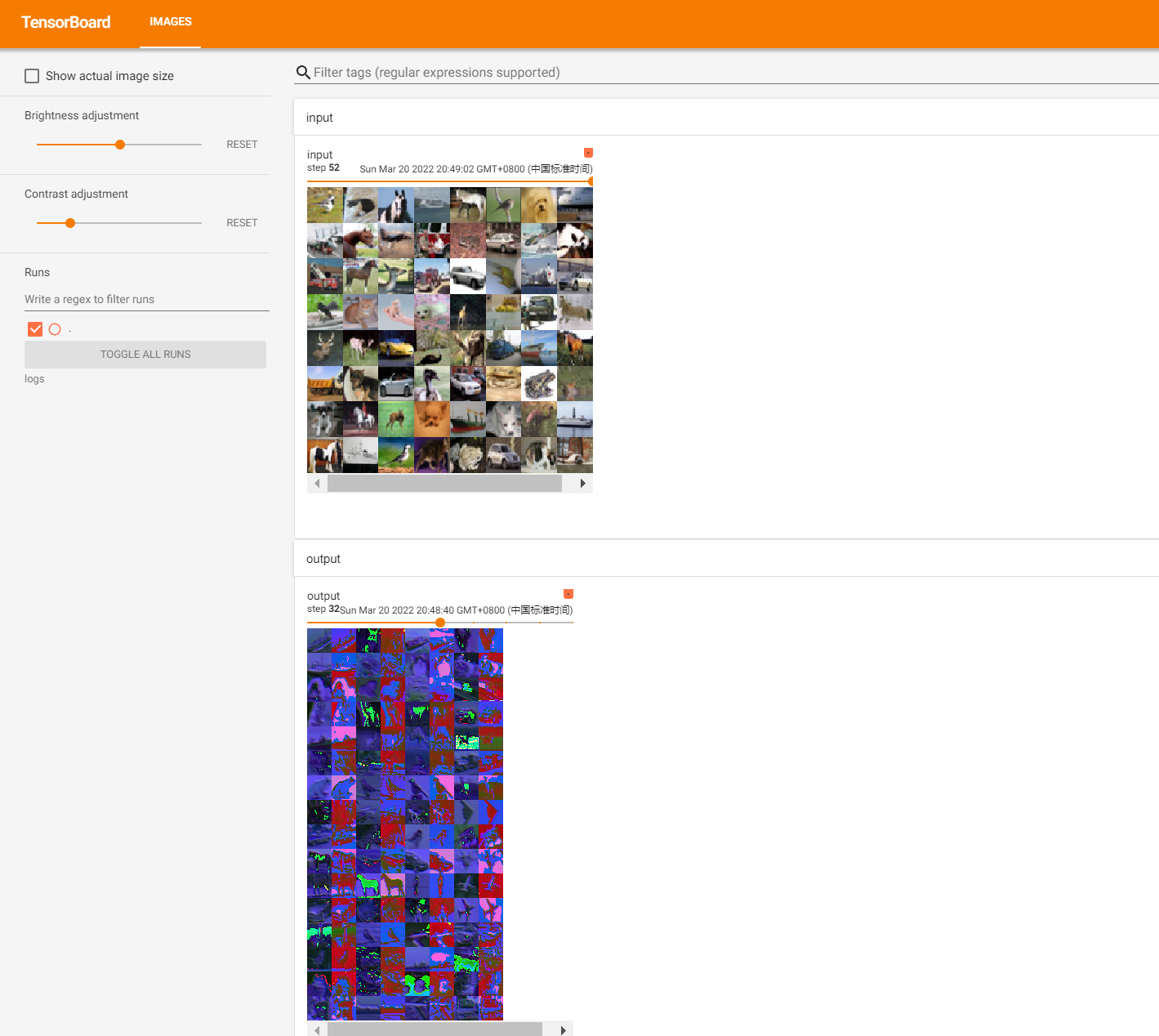
池化层
池化的作用就是在减少特征的同时保留明显的特征(不影响channel),减少训练时的 数据量
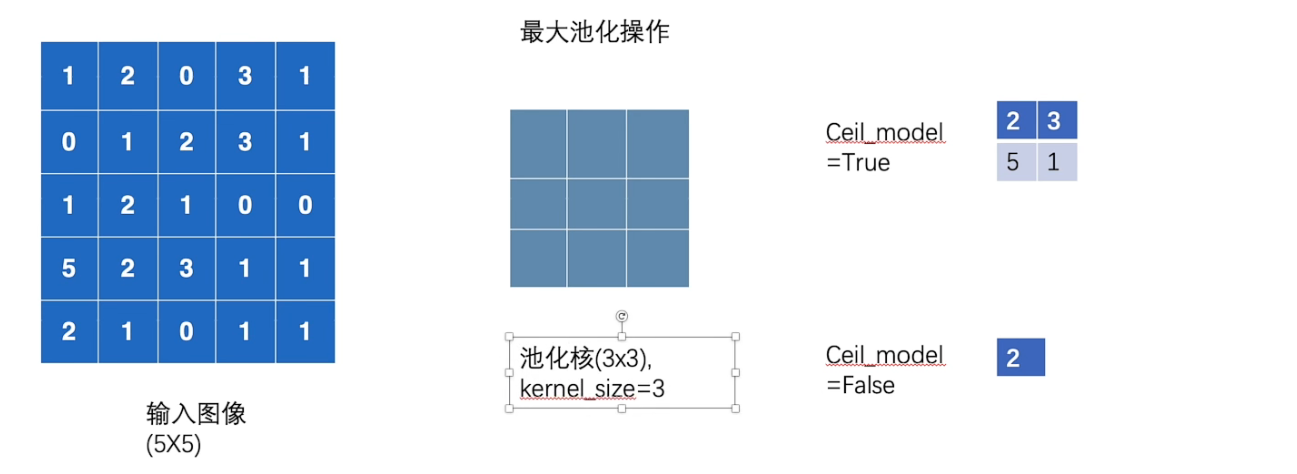
#encoding=utf-8
import torch
from torch import nn
from torch.nn import MaxPool2d
input = torch.tensor([[1,2,0,3,1],[0,1,2,3,1],[1,2,1,0,0],[5,2,3,1,1],[2,1,0,1,1]],dtype=torch.float32)
input = torch.reshape(input,(-1,1,5,5))
print(input.shape)# torch.Size([1, 1, 5, 5])
class MyNN(nn.Module):
def __init__(self):
super(MyNN, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,return_indices=False,ceil_mode=False)
def forward(self,input):
output = self.maxpool1(input)
return output
myNN = MyNN()
output = myNN(input)
print(output)#tensor([[[[2.]]]])#encoding=utf-8
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,download=True,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=64)
class MyNN(nn.Module):
def __init__(self):
super(MyNN, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,return_indices=False,ceil_mode=False)
def forward(self,input):
output = self.maxpool1(input)
return output
myNN = MyNN()
step = 0
writer = SummaryWriter("logs")
for data in dataloader:
imgs,targets = data
writer.add_images("input",imgs,step)
output = myNN(imgs)
writer.add_images("output",output,step)
step += 1
writer.close()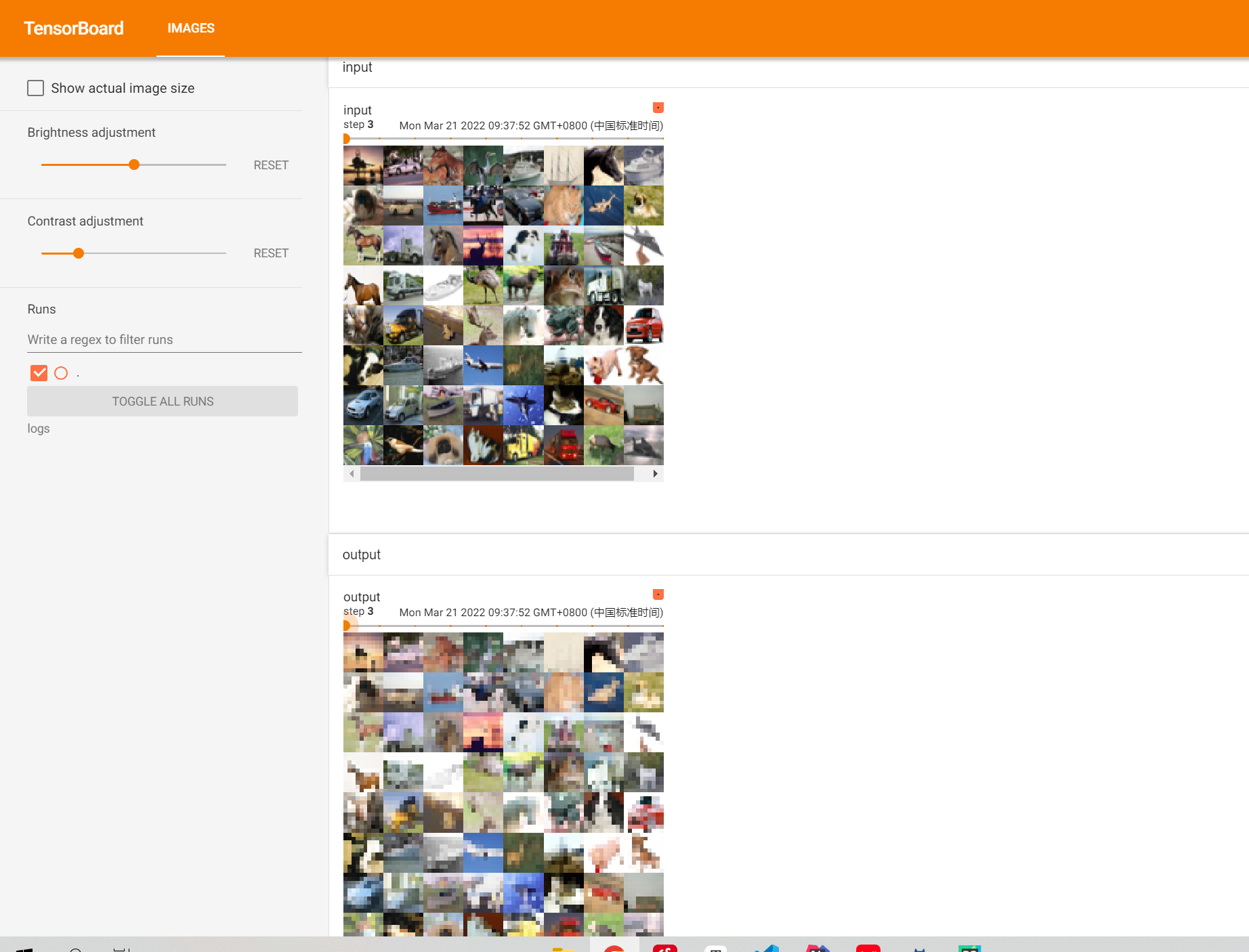
非线性激活
非线性变换的主要目的就是为我们的网络中引入一些非线性特征,非线性越多的话,才能训练出符合曲线和特征的模型(更强的泛化能力)
常见的激活函数
- ReLu
- Sigmoid
ReLu
#encoding=utf-8
import torch
from torch import nn
from torch.nn import ReLU
input = torch.tensor([[1,-0.5],[-1,3]])
input = torch.reshape(input,(-1,1,2,2))
print(input.shape)
class MyNN(nn.Module):
def __init__(self):
super(MyNN, self).__init__()
