Gym入门使用教程
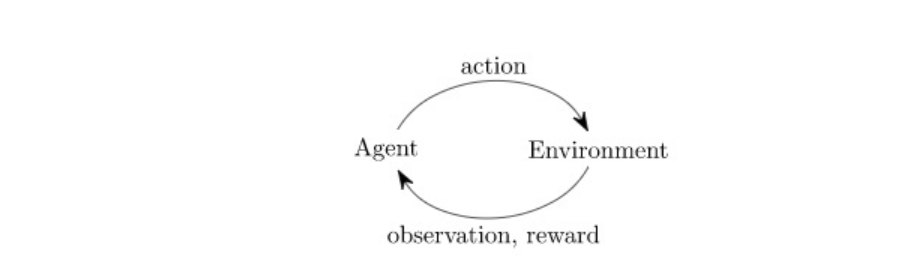
The Gym interface is simple, pythonic, and capable of representing general RL problems:
import gym
env = gym.make("LunarLander-v2")
observation, info = env.reset(seed=42)
for _ in range(1000):
env.render()
action = policy(observation) # User-defined policy function
observation, reward, done, info = env.step(action)
if done:
observation, info = env.reset()
env.close()基础
一,激活environment,查看环境基本信息
env.observation_space 得到state信息,是一个Box类,
env.observation_space.shape 得到state的shape
env.action_space 得到action的信息,是一个Discrete类
env.action_space.n 得到action的个数
import gym,time
import random
import numpy as np
#初始化环境这里选择三个不同类别的环境
env1 = gym.make('LunarLander-v2')
env2 = gym.make('Pong-v0')
env3 = gym.make('CartPole-v0')
#查看环境状态
#可以看到观察环境空间状态信息,主要是环境相关矩阵,一般是一个box类
print(env1.observation_space, type(env1.observation_space))
print(env2.observation_space, type(env2.observation_space))
print(env3.observation_space, type(env3.observation_space))
#返回的是离散action空间的值
print(env1.action_space, type(env1.action_space))
print(env2.action_space, type(env2.action_space))
print(env3.action_space, type(env3.action_space))
#LunarLander-v2的state shape和action space大小
print(env1.observation_space.shape, env1.action_space.n)
#Pong-v0的state shape和action space大小
print(env2.observation_space.shape, env2.action_space.n)二,使用reset初始化environment,查看state信息(换个游戏场景)
state1 = env1.reset()
state2 = env2.reset()
state3 =env3.reset()三,执行action并使用render可视化
这里主要使用env.setp来执行,输入值为一个action的序号。返回值为new state,action reward,action terminal bool 和一个其他信息
state = env1.reset()
env1.render()
new_state, reward, done, info = env1.step(0)
print(reward, done, info)四,如何执行完一个episodic
env = gym.make('CartPole-v0')