self.relu1 = ReLU()# inplace参数 :原地操作是否开启
def forward(self,input):
output = self.relu1(input)
return output
myNN = MyNN()
output = myNN(input)
print(output)Sigmoid
#encoding=utf-8
import torch
import torchvision
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,download=True,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=64)
class MyNN(nn.Module):
def __init__(self):
super(MyNN, self).__init__()
self.relu1 = ReLU()# inplace参数 :原地操作是否开启
self.sigmoid1 = Sigmoid()
def forward(self,input):
output = self.sigmoid1(input)
return output
myNN = MyNN()
step = 0
writer = SummaryWriter("logs")
for data in dataloader:
imgs,targets = data
writer.add_images("input",imgs,global_step=step)
output = myNN(imgs)
writer.add_images("output",output,step)
step += 1
writer.close()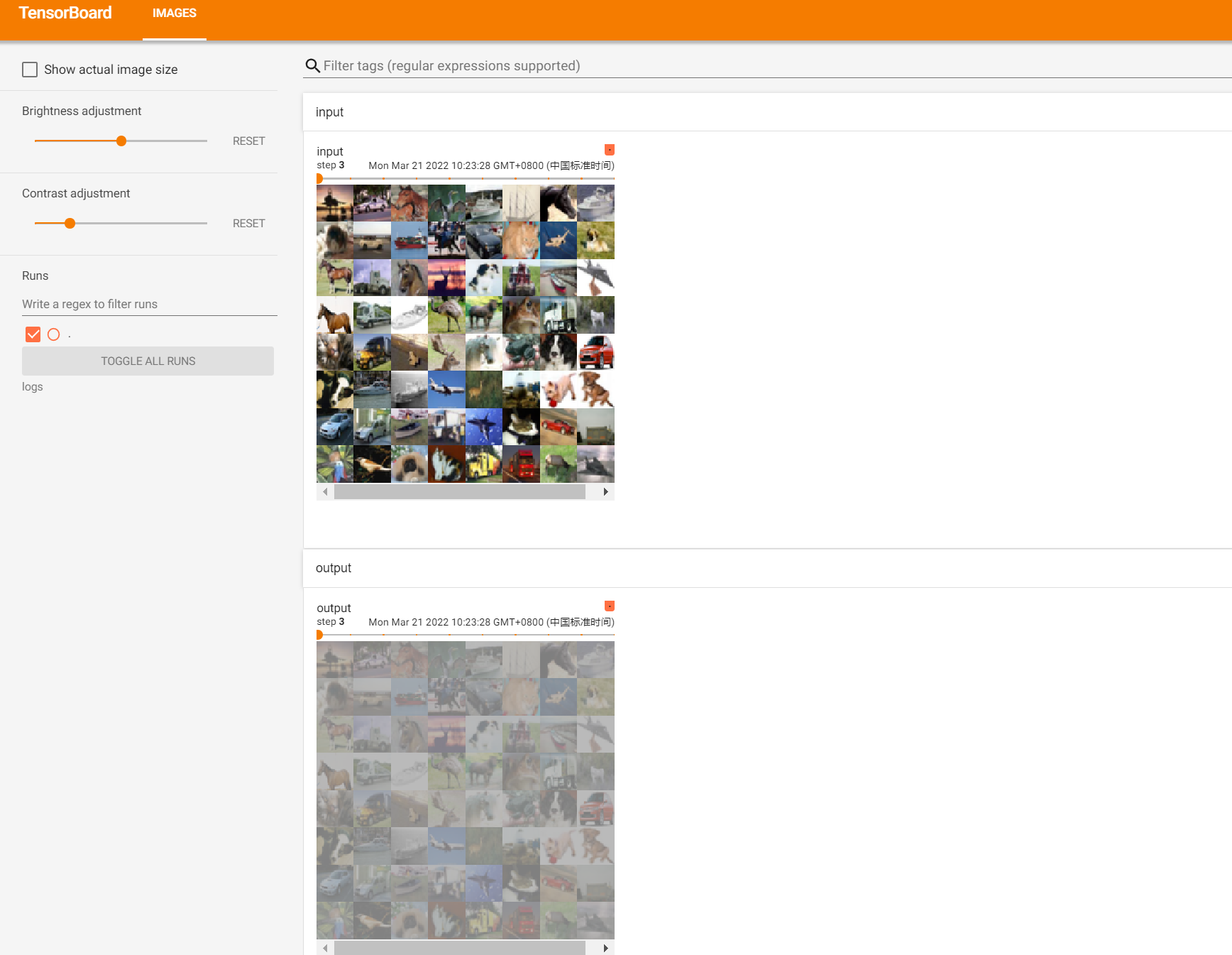
线性层(全连接层)
在CNN中,全连接常出现在最后几层,用于对于前面设计的特征做加权和,比如mnist,前面的卷积和池化相当于做特征工程,后面的全连接相当于做特征加权。(卷积相当于全连接的有意弱化,按照局部视野的启发,把局部之外的弱影响直接抹为0影响,还做了一点强制,不同的局部所使用的参数居然一致。弱化使参数变少,节省计算量,又专攻局部不贪多求全,强制进一步减少参数。在RNN中,全连接用来把embedding空间拉到隐层空间,把隐层空间转回label空间等。
#encoding=utf-8
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=64)
class MyNN(nn.Module):
def __init__(self):
super(MyNN, self).__init__()
self.linear1 = Linear(196608,10)
def forward(self,input):
output = self.linear1(input)
return output
myNN = MyNN()
step = 0
for data in dataloader:
imgs,targets = data
output = torch.reshape(imgs,(1,1,1,-1))
print(output.shape)# torch.Size([1, 1, 1, 196608])
output = myNN(output)
print(output.shape) # torch.Size([1, 1, 1, 10])损失函数和反向传播
计算Loss的作用:
- 计算实际输出和目标之间的差距
- 为我们更新输出提供一定的依据(反向传播)
L1LOSS

#encoding=utf-8
import torch
from torch.nn import L1Loss
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)
inputs = torch.reshape(inputs,(1,1,1,3))# batch-size = 1,channel = 1,height=1,width= 1
targets = torch.reshape(targets,(1,1,1,3))
loss1 = L1Loss()
loss2 = L1Loss(reduction="sum")
result1 = loss1(inputs,targets)
result2 = loss2(inputs,targets)
print(result1)# tensor(0.6667)
print(result2)# tensor(2.)MSELOSS

#encoding=utf-8
import torch
from torch.nn import L1Loss, MSELoss
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)
inputs = torch.reshape(inputs,(1,1,1,3))# batch-size = 1,channel = 1,height=1,width= 1
targets = torch.reshape(targets,(1,1,1,3))
loss_mse = MSELoss()
result3 = loss_mse(inputs,targets)
print(result3)# tensor(1.3333)CROSSENTROPYLOSS(交叉熵)
常在分类问题中用作loss函数[pytorch中,cross-entropy内嵌了softmax]

#encoding=utf-8
import torch
from torch import nn
from torch.nn import L1Loss, MSELoss
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)
x = torch.tensor([0.1,0.2,0.3])
y = torch.tensor([1])
x = torch.reshape(x,(1,3))
loss_cross = nn.CrossEntropyLoss()
result = loss_cross(x,y)
print(result)# tensor(1.1019)#encoding=utf-8
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10('./dataset',train=False,download=True,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=1)
class MyNN(nn.Module):
def __init__(self):
super(MyNN, self).__init__()
# self.conv1 = Conv2d(3,32,5,padding=2)
# self.maxpool1 = MaxPool2d(2)
# self.conv2 = Conv2d(32,32,5,padding=2)
# self.maxpool2 = MaxPool2d(2)
# self.conv3 = Conv2d(32,64,5,padding=2)
# self.maxpool3 = MaxPool2d(2)
# self.flatten = Flatten()
# self.linear1 = Linear(1024,64)
# self.linear2 = Linear(64,10)
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