for i_episode in range(20):
observation = env.reset() #初始化环境每次迭代
for t in range(100):
env.render() #显示
print(observation)
action = env.action_space.sample() #随机选择action
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} timesteps".format(t+1))
break
env.close()环境
自定义环境
import gym
%matplotlib inline
from matplotlib import pyplot as plt
#gym.version==0.26
#定义环境
class MyWrapper(gym.Wrapper):
def __init__(self):
env = gym.make('CartPole-v1', render_mode='rgb_array')
super().__init__(env)
self.env = env
self.step_n = 0
def reset(self):
state, _ = self.env.reset()
self.step_n = 0
return state
def step(self, action):
state, reward, done, _, info = self.env.step(action)
#一局游戏最多走N步
self.step_n += 1
if self.step_n >= 200:
done = True
return state, reward, done, info
env = MyWrapper()
env.reset()
#认识游戏环境
def test_env():
print('env.observation_space=', env.observation_space)
print('env.action_space=', env.action_space)
state = env.reset()
action = env.action_space.sample()
next_state, reward, done, _ = env.step(action)
print('state=', state)
print('action=', action)
print('next_state=', next_state)
print('reward=', reward)
print('done=', done)
test_env()
#打印游戏
def show():
plt.figure(figsize=(3, 3))
plt.imshow(env.render())
plt.show()
show()Classic Control
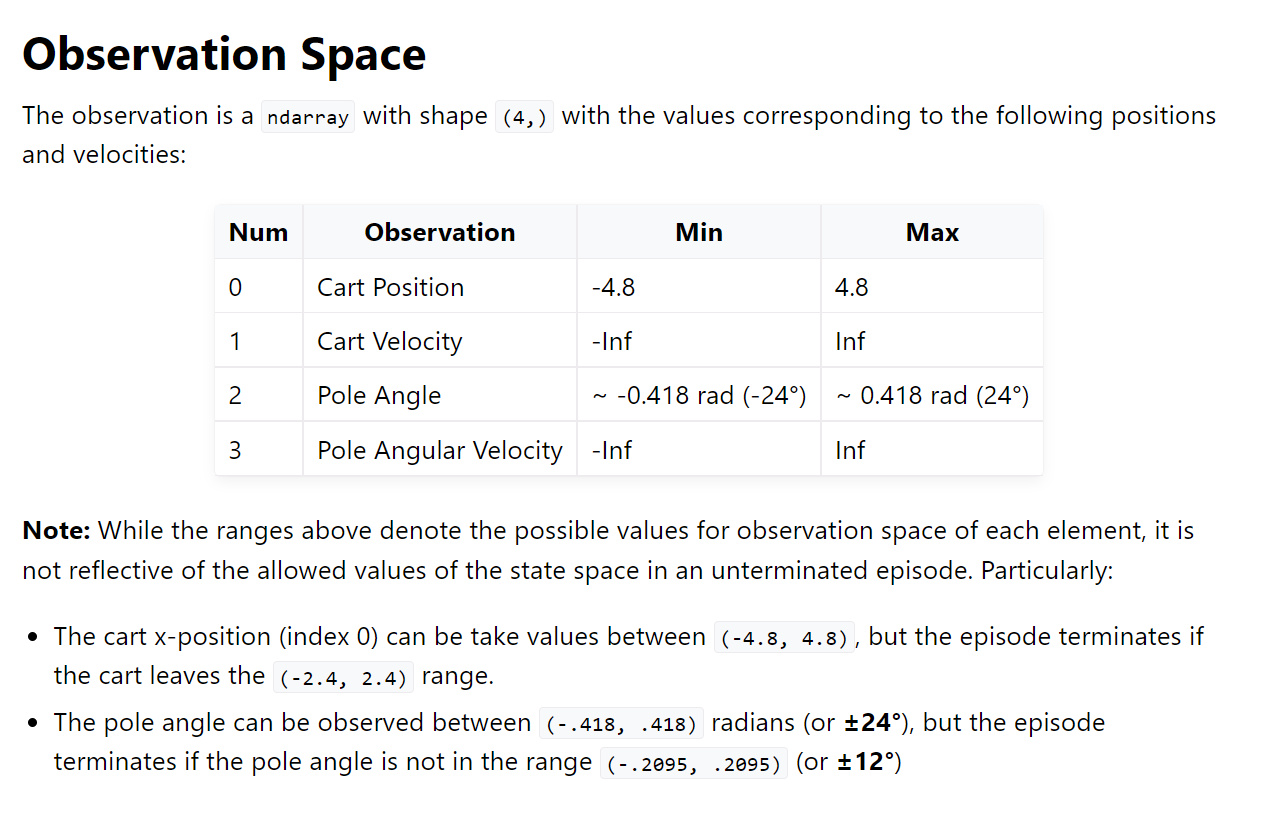
Cart Pole
| Action Space | Discrete(2) |
|---|---|
| Observation Shape | (4,) |
| Observation High | [4.8 inf 0.42 inf] |
| Observation Low | [-4.8 -inf -0.42 -inf] |
| Import | gym.make("CartPole-v1") |




Mountain Car Continuous
| Action Space | Box(-1.0, 1.0, (1,), float32) |
| Observation Shape | (2,) |
| Observation High | [0.6 0.07] |
| Observation Low | [-1.2 -0.07] |
| Import | gym.make("MountainCarContinuous-v0") |