# x = self.conv1(x)
# x = self.maxpool1(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.conv3(x)
# x = self.maxpool3(x)
# x = self.flatten(x)
# x = self.linear1(x)
# x = self.linear2(x)
x = self.model1(x)
return x
myNN = MyNN()
loss = nn.CrossEntropyLoss()
for data in dataloader:
imgs,targets = data
outputs = myNN(imgs)
result_loss = loss(outputs, targets)
result_loss.backward()
print(result_loss)优化器
根据梯度进行调整参数,已达到误差降低的目的
#encoding=utf-8
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10('./dataset',train=False,download=True,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=64)
class MyNN(nn.Module):
def __init__(self):
super(MyNN, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model1(x)
return x
myNN = MyNN()
loss = nn.CrossEntropyLoss()
optim = torch.optim.SGD(myNN.parameters(),0.01)
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
optim.zero_grad()
imgs,targets = data
outputs = myNN(imgs)
result_loss = loss(outputs, targets)
result_loss.backward()
optim.step()
running_loss = running_loss + result_loss
print(running_loss)out:
Files already downloaded and verified
tensor(360.2437, grad_fn=<AddBackward0>)
tensor(355.1202, grad_fn=<AddBackward0>)
tensor(339.6341, grad_fn=<AddBackward0>)
tensor(319.7515, grad_fn=<AddBackward0>)
tensor(308.4548, grad_fn=<AddBackward0>)
tensor(298.0671, grad_fn=<AddBackward0>)
tensor(289.0522, grad_fn=<AddBackward0>)
tensor(281.4933, grad_fn=<AddBackward0>)
...现有的网络模型及修改
vgg16
#encoding=utf-8
import torchvision
# train_data = torchvision.datasets.ImageNet("./dataset",split="train",download=True,transform=torchvision.transforms.ToTensor())
from torch import nn
vgg16_true = torchvision.models.vgg16(pretrained=True)
train_data = torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),
download=True)
# 添加
vgg16_true.classifier.add_module("add_linear1",nn.Linear(1000,10,True))
vgg16_true.add_module("add_linear2",nn.Linear(1000,10,True))
# 修改
vgg16_true.classifier[6] = nn.Linear(4096,10)
print(vgg16_true)
'''
Files already downloaded and verified
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=10, bias=True)
(add_linear1): Linear(in_features=1000, out_features=10, bias=True)
)
(add_linear2): Linear(in_features=1000, out_features=10, bias=True)
)
'''
网络模型的保存和读取
#encoding=utf-8
import torch
import torchvision
vgg16 = torchvision.models.vgg16(pretrained=True)
# 保存的方式1 模型结构+模型参数[方式1,在加载的时候有个小陷阱,就是必须事前声明好模型(已知)]
torch.save(vgg16,"vgg16_method1.pth")
# 加载模型1
model1 = torch.load("./vgg16_method1.pth")
# print(model1)
# 保存方式2 模型参数(官方推荐)
torch.save(vgg16.state_dict(),"vgg16_method2.pth")
# 加载模型2
dict = torch.load("./vgg16_method2.pth")
model2 = torchvision.models.vgg16(pretrained=True)
model2.load_state_dict(dict)
print(model2)完整的模型训练套路
MyNN.py —— 自己搭建的神经网络
import torch
from torch import nn
from torch.nn import Sequential
class MyNN(nn.Module):
def __init__(self):
super(MyNN, self).__init__()
self.model1 = Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self,x):
x = self.model1(x)
return x
# # 验证一下输出
# if __name__ == "__main__":
# myNN = MyNN()
# input = torch.ones((64,3,32,32))
# output = myNN(input)
# print(output.shape) # torch.Size([64, 10])train.py
#encoding=utf-8
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
import time
#1. 准备数据集
from torch import nn
from torch.nn import Sequential
from torch.utils.data import DataLoader
train_data = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
#length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size = 10,训练数据集长度为10
print("训练数据集长度为: {}".format(train_data_size)) # print(f"训练数据集长度为: {train_data_size}")
print("测试数据集长度为: {}".format(test_data_size))
#2. 利用DataLoader来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
#3. 搭建神经网络
class MyNN(nn.Module):
def __init__(self):
super(MyNN, self).__init__()
self.model1 = Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self,x):
x = self.model1(x)
return x
myNN = MyNN()
if torch.cuda.is_available():
myNN = myNN.cuda()
# 损失函数(最好封装到网络中去)
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.cuda()
# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(myNN.parameters(),lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 添加tensorboard
writer = SummaryWriter("./logs")
start_time = time.time()
# 训练的轮数
epoch = 10
for i in range(epoch):
print("----------第{}轮训练开始-----------".format(i+1))
# 训练步骤开始
myNN.train()
for data in train_dataloader:
imgs,targets = data
imgs = imgs.cuda()
targets = targets.cuda()
output = myNN(imgs)
loss = loss_fn(output,targets)
#优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
end_time = time.time()
print(end_time - start_time)
print("训练次数: {},loss = {}".format(total_train_step,loss.item()))
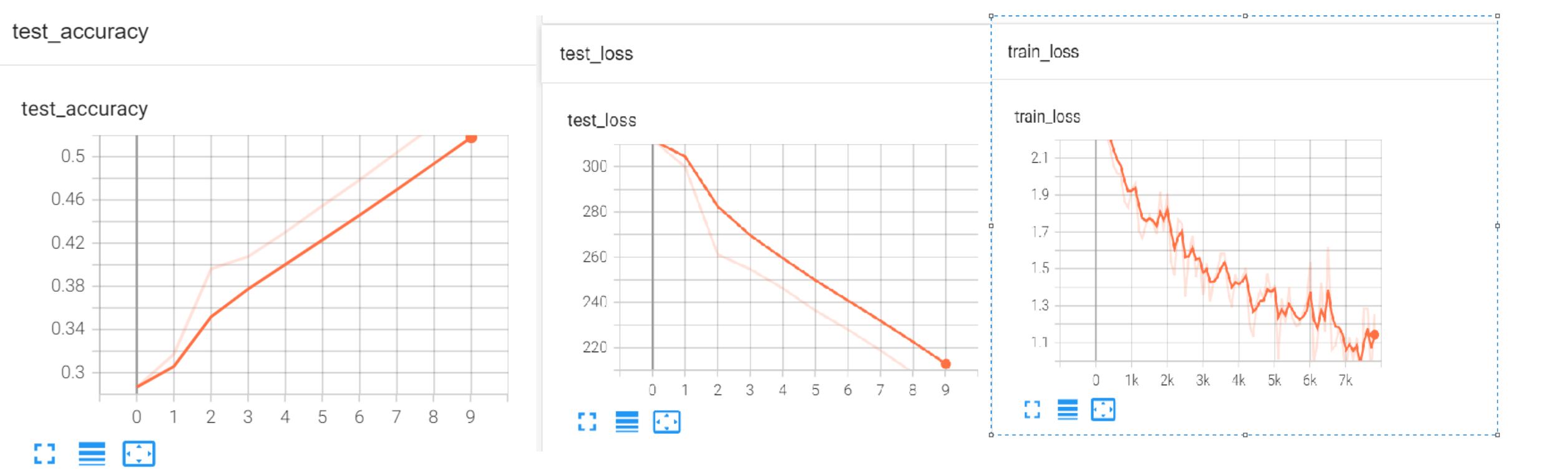
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始
myNN.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs,targets = data
imgs = imgs.cuda()
targets = targets.cuda()
outputs = myNN(imgs)
loss = loss_fn(outputs,targets)
total_test_loss += loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step += 1
torch.save(myNN,"myNN_{}.pth".format(i))
writer.close()
正确率

#encoding=utf-8
import torch
outputs = torch.tensor([[0.1,0.2],[0.3,0.4]])
preds = outputs.argmax(1) # 1是横向看 # tensor([1, 1])
targets = torch.tensor([0,1])
accuracy = (preds == targets).sum().item()
rate = accuracy/2.0
print("正确率为:{}".format(rate)) # 正确率为:0.5利用GPU训练
两种GPU训练方式
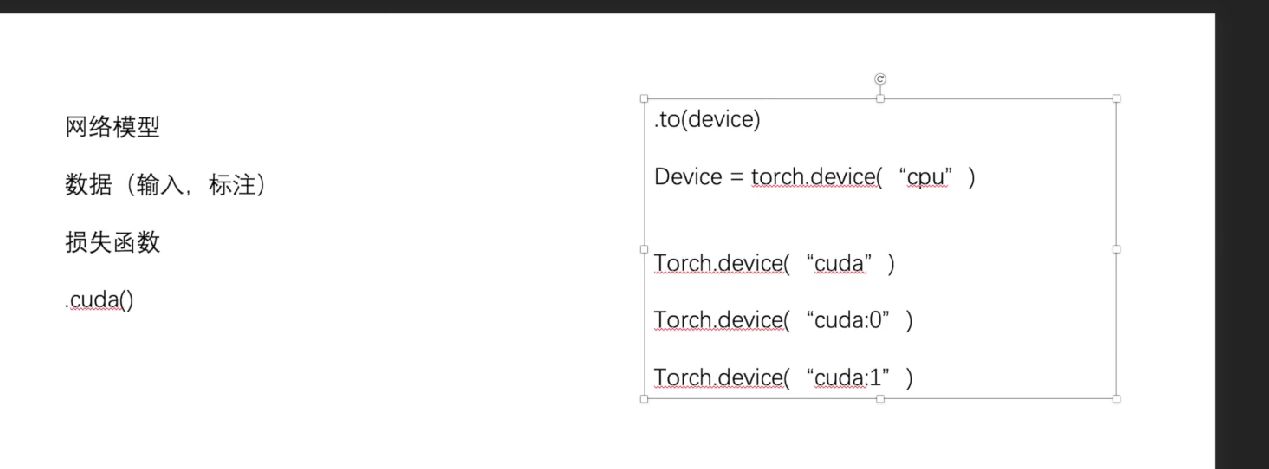
1.
if torch.cuda.is_available():
myNN = myNN.cuda()#网络,loss函数,数据都可以进行GPU加速2.
#定义训练的设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
myNN = myNN.to(device)完整的模型验证套路
利用已经训练好的模型,然后给它提供输入

test.py
#encoding=utf-8
import torch
import torchvision
from PIL import Image
from torch import nn
from torch.nn import Sequential
image_path = "../dataset/cat1.jpeg"
image = Image.open(image_path)
# print(image)
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),torchvision.transforms.ToTensor()])
image = transform(image)
# print(image)
device = torch.device("cuda")
class MyNN(nn.Module):
def __init__(self):
super(MyNN, self).__init__()
self.model1 = Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self,x):
x = self.model1(x)
return x
model = torch.load("myNN_81.pth")
model.to(device)
# print(model)
image = torch.reshape(image,(1,3,32,32)).to(device)
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))补充知识:
argmax

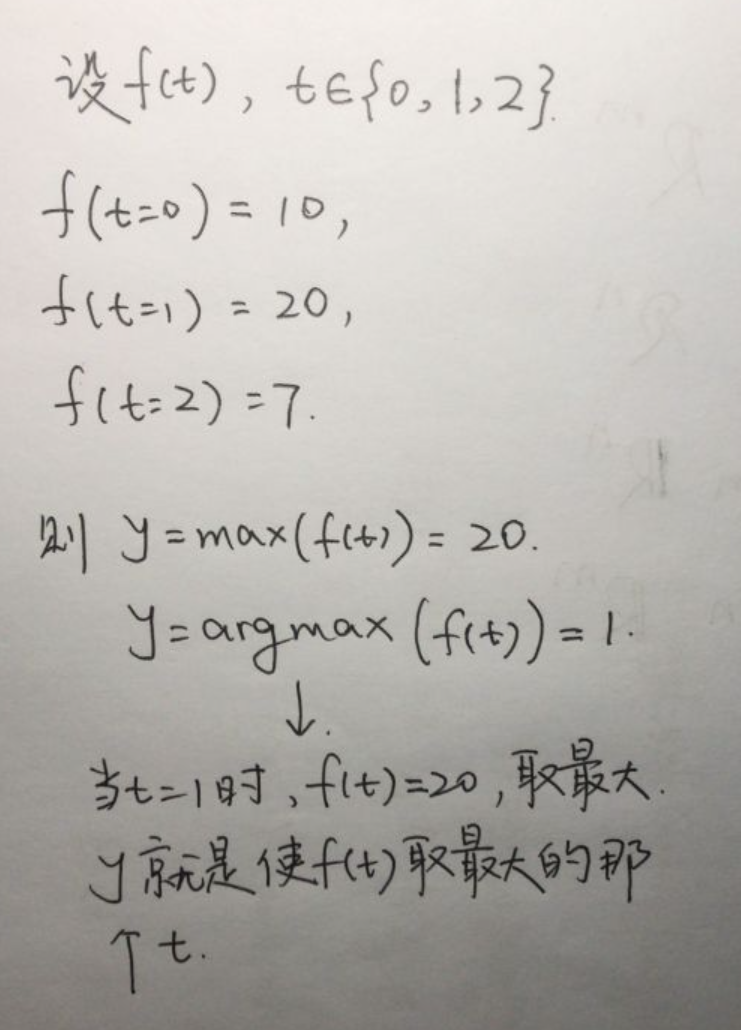
Softmax(概率)
在机器学习领域,多分类算法需要从一组可能的结果中找出概率最高的那个,正需要使用 max 函数。而为了能进行优化,用于描述问题的函数必须是可微分的,这样 softmax 就是一个非常合适的选择了。
softmax用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类!
假设我们有一个数组,V,Vi表示V中的第i个元素,那么这个元素的softmax值就是
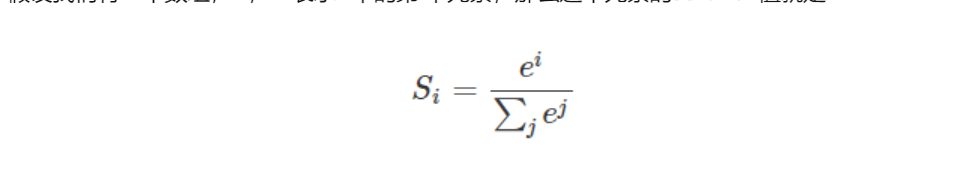
one-hot编码
定义
独热编码即 One-Hot 编码,又称一位有效编码。其方法是使用 N位 状态寄存器来对 N个状态 进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。
为什么需要one-hot编码?
one hot编码是将类别变量转换为机器学习算法易于利用的一种形式的过程。
上面的 hello world 相当于多分类的问题(27分类),每个样本只对应于一个类别(即只在对应的特征处值为1,其余地方值为0),而我们的分类结果,得到的往往是隶属于某个类别的概率,这样在进行损失函数(例如交叉熵损失)或准确率计算时,变得非常方便
one-hot编码的缺陷
one-hot编码要求每个类别之间相互独立,如果之间存在某种连续型的关系,或许使用distributed respresentation(分布式)更加合适
torch.manual_seed()
使用 :
为CPU中设置种子,生成随机数:
torch.manual_seed(number)
为特定GPU设置种子,生成随机数:
torch.cuda.manual_seed(number)
为所有GPU设置种子,生成随机数:
torch.cuda.manual_seed_all(number)
使用原因 :
在需要生成随机数据的实验中,每次实验都需要生成数据。设置随机种子是为了确保每次生成固定的随机数,这就使得每次实验结果显示一致了,有利于实验的比较和改进。使得每次运行该 .py 文件时生成的随机数相同。
示例:
# 需要注意不要在终端中单行敲入运行如下代码,要将如下代码先拷贝到 *.py 文件中,再在终端命令中通过 python *.py 运行
import torch
if torch.cuda.is_available():
print("gpu cuda is available!")
torch.cuda.manual_seed(1000)
else:
print("cuda is not available! cpu is available!")
torch.manual_seed(1000)
print(torch.rand(1, 2))numpy
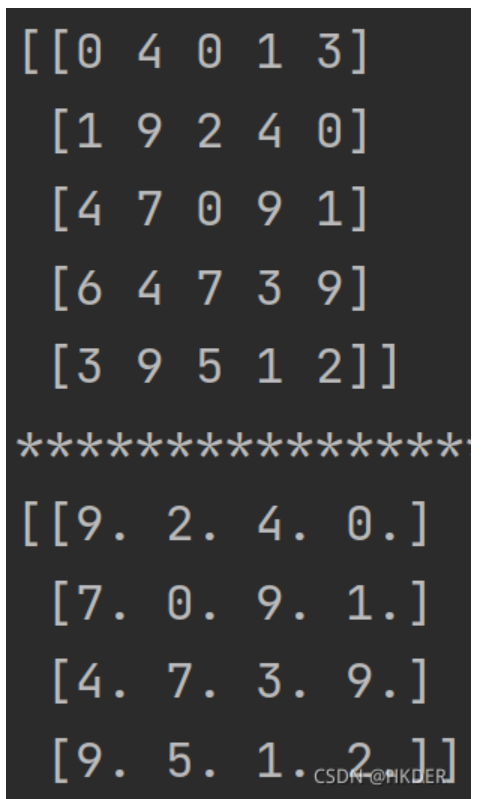
数据数组去除第一行和第一列data = np.array(data[1:])[:, 1:]
import numpy as np
data = np.random.randint(0,10,(5,5))
print(data)
print('*******************************')
data1 = np.array(data[1:])[:, 1:].astype(float)
print(data1)结果: