如何读论文?
绝大部分文章结构
1.title -> 2.abstract -> 3.introduction -> 4.method -> 5. experiment -> 6.conclusion
读论文是要快速找到适合自己的文章,然后进行精读
方法:怎么样花三遍读一篇论文。
第一遍:(海选)
需要关注论文的标题和摘要,读完摘要之后直接跳到论文结论部分。也可以看一下文章中的图和表,知道论文的工作是在做什么,方法看上去怎么样,结果怎么样。整个过程大概十几分钟的时间,看适不适合自己,决定是不是要继续往下读。
第二遍:(精选)
对整个文章过一遍,知道文章具体在做什么东西,不用太过关注文章的细节,比如公式证明什么的,可以先忽略掉。但是对于每一张图和表,它的每一个字你都要知道他是在做什么,它的x轴,y轴你都要知道是什么意思;明白作者提出的方法和别人的方法是怎么对比的,之间的差距有多大。对于一些引用的重要文献可以圈出来(比如是在哪篇论文的基础上)。决定要不要继续往下精读,如果你感觉文章太难,可以去读一下这边论文引用的一些文章。如果是不需要了解那么深,不需要完全搞懂论文,可以不读第三遍。
第三遍:(精读)
这一遍要知道每一句话在说什么,每一段在说什么。多思考,多脑补。
NOTE:
可以边读,边记录,同时做ppt将自己读到的内容尽量的浓缩
RL
Playing Atari with Deep Reinforcement Learning
tag:dqn
Abstract
用dqn训练Arcade 2600种游戏,在其中6个游戏中超越之前所有的算法,在其中三个游戏中超过人类专家。
Introduction
网络结构,卷积神经网络提取原始像素特征
应用算法,Q-learning变体————DQN
优化器,SGD
技巧,经验回放(experience replay mechanism)
Background
目标是让智能体选择动作与模拟器交互从而最大化未来的奖励,做了一个假设是未来的奖励会以每步$\gamma$ 进行折扣,并定义时间t的回报为
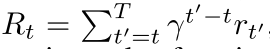
其中$T$是游戏终止的时长
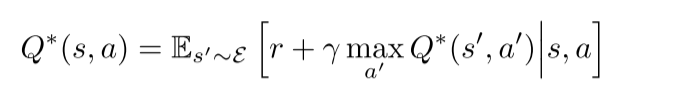
$\epsilon $-greedy strategy:follows the greedy strategy with probability 1 − $\epsilon $ and selects a
random action with probability $\epsilon $ .
Deep Reinforcement Learning

相比Q-Learning算法的优点:
(1)每一步经验可能更新许多权重,这增加了数据利用率
(2打断了数据之间的关联性,减小方差,获得更好的训练效果
(3)第三,在学习策略时,当前参数决定了训练参数的下一个数据样本。 例如,如果最大化动作是向左移动,那么训练样本将由左侧的样本支配,如果最大化动作然后切换到右侧,那么训练分布也将切换。
Preprocessing and Model Architecture
CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING
tag: ddpg,model-free, off-policy,actor-critic
1 INTRODUCTION
DQN的出现时强化学习领域一个大的进展,它用深度神经网络来近似最优价值动作函数,通过动作价值函数来寻找价值最大的动作,但是它的缺点是不适合应用在连续控制上,尽管可以通过将动作离散化,但是也会面临高维灾难:即动作的数量会随着自由度的增加呈现指数型增长。
这篇论文是基于 deterministic policy gradient (DPG) algorithm,DPG中对于具有挑战性的问题,这种带有神经函数近似器的actor-critic朴素应用是不稳定的。本文将actor-critic算法与DQN中的一些方法结合起来使用,
dqn能够stable and robust(稳定和鲁棒)的训练价值网络,归因于两个创新:
1.经验回放。建立一个缓冲区:replay buffer ,从replay buffer中采样用off-policy方式训练网络会减小样本间的相关性
2.为了缓解高估问题(TD算法中),在用TD算法训练网络不是用Q Network,而是用一个target Q network来训练。
本文同样使用了Batch Normalization
2 BACKGROUND
$J=\mathbb{E}_{r_i, s_i \sim E, a_i \sim \pi}\left[R_1\right]$
$R_t=\sum_{i=t}^T \gamma^{(i-t)} r\left(s_i, a_i\right)$
$Q^\pi\left(s_t, a_t\right)=\mathbb{E}{r{i \geq t}, s_{i>t} \sim E, a_{i>t} \sim \pi}\left[R_t \mid s_t, a_t\right]$
$\left(s_t, a_t, r_t, s_{t+1}\right)$
序列:At each timestep t the agent receives an observation xt, takes an action at and receives a scalar reward rt.
Here, we assumed the environment is fully-observed so st = xt.
An agent’s behavior is defined by a policy, π, which maps states to a probability distribution over the actions π : S → P(A).We model it as a ==Markov decision process(MDP)== with a state space S, action space A = $ \mathbb{R}^N$, an initial state distribution p(s1), transition dynamics p(st+1|st,at), and reward function r(st, at).


Bellman equation:
$Q^\pi\left(s_t, a_t\right)=\mathbb{E}{r_t, s{t+1} \sim E}\left[r\left(s_t, a_t\right)+\gamma \mathbb{E}{a{t+1} \sim \pi}\left[Q^\pi\left(s_{t+1}, a_{t+1}\right)\right]\right]$
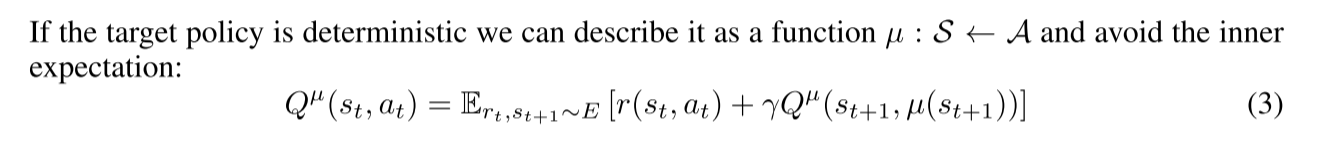
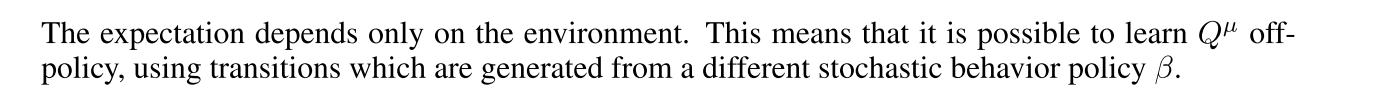

3 ALGORITHM

遇到挑战:
1.假设 独立同分布。when using neural networks for reinforcement learning is that most optimization algorithms assume that the samples are independently and identically distributed。Obviously, when the samples are generated from exploring sequentially in an environment this assumption no longer holds(显然,当样本是在一个环境中连续探索产生的时,这个假设就不再成立了)
Additionally, to make efficient use of hardware optimizations, it is essential to learn in mini-
batches, rather than online.
解决方法:经验回放。设置一个replay buffer(replay buffer是一个容量为$R$的高速缓存)。 根据探索策略从环境中采样转换,并将元组$\left(s_t, a_t, r_t, s_{t+1}\right)$存储在replay buffer 中。当buffer容量满时,就丢弃最 旧的样本,At each timestep the actor and critic are updated by sampling a minibatch ==uniformly==from the buffer.
Because DDPG is an off-policy algorithm, the replay buffer can be large, allowing the algorithm to benefit from learning across a set of uncorrelated transitions.(?)
2.高估问题。用神经网络直接实现Q学习(方程4)在许多环境中被证明是不稳定的。使用target network,不过改进是用soft target network。
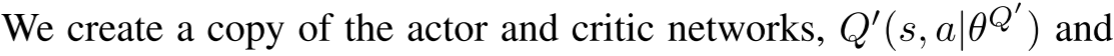
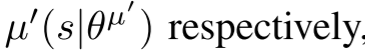
$\theta^{\prime} \leftarrow \tau \theta+(1-\tau)\theta^{\prime}$
采用部分更新和软更新的方式能大大提高训练稳定性,但是也会因此产生训练缓慢的问题,不过在实际中训练的稳定性的重要性可以忽略掉这一点。
3.不同特征含义有不同的含义,变化范围不一样,很难找到一个泛化的超参数。解决方法,BN。将每个维度分别就行归一化,用均值和方差。在测试的时候,是维护一个均值和方差的平均。
4.A major challenge of learning in continuous action spaces is exploration.An advantage of off- policies algorithms such as DDPG is that we can treat the problem of exploration independently
from the learning algorithm.
We constructed an exploration policy µ by adding noise sampled from a noise process N to our actor policy $\mu^{\prime}\left(s_t\right)=\mu\left(s_t \mid \theta_t^\mu\right)+\mathcal{N}$

4 RESULTS
BN(浅灰色)的原始DPG算法(Minibatch NFQCA)
带target network(深灰色)的原始DPG算法
以target network和BN(绿色)、
target network仅像素输入(蓝色)
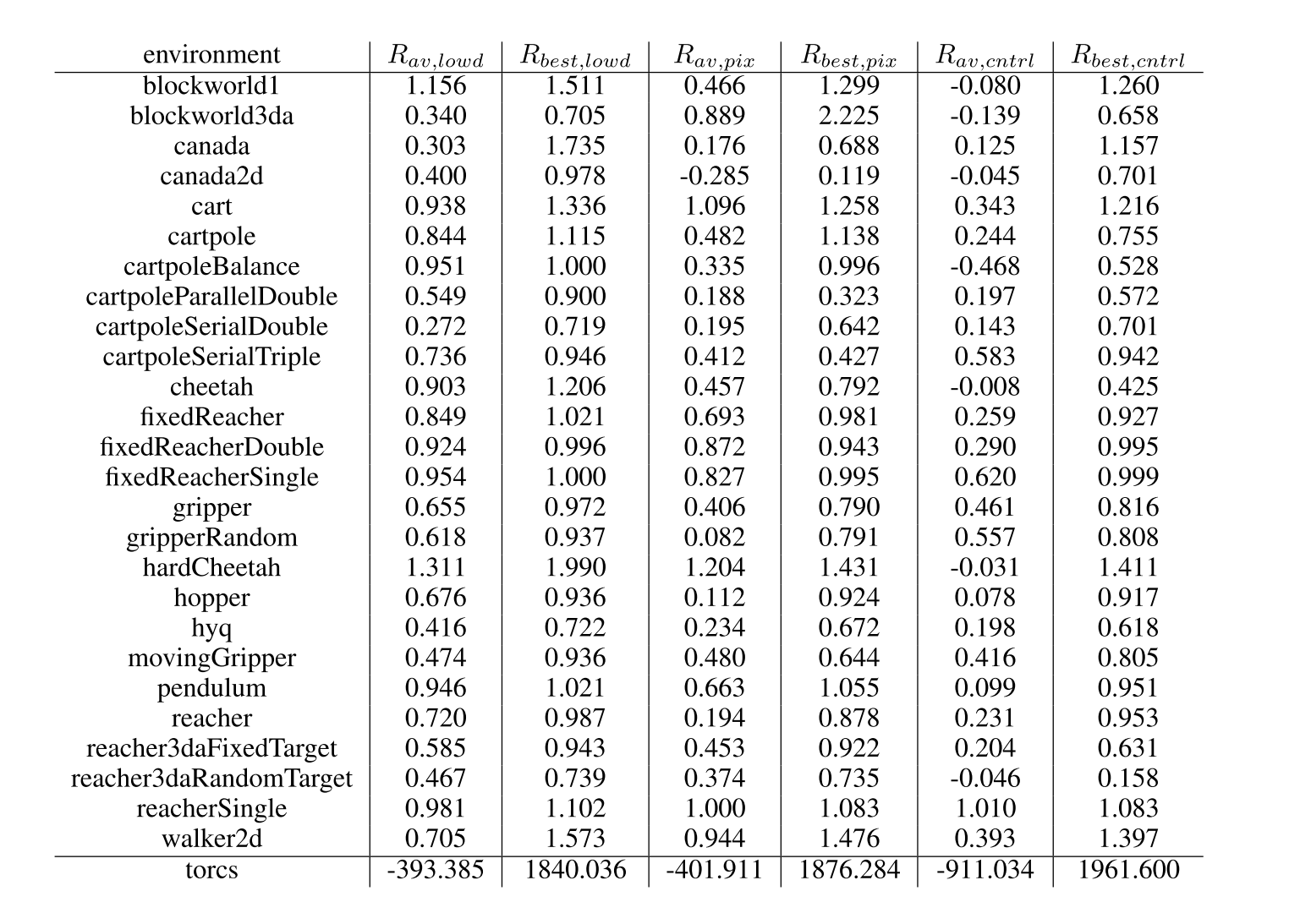
6 CONCLUSION
The work combines insights from recent advances in deep learning and reinforcement learning, resulting in an algorithm that robustly solves challenging problems across a variety of domains with continuous action spaces, even when using raw pixels for observations
Cross-Domain Adaptive Transfer Reinforcement Learning Based on State-Action Correspondence
tag:transfer RL
Abstract
以往的工作大多考虑具有相同状态-动作空间的任务之间的TL,而在具有不同状态-动作空间的领域之间的迁移则相对较少。此外,这种现有的跨域传输方法只允许从单个源策略进行传输,留下了如何从多个源策略进行最佳传输的重要问题。本文提出了一种新的框架Cross-domain Adaptive Transfer (CAT)来加速DRL。CAT学习每个源任务到目标任务的状态-动作对应关系,并自适应地将多个源任务策略的知识转移到目标策略。实验结果表明,在多个连续动作控制任务上,CAT算法能显著地加快学习速度,优于其他跨域迁移算法。项目的代码发布在https://github.com/tju-drl-lab/transfer-andmulti-task-restruction-learning的项目页面下。
1 INTRODUCTION
尽管DRL在很多领域都获得了成功,但是仍然面临着采样效率低下的问题,需要与环境进行大量交互。迁移学习(TL)作为一种利用先验知识加速学习过程的技术,已成为显著降低样本复杂度的研究方向之一。
RL中迁移的一个主要分支侧重于利用来自预先训练的源任务策略的外部知识,我们称之为策略转移(policy transfer)。这些方法要么通过模仿学习从源策略中提取知识,或者基于对目标环境的源策略的评估重用源策略进行探索。然而,所有这些方法都需要相同的假设,即源任务与目标任务共享相同的状态-动作空间,以便可以直接模仿或重用源策略。
训练state encoder
本文解决了学习从具有不同状态-动作空间的多个任务转移的更困难的情况。
我们提出了一种新的跨域自适应传输框架(CAT),它可以自适应地传输具有不同状态-动作空间的多个源策略
与以往的工作不同,我们不需要配对数据来学习状态-动作对应关系,也不需要学习训练不足的状态对应关系,相反,CAT通过使用源策略轨迹的状态编码器、动作编码器和反向状态编码器来学习从每个源域到目标域的状态-动作对应关系。由于无法访问源环境以获取更多信息,因此我们不需要反向操作编码器来获取源环境上的操作。此外,CAT评估目标任务上的每个源策略,并了解每个源策略对目标策略的帮助程度,然后使用性能作为度量来确定何时以及哪些源策略应该被转移
主要贡献:
- 本文提出的转移框架CAT由Agent模块、自适应模块和修正模块三个主要部分组成,以解决具有不同状态-动作空间的多源策略的自适应知识转移问题。
- CAT使用修正模块和代理模块学习更充分训练的状态嵌入和动作嵌入,作为后续传输过程的基础。
- CAT使用自适应模块生成的自适应加权因子将来自源策略网络的知识与目标策略网络相结合。
- CAT算法与已有的DRL算法很容易结合,实验结果表明,在不同状态-动作空间的连续控制任务中,CAT算法有效地加速了RL算法,并优于其他相关的转移算法。
2 BACKGROUND
策略梯度(PG)算法。 策略梯度法被广泛应用于直接优化以θ为参数的策略π。 近程政策优化(PPO,Schulman et al.[2017])是目前最高效的PG方法之一。
同域迁移学习问题,

跨域迁移学习

这篇论文考虑了多个源任务与一个目标任务之间的跨域转移问题。
我们通常假设MDP之间有一些高层次的共性(例如,四足、六足和八足机器人可能有质量相似的步态)
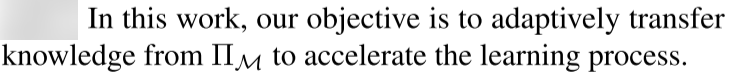
3 METHODOLOGY
在本节中,我们首先介绍我们的整个框架和每个组件。 然后,我们描述了如何学习状态和动作嵌入,以及如何自适应地将多个跨域源策略转移到目标任务。 最后,我们详细描述了CAT与一种特定的DRL算法PPO[Schulman et al.,2017]的结合
3.1 FRAMEWORK OVERVIEW
Correction Module
The goal of the correction module is to learn embeddings to distill knowledge
from multiple source policies into the target task.
Self-Adaptation Module
3.2 LEARNING STATE-ACTION CORRESPONDENCE
3.3 ADAPTIVE POLICY TRANSFER
3.4 CAT-PPO

4 EXPERIMENTS
()
Adversarially Trained Actor Critic for Offline Reinforcement Learning
Prior Work
To address such a challenge, the recent works (Fujimoto et al., 2019; Laroche et al., 2019; Jaques et al., 2019; Wu et al., 2019; Kumar et al., 2019, 2020; Agarwal et al., 2020b; Yu et al., 2020; Kidambi et al., 2020; Wang et al., 2020c; Siegel et al., 2020; Nair et al., 2020; Liu et al., 2020) demonstrate the empirical success of various algorithms, which fall into two (possibly overlapping) categories: ==(i) regularized policy-based approaches==and ==(ii) pessimistic value-based approaches==. Specifically, (i) regularizes (or equivalently, constrains) the policy to avoid visiting the states and actions that are less covered by the dataset, while (ii) penalizes the (action- or state-) value function on such states and actions.
In offline/batch reinforcement learning (RL), the predominant class of approaches with most success have been “==support constraint==” methods, ==where trained policies are encouraged to remain within the support of the provided offline dataset==.However, support constraints correspond to an overly pessimistic assumption that actions outside the provided data may lead to worst-case outcomes.
Offline RL的解决思路无外乎就是“悲观”二字,也就要想办法对OOD action进行低估,不要让策略走到没见到过的动作上去。为了实现这种悲观,实际的算法大体分为两种思路:一种是把OOD action的值直接拉低,代表性的方法就是CQL;另一种是让被训练的策略和采样策略不要差得太远,这类方法有AWAC,TD3+BC等。
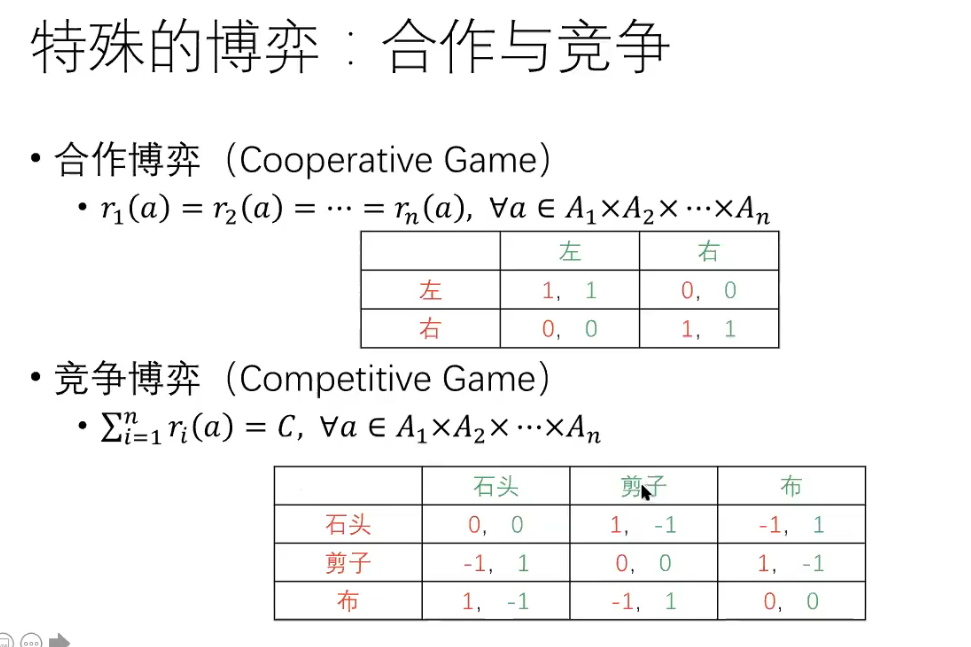
Stackelberg Game,即斯塔克伯格博弈,是一个两阶段的完全信息动态博弈,博弈的time是序贯的。主要思想是双方都是根据对方可能的策略来选择自己的策略以保证自己在对方策略下的利益最大化,从而达到纳什均衡。在该博弈模型中,先作出决策的一方被称为leader,在leader之后,剩余的players根据leader的决策进行决策,被称为followers,然后leader再根据followers的决策对自己的决策进行调整,如此往复,直到达到纳什均衡。(斯塔克伯格博弈(Stackelberg game)是一种博弈理论中的概念,是一种多人博弈的形式,在这种博弈中,有一个明确的领导者(称为领导者)和若干个追随者(称为追随者)。领导者先决策,然后追随者决策。领导者考虑追随者的反应,试图通过最优决策来最大化自己的利益。追随者则根据领导者的决策来决策,试图最大化自己的利益。
斯塔克伯格博弈的应用广泛,如市场竞争、广告定价、生产决策等。在实际应用中,斯塔克伯格博弈可以帮助我们了解决决策者之间的博弈关系,从而帮助决策者做出更好的决策。)
零和博弈是一种博弈理论的概念,它指的是一种博弈模型,在这种模型中,双方的利益是对立的,每个人的目的是赢得比对手多的利益,换句话说,没有公共利益可以分享。因此,在零和博弈中,一个人的胜利必须是另一个人的失败。零和博弈是研究博弈策略和决策理论的重要工具,广泛应用于经济学、政治学、军事学和生物学等领域。
深度离线强化学习(deep offline RL)可以通过利用深度神经网络和巨大的离线数据集,在没有任何环境交互的情况下训练强大的agent,但是训练得到的offline RL agents可能是次优的,因为offline datasets可能是次优的,另外,agent部署的环境可能与生成offline datasets的环境不同,这就需要一个在线微调(online fine-tuning)过程,agent通过在线收集更多的样本来改进。
但是使用传统的off-policy RL算法微调offline RL agent比较困难,因为存在distribution shift,agent会遇见offline dataset中没有的state-action,即out-of-distribution (OOD) online samples,Q函数在这样的state-action上无法给出准确的估计,导致严重的bootstrap error,从而使策略在任意方向上更新,破坏了offline RL获得的良好初始策略



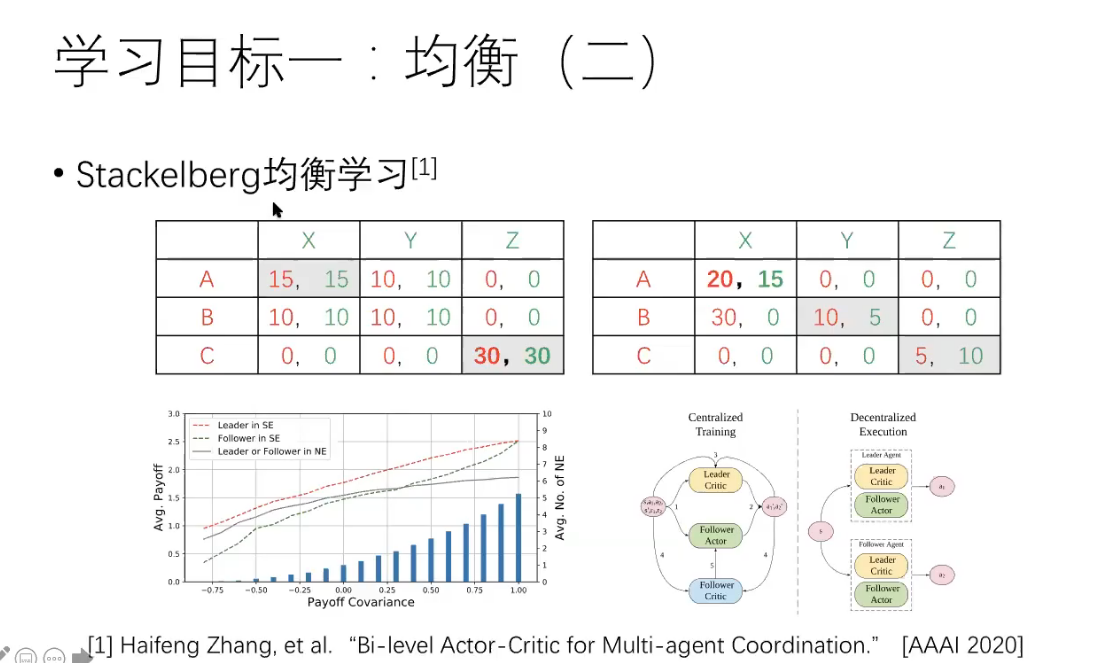
Bi-level Actor-Critic for Multi-agent Coordination
https://arxiv.org/abs/1909.03510
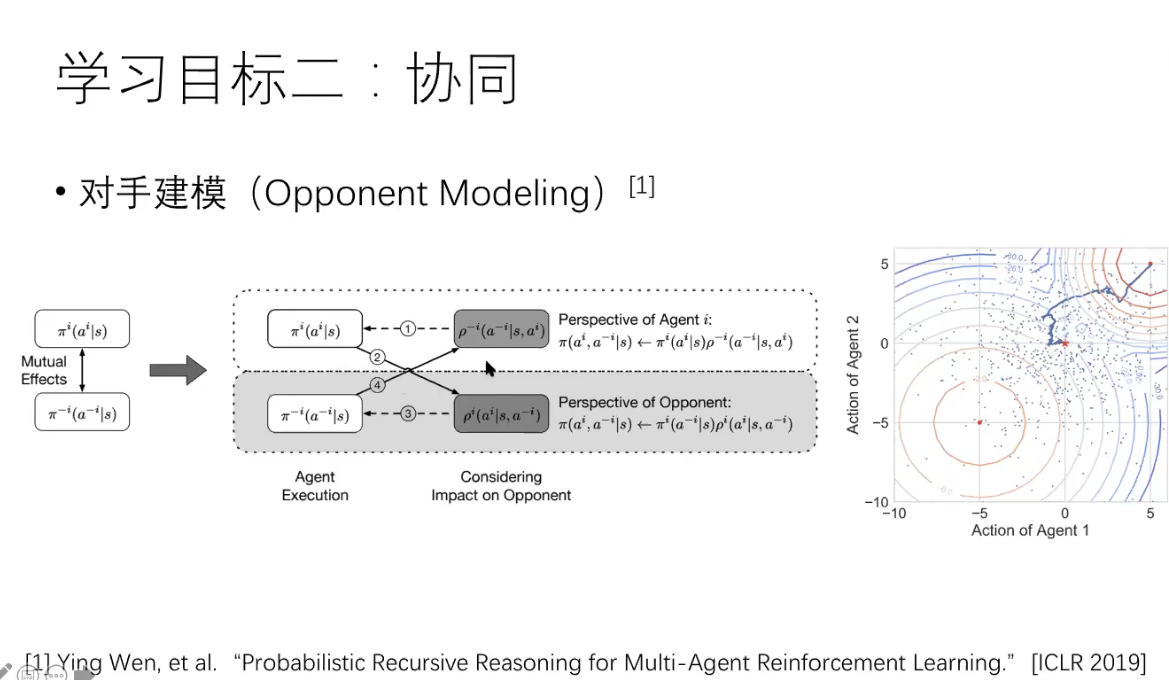

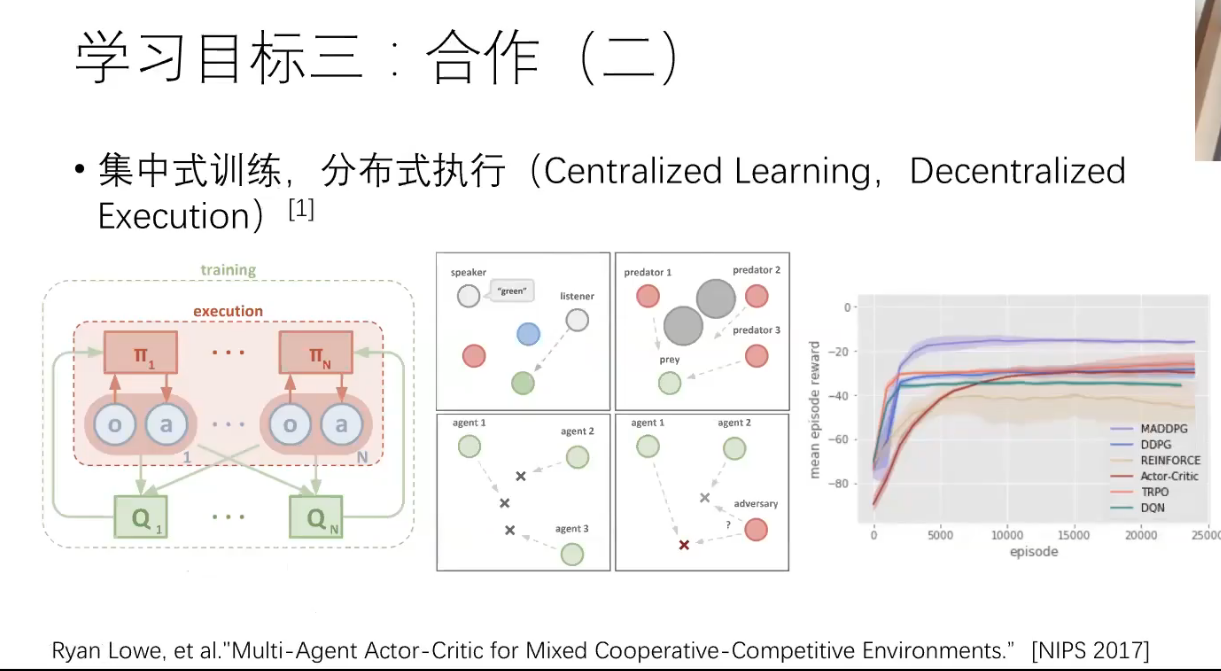
Abstract
mark:3.2. Relative Pessimism and Robust Policy Improvement
Constrained Variational Policy Optimization for Safe Reinforcement Learning
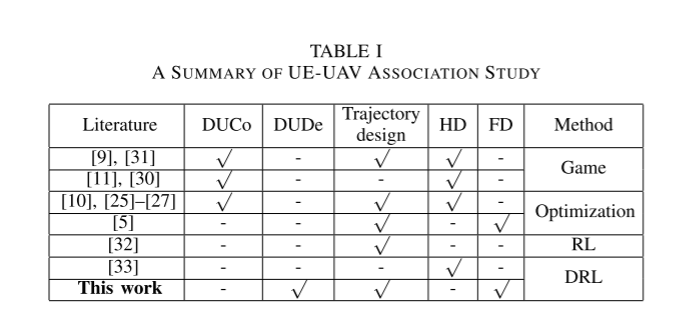
Multi-Agent Deep Reinforcement Learning for Joint Decoupled User Association and Trajectory Design
in Full-Duplex Multi-UAV Networks
downlink (DL) uplink (UL) multi-UAV networks user equipment(UE) DL-UL decoupling(DUDe) robust partially observable Markov decision process
(robust POMDP) model full-duplex (FD)
communication macro base station (MBS)
Network Model and BSs Deployment
Channel Model
Reinforcement Learning, Fast and Slow[Review ]
分析了RL采样效率低的两个原因:
incremental parameter adjustment
一般学习率低下,是采样效率低的第一个原因,如果单存的增大梯度很容易造成对学习策略的过程造成灾难性的干扰
weak inductive biasexplain
神经网络具有弱归纳偏置,导致假设空间很大,这是RL采样效率低下的另一个原因。
对应上述问题,本文给出两个解决方案
- Episodic Deep RL: Fast Learning through Episodic Memory
- Meta-RL: Speeding up Deep RL by Learning to Learn
最后
这两个方法的结合——Episodic Meta-RL。
总结:
学习一开始的冷启动总是很慢的,两个方案相同点都是利用过去经验,然后由慢而快,也就是说快速学习需要建立在缓慢学习的基础上。
Q&A
what is Pessimistic method in RL?
In reinforcement learning, the pessimistic method is an algorithm that learns the worst-case value of each state or action, rather than the expected value. This approach can be useful in situations where the consequences of making a mistake can be very severe, and it is important to be conservative in decision-making.
One way to implement the pessimistic method is to use a modified version of the Bellman equation, which is used to compute the value of each state or action in a Markov decision process. In the pessimistic version of the equation, the minimum value of the next state or action is used, rather than the expected value. This leads the algorithm to prefer actions that minimize the worst-case outcome, rather than actions that maximize the expected reward.
The pessimistic method can be contrasted with the optimistic method, which learns the best-case value of each state or action, and the average method, which learns the expected value. Each of these approaches has its own strengths and weaknesses, and which one is best will depend on the specific problem being solved and the goals of the decision-maker.
what is OOD Action?
Out-of-Distribution (OOD) action in reinforcement learning (RL) refers to actions that the agent may take that are not part of the training distribution of actions. These actions can occur when the agent is operating in a different environment or context than it was trained on, or when the agent is asked to perform a task that it has not seen before. OOD actions can be challenging for an RL agent to handle, as they may not be well-suited to the current task or may lead to unexpected outcomes. One way to mitigate the risk of OOD actions is to train the RL agent on a diverse set of tasks and environments, so that it has a greater range of experience to draw upon when making decisions.
what is discounted state-action occupancy?
Discounted state-action occupancy refers to a measure of the frequency with which an agent or a system visits a particular state-action pair in a Markov decision process (MDP). The discount factor, denoted by γ, determines the weight of future rewards in the total expected reward. It allows the agent to prioritize short-term rewards over long-term rewards, or vice versa, depending on the value of γ. The discounted state-action occupancy is often used in reinforcement learning, a subfield of machine learning, to evaluate the quality of an agent’s policy and to compare different policies. It can also be used in planning and control to determine the optimal policy for an MDP.
downlink和uplink是什么意思?
Downlink和Uplink是无线通信中的术语。
Downlink通常指的是从基站或卫星等地面设备向用户设备发送数据的通信链路。在移动通信领域,downlink指的是从电信网络向移动设备发送数据,例如在接收短信、接听电话或接收互联网数据时使用。
Uplink通常指的是从用户设备向基站或卫星等地面设备发送数据的通信链路。在移动通信领域,uplink指的是从移动设备向电信网络发送数据,例如在发送短信、拨打电话或上传互联网数据时使用。
总的来说,Downlink和Uplink是指无线通信过程中数据传输的方向,Downlink是从基站到设备,Uplink是从设备到基站。
Downlink和Uplink在无线通信系统中是指从基站到用户设备的信号传输(下行)和从用户设备到基站的信号传输(上行)。
这两个方向的信号传输是耦合在一起的,因为它们都需要在同一个频率和时间资源上传输。在无线通信系统中,频谱资源是有限的,因此需要对下行和上行的信号进行协调和管理,以避免信号冲突和干扰。因此,下行和上行之间需要进行时间和频率的协调,以确保它们不会相互干扰。
此外,下行和上行之间也需要进行信号控制和协调,以确保它们能够在同一时间内传输,并在传输时避免相互干扰。这需要在通信系统中进行复杂的协议和协调,以确保下行和上行能够同时进行,而不会相互干扰。
因此,Downlink和Uplink是耦合在一起的,需要协调和管理它们之间的频率、时间和信号控制,以确保它们能够同时进行,并在传输时避免相互干扰。
虽然在某些特定的场景下,可以采用一些技术手段来实现Downlink和Uplink的分离,但这通常需要更多的频谱资源和更复杂的信号处理技术。
例如,在一些多天线系统中,可以采用空分复用技术(Space Division Multiple Access,SDMA),将Downlink和Uplink的信号通过不同的天线进行传输,从而实现Downlink和Uplink的空间分离。但是,这种方法需要更多的天线和更复杂的信号处理技术,因此在实际应用中比较少见。
因此,虽然Downlink和Uplink在理论上可以分离,但在实际无线通信系统中,它们是紧密耦合在一起的,并需要进行复杂的协调和管理,以确保它们能够同时进行,并在传输时避免相互干扰。
在无人机作为基站的情况下,Downlink和Uplink的耦合问题与传统基站的情况有所不同,因为无人机作为基站的移动性更强,需要解决更多的技术难题。
一种解决Downlink和Uplink耦合问题的方法是使用分时多址(Time Division Multiple Access,TDMA)或频分多址(Frequency Division Multiple Access,FDMA)技术。通过将Downlink和Uplink的时间或频率分隔开,使其在不同的时间或频率上进行传输,从而避免信号冲突和干扰。这种方法需要在无人机和移动设备上分别实现时钟同步和频率同步,以确保Downlink和Uplink能够正确地在不同的时间或频率上进行传输。
另一种解决Downlink和Uplink耦合问题的方法是使用空分复用(Space Division Multiple Access,SDMA)技术。在这种技术中,无人机基站可以使用多个天线同时向多个移动设备进行Downlink传输,同时通过智能信号处理技术对不同的移动设备的信号进行分离,从而实现Downlink和Uplink的空间分离。
除了上述方法之外,还可以采用其他技术手段来解决Downlink和Uplink耦合的问题,例如采用OFDMA技术,通过动态分配子载波资源,将Downlink和Uplink在频域上分离。但是,这些方法都需要在无人机和移动设备上进行复杂的信号处理和协议设计,实现起来比较复杂。
NLoS and LoS
NLoS和LoS是无线通信中的两个术语,用来描述信号的发射器和接收器之间的路径。
LoS是 “视线 “的意思,指的是发射器和接收器之间的直接、无障碍的路径。这意味着没有任何物理障碍,如建筑物、山丘或树木,阻挡信号。在LoS方案中,信号通过空气传播,在几乎没有干扰的情况下被接收器接收。LoS是无线通信的理想场景,因为它提供最好的信号质量、最高的数据速率和最低的延迟。
另一方面,NLoS是 “非视线 “的意思。在这种情况下,信号路径受到物理障碍物的阻挡,如建筑物、山丘或树木,这些障碍物会导致信号反弹、散射或衍射。因此,信号强度会降低,信号质量也会下降。与LoS通信相比,NLoS通信可能导致更高的错误率,更低的数据率和更高的延迟。
在无线通信中,考虑信号是通过LoS还是NLS路径是很重要的,因为它可以影响信号质量,并最终影响系统的性能。诸如信号处理、天线设计和频率选择等技术可用于减轻NLS传播的影响并提高无线系统的性能。
the backhaul rate of UAV
无人机(UAV)的回程率是指无人机和地面控制站之间的通信链路的数据传输率。它是数据可以从无人机发送到地面控制站的速率,反之亦然。
无人机的回程速率取决于几个因素,包括使用的通信技术、传输距离、使用的频段和可用带宽。一般来说,使用的频段越高,可用带宽越宽,可以实现的回程率就越高。
在实践中,无人机的回程率会因具体实施和环境因素的不同而有很大差异。例如,在无线电频率干扰水平较低的农村地区运行的无人机可能比在干扰水平较高的城市地区运行的无人机能够实现更高的回程率。
总的来说,无人机的回程率是无人机设计和运行中的一个重要考虑因素,包括监视、测绘和包裹运送等一系列应用。
传输速率和回程速率什么关系
传输速率和回程速率是通信中的两个概念,它们通常指代的是在一个通信链路中的数据传输速度。传输速率通常指从源端到目的端的数据传输速度,而回程速率则指从目的端返回到源端的数据传输速度。
传输速率和回程速率是相互关联的,因为它们都是同一个通信链路中的数据传输速度的不同方面。在一个通信链路中,传输速率和回程速率可能会不同,这取决于许多因素,例如链路的物理特性、使用的通信技术、信号传输距离、信道质量和网络拥塞情况等。在实践中,传输速率和回程速率通常都受到网络拥塞、信噪比、干扰和信号衰减等因素的影响。
如果传输速率和回程速率不平衡,会导致通信延迟和数据传输速度下降。因此,在设计和部署通信网络时,需要平衡传输速率和回程速率,并采取措施来确保它们的稳定性和可靠性,以实现高效的数据传输和通信服务。
什么是in-band full- duplex communication?
In-band full-duplex communication是一种数据通信的方式,它允许在同一频段或信道上进行双向通信。在这种通信方式中,数据的发送和接收是同时进行的,不需要像半双工通信那样进行轮流传输。这意味着两个通信端口可以同时发送和接收数据,而不会相互干扰。
在传统的通信方式中,半双工通信和全双工通信是最常见的。半双工通信只允许数据在一个方向上传输,而全双工通信可以在两个方向上传输数据,但需要不同的频段或信道。而in-band full-duplex communication允许在同一频段或信道上进行双向通信,大大提高了通信效率和频谱利用率。
这种通信方式在无线电通信、计算机网络和其他领域都有广泛应用,比如使用WiFi进行视频通话,使用蓝牙进行音频传输等。
什么是evolutionary game?
进化博弈(Evolutionary Game)是一种研究生物种群在进化过程中如何通过博弈(Game)策略来获得生存和繁衍优势的数学模型。
在进化博弈模型中,生物个体的策略是基于其基因和环境的组合,而这些策略在个体之间通过博弈进行相互竞争。每个个体都有一个收益函数,用于度量其获得生存和繁殖成功的能力。这些收益函数随着时间而变化,因为它们取决于种群中的策略分布。
在进化博弈模型中,个体可以采用不同的策略,例如“合作”和“背叛”。合作的策略可能导致双方都获得收益,而背叛的策略可能会导致其中一方获得更多收益,另一方则获得较少或者没有收益。在博弈的每一轮中,个体之间相互竞争并且根据收益函数来获得收益。然后,种群中的个体按照它们的收益水平进行繁殖,使得获得高收益的个体在下一代中更为普遍。
进化博弈模型可以用来研究各种生物现象,例如动物中的群体行为,植物的竞争行为以及人类社会中的协作和竞争行为。这种模型已经得到了广泛的应用,并且在理论生物学、社会学、经济学和计算机科学等领域中有着重要的意义。
什么是5G HetNet?
5G HetNet(异构网络)是指使用多种类型的无线接入技术的网络架构,如蜂窝网络、Wi-Fi和小型蜂窝,为用户提供无缝连接和高数据速率。
在5G HetNet中,不同类型的接入节点以一种协调的方式部署,以提高覆盖范围、容量和网络性能。例如,宏蜂窝用于提供广域覆盖,而小蜂窝,如微蜂窝、皮米蜂窝和飞蜂窝,则用于提高密集城市地区、室内环境和农村地区的覆盖和容量。
在5G HetNet中使用不同类型的接入节点需要先进的网络管理技术,如网络切片、动态频谱分配和不同节点之间的协调。这些技术能够有效地利用网络资源,提高服务质量,并改善用户体验。
5G HetNet有可能彻底改变我们使用和体验无线通信的方式,为各种设备和应用提供高速、低延迟的连接。
什么是wireless backhaul links?
无线回程链路是指用于连接基站、接入点或其他网络节点与核心网络或互联网的无线连接。这些链路是通信基础设施的重要组成部分,因为它们为数据流量在终端用户设备和核心网络之间流动提供了必要的带宽和连接。
在无线回程链路中,数据通过无线电波或其他无线技术(如微波或毫米波频段)进行空中传输。这些链接可用于连接远程站点,将覆盖范围扩大到有线回程不可行或不具成本效益的地区,并为事件或紧急情况提供临时连接。
无线回程链路可以在各种频率下运行,从在6GHz以下频段运行的低带宽、长距离链路到在毫米波频段运行的高带宽、短距离链路。频率和技术的选择取决于诸如距离、带宽要求、视线、干扰和成本等因素。
随着5G网络的部署,无线回程链路变得越来越重要,5G网络需要高速、低延迟的连接和大容量的回程链路,以支持对数据密集型应用和服务日益增长的需求。
什么是Robust POMDP?
Robust POMDP是一种偏重于鲁棒性(robustness)的部分可观测马尔可夫决策过程(POMDP)。
POMDP是一种经典的强化学习问题,其基本思想是在不完全观察到环境状态的情况下,代理需要在一组可能的动作和状态之间进行决策,以最大化长期奖励。
然而,由于POMDP通常涉及对环境状态的不完全观察,因此存在一定的风险和不确定性,可能导致代理所做出的决策并不是最佳的或者不可行。因此,研究者们提出了许多方法来提高POMDP的鲁棒性,以降低不确定性和风险。
Robust POMDP是其中之一,它特别关注于如何在不完全观察到环境状态的情况下,通过设计鲁棒的策略来最大化长期奖励,并尽可能地避免由于不确定性和风险带来的负面影响。通常,Robust POMDP使用了不同的方法来处理不确定性,如鲁棒优化(robust optimization)、置信度上限(upper confidence bounds)等。
the UAV backhaul capacity is overloaded
When the UAV backhaul capacity is overloaded, it means that the unmanned aerial vehicle (UAV) is experiencing a bottleneck in the transmission of data from the UAV to the ground station or other remote locations. This can occur when the amount of data being generated by the UAV exceeds the capacity of the wireless communication link that connects the UAV to the ground station.
To resolve this issue, several approaches can be taken:
- Increase the backhaul capacity: One solution is to increase the capacity of the backhaul link. This can be achieved by using higher bandwidth wireless communication links or using multiple links to create a mesh network. However, increasing the capacity may come at the cost of increased power consumption, weight, and complexity of the UAV.
- Prioritize data: Another solution is to prioritize the data being transmitted. Not all data generated by the UAV may be equally important, so prioritizing the critical data can help to reduce the amount of data being transmitted and ease the burden on the backhaul link.
- Compression: Compressing the data before transmitting it can also help to reduce the amount of data being transmitted, which can help to reduce the load on the backhaul link.
- Adjust the mission: It is also possible to adjust the mission of the UAV to reduce the amount of data being generated. This can be achieved by changing the flight path or using different sensors that generate less data.
Overall, the solution will depend on the specific use case and the nature of the data being generated by the UAV.
difference between uplink,downlink and backhaul capacities of UAV
UAV (Unmanned Aerial Vehicles) are often equipped with communication equipment to establish connectivity with ground stations, satellites or other aerial vehicles. The communication capacity of a UAV can be divided into three parts:
- Uplink capacity: The uplink capacity refers to the data transmission capacity from the ground station or other sources to the UAV. This includes the command and control signals, sensor data, video feeds or any other type of data that needs to be transmitted from the ground to the UAV. The uplink capacity is typically lower than the downlink capacity due to the limitations of the UAV’s communication equipment.
- Downlink capacity: The downlink capacity refers to the data transmission capacity from the UAV to the ground station or other destinations. This includes video feeds, sensor data, telemetry information, and any other type of data that needs to be transmitted from the UAV to the ground. The downlink capacity is typically higher than the uplink capacity to ensure that the ground station can receive all the necessary data from the UAV.
- Backhaul capacity: The backhaul capacity refers to the data transmission capacity between the UAV and other communication nodes, such as satellites or other UAVs. This capacity is required for long-range communication and to extend the coverage area of the UAV. The backhaul capacity is typically higher than the uplink and downlink capacities, as it needs to support communication over longer distances.
The specific uplink, downlink, and backhaul capacities of a UAV depend on several factors, including the communication equipment used, the frequency bands employed, and the communication protocols employed. Generally, the higher the communication capacity, the more data can be transmitted, resulting in a more capable and effective UAV communication system.
为什么在论文中,概率用Pr()来表示?
在论文中,概率通常使用Pr()来表示,这是因为Pr()是probability(概率)的缩写,它是英文单词probability的第一个和最后一个字母的缩写形式。使用Pr()可以使概率符号简短、明了,方便阅读和书写。
另外,使用Pr()也有助于避免与其他符号产生混淆,例如使用小写字母p表示概率,容易与其他符号如p-value(p值)产生歧义。因此,在数学和统计学领域中,Pr()已成为一种通用的表示概率的方法。
什么是渐近分布
渐近分布是指随着样本量的增加,概率分布逐渐趋近于某个极限分布的现象。换句话说,随着样本数量的增加,随机变量的概率分布逐渐稳定并逼近于一个确定的分布。
例如,假设一个随机变量的样本平均值是一个正态分布。当样本量逐渐增加时,这个分布将逐渐趋近于一个确定的正态分布,这个确定的正态分布就是这个随机变量的渐近分布。
渐近分布在统计学中非常重要,因为它可以用来描述一些随机变量在样本量很大时的行为,并且在实际应用中通常需要估计渐近分布来做出一些决策。
Robust POMDP 和 POMDP区别是什么
POMDP(部分可观测马尔可夫决策过程)是一个用于描述不确定性下决策问题的数学框架。在POMDP中,决策制定者面临的环境具有部分可观测性,即决策制定者不能直接观察到环境的完整状态,而只能通过观察到的一些部分信息进行推断。Robust POMDP(鲁棒POMDP)是POMDP的一种扩展形式,用于处理环境模型不确定性和参数不确定性的情况。
区别如下:
- 鲁棒POMDP与POMDP的主要区别在于模型不确定性和参数不确定性的处理方式。鲁棒POMDP旨在处理不确定性模型,即我们不知道环境模型是什么。它使用集合值函数表示模型不确定性,并在决策制定时考虑多种可能的环境模型。而POMDP假设我们已经知道环境的动态模型,并根据已知的环境模型进行决策制定。
- 鲁棒POMDP中的决策制定者需要考虑多种可能的环境模型,以便在不确定性环境中做出最优决策。这与POMDP不同,因为POMDP中的决策制定者只需要考虑一个已知的环境模型。
- 在鲁棒POMDP中,策略的性能与环境模型和参数的不确定性密切相关。因此,与POMDP相比,鲁棒POMDP需要更复杂的计算方法和算法来求解最优策略。
- 鲁棒POMDP是POMDP的一个扩展,它可以处理更广泛的不确定性情况。POMDP只能处理部分可观测性问题,而鲁棒POMDP可以处理不确定性模型和参数不确定性问题。
总的来说,鲁棒POMDP是POMDP的一个更广泛的形式,用于处理更复杂的不确定性情况。
扩散模型和GAN可以应用在什么地方,这两个有什么区别呢?
扩散模型和GAN(生成对抗网络)都是机器学习中常用的模型,但应用场景和工作原理有所不同。
扩散模型(Diffusion Models)是一种用于生成样本的概率模型,它的基本思想是对一个样本进行多次采样,每次采样时将当前样本的信息扩散到相邻的样本中。通过多次采样和扩散,扩散模型可以生成高质量的样本,比如图像、语音、文本等。扩散模型在计算机视觉、自然语言处理等领域中得到了广泛应用。
GAN(Generative Adversarial Networks)是一种用于生成样本的神经网络模型,它由两个神经网络组成:生成器(Generator)和判别器(Discriminator)。生成器的作用是生成样本,判别器的作用是判断生成器生成的样本是否真实。通过不断的迭代训练,生成器会逐渐学习到生成真实的样本,判别器也会逐渐学习到判别真实和虚假的样本。GAN 在图像生成、语音合成等领域中得到了广泛应用。
两者的主要区别在于工作原理和应用场景。扩散模型是一种基于概率的模型,它的基本思想是对样本进行多次采样和扩散,生成高质量的样本。GAN 则是一种基于神经网络的模型,它通过生成器和判别器相互博弈的方式来生成高质量的样本。因此,扩散模型适用于需要生成大量高质量样本的场景,而 GAN 更适用于需要生成具有多样性的样本的场景。
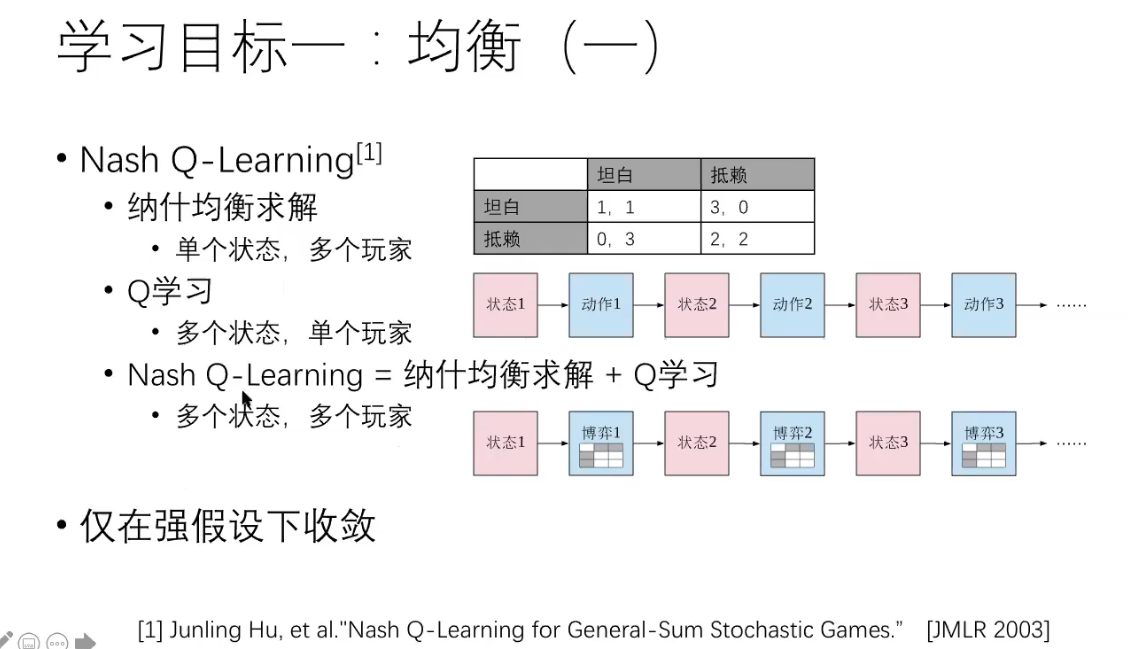
马尔科夫博弈
马尔科夫博弈(Markov game)是一种多人博弈模型,它结合了马尔科夫过程和博弈论。在马尔科夫博弈中,多个参与者以随机的方式采取决策,这些决策的结果不仅取决于当前的状态,还取决于上一个状态和之前采取的行动。马尔科夫博弈是一种比博弈论更为复杂的博弈模型,它可以用于模拟一些现实世界中的问题,例如机器人控制、多智能体系统的协调等。
马尔科夫博弈具有以下特点:
- 参与者采取行动的结果取决于当前的状态和上一个状态以及之前的行动;
- 参与者的行动具有随机性,即它们可以采取不同的行动,并且每个行动有一定的概率实现;
- 参与者的目标是最大化自己的收益或者最小化自己的成本。
在马尔科夫博弈中,通常采用强化学习算法来学习参与者的最佳策略。强化学习算法利用当前的状态和行动信息来更新策略,使得参与者能够逐渐学习到最优的行动策略。
强化学习中的Credit Assignment是什么?请问Credit Assignment解决了什么呢?为什么被提出
强化学习中的Credit Assignment(信用分配)是指在一个智能体完成一个任务时,对于获得的奖励(reward)或惩罚(penalty)的分配方式。在强化学习中,一个智能体与环境进行交互,并根据环境的反馈(奖励或惩罚)来更新其策略以优化其行为。然而,这些奖励或惩罚通常是在时间序列中被分配的,这使得决定每个行动对应的奖励或惩罚变得复杂。
因此,Credit Assignment可以看作是一个问题:如何将智能体的行为与获得的奖励或惩罚联系起来。这个问题的解决方式有很多,包括基于价值函数的Credit Assignment、基于Temporal-Difference(TD)方法的Credit Assignment以及基于Actor-Critic框架的Credit Assignment等。这些方法可以帮助智能体更好地理解哪些行动是对任务有帮助的,并对其进行加强或弱化,从而改进其策略。
Credit Assignment解决了强化学习中的一些重要问题。
首先,强化学习的目标是通过最大化期望累积回报来寻找最优策略。然而,这个过程是一个序列决策问题,即当前的决策会影响未来的奖励,而未来的奖励又反过来影响当前的决策。这个问题被称为Credit Assignment问题,因为它需要将奖励或惩罚与先前的行为联系起来,以决定哪些行为应该受到奖励或惩罚。
其次,Credit Assignment问题也是因为强化学习通常涉及到长时间的延迟奖励。即智能体的某个行为可能会导致在未来的某个时间点获得奖励,而这个时间点可能会很长。这就使得Credit Assignment变得非常困难,因为要确定哪些行为导致了未来的奖励或惩罚需要考虑许多因素,如环境的变化、智能体的行为选择等。
因此,Credit Assignment的提出旨在解决强化学习中的信用分配问题,从而提高智能体的决策质量和性能。Credit Assignment可以帮助智能体更好地理解哪些行为是有用的,哪些行为是无用的,并针对性地对行为进行加强或弱化,从而提高其策略的质量和效果。
bias-variance tradeoff
Bias:模型预测值跟训练集的真实值之间的差异。一般可以理解为在训练集上的表现,表现很好,那就是bias很小,表现很差,那就是bias很大。
Variance:模型预测值跟总体之间的差异,一般可以理解为训练集和验证集模型评价指标的差异,比如在训练集上模型表现很好,但是在验证集上表现很差,说明样本发生比较小的变化,预测值会发生比较大的变化,也就是方差比较大。
帮助记忆的小tip:小的方差&大的误差 —> 欠拟合,大的方差&小的误差 —> 过拟合
Bias-variance trade-off:
理想的情况下,我们想要我们的模型低bias和低的variance,然而,实际工作中,这个是非常难的,所以trade-off可以帮助我们选择合适的模型。
简单的模型像线性回归和逻辑回归,通常具有较高的bias和较低的variance,复杂的模型,比如随机森林,会有低的bias和高的variance。
how can we understand “A learning procedure with weak inductive bias will be able to master a wider range of patterns (greater variance), but will in general be less sample-efficient”
In machine learning, the inductive bias of a learning procedure refers to the assumptions or prior knowledge that the algorithm uses to make predictions based on the data it is given. A strong inductive bias means that the algorithm has a lot of prior assumptions about the types of patterns that are likely to be present in the data, whereas a weak inductive bias means that the algorithm has fewer prior assumptions.
When a learning procedure has a weak inductive bias, it is more flexible in the types of patterns it can recognize in the data. This means that it is able to master a wider range of patterns, which gives it greater variance in the types of tasks it can perform. However, because the algorithm has fewer prior assumptions, it may require more data to learn from in order to accurately recognize the patterns in the data. This makes it less sample-efficient, meaning that it needs more training examples to achieve the same level of accuracy as an algorithm with a stronger inductive bias.
On the other hand, a learning procedure with a strong inductive bias will be more specialized in the types of patterns it can recognize, which can make it more sample-efficient. However, it may not be as effective at recognizing patterns outside of its prior assumptions, which limits its ability to generalize to new and unseen data.
In summary, a learning procedure with a weak inductive bias has greater variance and can recognize a wider range of patterns, but may require more training examples to achieve the same level of accuracy as an algorithm with a stronger inductive bias.
怎样理解 weak inductive bias
在机器学习中,归纳偏差(inductive bias)是指算法对数据的先验假设或先验知识,这些先验假设可以影响算法对数据的解释和预测。假设归纳偏差越强,算法就越倾向于使用更特定的假设和更少的参数来解释和预测数据。相反,如果归纳偏差较弱,算法就会更倾向于使用更通用的假设和更多的参数,以尝试解释和预测更广泛的数据。
因此,弱归纳偏差的算法通常更加灵活,能够更好地适应不同类型的数据,但在学习新的数据时可能需要更多的训练示例。这是因为算法没有太多的先验知识可以利用,需要通过大量的训练示例来适应新的数据。相反,强归纳偏差的算法通常更加专业化,只适用于特定类型的数据,但可能会更加高效,因为它们可以从较少的训练示例中学习并达到较高的准确度。
因此,“weak inductive bias”可以理解为算法在学习数据时使用的先验假设比较少,对不同类型的数据具有更强的适应性和灵活性,但可能需要更多的训练数据来学习。
wiki:
归纳偏置(英语:Inductive bias),指的是学习算法中,当学习器去预测其未遇到过的输入结果时,所做的一些假设的集合(Mitchell, 1980)。
机器学习试图去建造一个可以学习的算法,用来预测某个目标的结果。要达到此目的,要给于学习算法一些训练样本,样本说明输入与输出之间的预期关系。然后假设学习器在预测中逼近正确的结果,其中包括在训练中未出现的样本。既然未知状况可以是任意的结果,若没有其它额外的假设,这任务就无法解决。这种关于目标函数的必要假设就称为归纳偏置(Mitchell, 1980; desJardins and Gordon, 1995)。
一个典型的归纳偏置例子是奥卡姆剃刀,它假设最简单而又一致的假设是最佳的。这里的一致是指学习器的假设会对所有样本产生正确的结果。
归纳偏置比较正式的定义是基于数学上的逻辑。这里,归纳偏置是一个与训练样本一起的逻辑式子,其逻辑上会蕴涵学习器所产生的假设。然而在实际应用中,这种严谨形式常常无法适用。在有些情况下,学习器的归纳偏置可能只是一个很粗糙的描述(如在人工神经网络中),甚至更加简单。
之所以对这个概念难以理解, 是因为这个名词太没有烟火气, 其实他就是说的是模型的指导规则, 可以同时应用于训练和预测的时候的东西, 是一种超参数(因为是模型的一部分).上面举的例子是线性回归, 还有一种是决策树, 决策树的假设就是,
- 优先选择较短的树而不是较长的。
- 选择那些信息增益高的属性里根节点较近的树。这里利用了两个假设. 相比之下, 神经网络的假设是相当弱的, 举个例子:分类神经网络模型 : 将输入通过非线性函数进行映射的结果,正确的类别具有较高的softmax值.
归纳偏置的种类
以下是机器学习中常见的归纳偏置列表:
- **最大条件独立性**(conditional independence):如果假说能转成贝叶斯模型架构,则试着使用最大化条件独立性。这是用于朴素贝叶斯分类器(Naive Bayes classifier)的偏置。
- 最小交叉验证误差:当试图在假说中做选择时,挑选那个具有最低交叉验证误差的假说,虽然交叉验证看起来可能无关偏置,但天下没有免费的午餐理论显示交叉验证已是偏置的。
- 最大边界:当要在两个类别间画一道分界线时,试图去最大化边界的宽度。这是用于支持向量机的偏置。这个假设是不同的类别是由宽界线来区分。
- **最小描述长度**(Minimum description length):当构成一个假设时,试图去最小化其假设的描述长度。假设越简单,越可能为真的。见奥卡姆剃刀。
- 最少特征数(Minimum features):除非有充分的证据显示一个特征是有效用的,否则它应当被删除。这是特征选择(feature selection)算法背后所使用的假设。
- 最近邻居:假设在特征空间(feature space)中一小区域内大部分的样本是同属一类。给一个未知类别的样本,猜测它与它最紧接的大部分邻居是同属一类。这是用于最近邻居法的偏置。这个假设是相近的样本应倾向同属于一类别。
奥卡姆剃刀(英语:Ockham’s Razor、拉丁语:Lex Parsimoniae,意为“简约法则”)是由14世纪方济会修士奥卡姆的威廉(William of Occam,约1287年至1347年,英格兰萨里郡奥卡姆 (Ockham)人氏)提出的逻辑学法则。如果关于同一个问题有许多种理论,每一种都能作出同样准确的预言,那么应该挑选其中使用假定最少的。尽管越复杂的方法通常能做出越好的预言,但是在不考虑预言能力(即结果大致相同)的情况下,假设越少越好。
所罗门诺夫的归纳推理理论是奥卡姆剃刀的数学公式化:[1][2][3][4][5][6]在所有能够完美描述已有观测的可计算理论中,较短的可计算理论在估计下一次观测结果的概率时具有较大权重。
假设空间
假设空间(Hypothesis space)是指学习算法可以选择的所有假设的集合。假设空间可以是任何形式的,它取决于算法和问题的性质。通常情况下,假设空间包括一个或多个参数,并且每个假设对应于一组参数的值。
假设空间可以是可行解的集合,但这并不一定是必须的。例如,在一些问题中,假设空间是所有可能的决策树,而决策树并不一定是可行解的集合。另一个例子是神经网络,它的假设空间通常是由许多层次和节点组成的复杂函数空间,其中每个假设都对应于网络中的一组参数。
因此,假设空间并不一定是可行解的集合,它可以是任何形式的,只要它包含算法可以选择的所有假设即可。
假设的意思:
在我的回答中,我解释了假设空间是指学习算法可以选择的所有假设的集合,它可以是任何形式的,取决于算法和问题的性质。我还提到了一些例子来说明假设空间的不同形式。
我的回答中提到的”假设”指的是在学习算法中,模型对输入数据的输出的预测,也就是假设或者猜测的结果。在机器学习中,我们使用许多不同的模型或算法来拟合训练数据,这些模型或算法可以生成许多不同的假设,从而形成假设空间。
因此,我的回答中的“假设”指的是学习算法中的假设或预测结果,而不是指某个具体的问题或数据集中的假设或解。
可以理解为模型输出的解:
的,你理解得很对。在机器学习中,假设通常是指模型对输入数据的输出的预测或猜测,也可以称之为模型的预测或输出。在训练过程中,学习算法将许多假设或模型应用于训练数据,并尝试找到最适合数据的模型或假设。在测试或使用模型进行预测时,模型将使用其假设或模型输出对输入数据进行预测或解释。因此,假设可以被视为模型输出的解释或解。
什么是表征?什么是内部表征?
在计算机科学中,表征(Representation)指的是一种将信息映射到某种形式的方式,以便于计算机程序进行处理和分析。在人工智能和机器学习中,表征通常用于描述数据的特征,以便于进行分类、聚类、预测等任务。
内部表征(Internal Representation)是指在计算机或人工智能系统中,数据被转换成为某种内部表示形式,以便于程序进行处理和分析。这种转换通常发生在输入数据被送入到神经网络等机器学习模型中时。内部表征可以是数字、向量或矩阵等形式,通常被认为是一种高度优化的、计算机友好的形式,以便于进行各种算法和运算。内部表征的选择对机器学习的性能和效率都具有重要的影响。
Episodic Deep RL目前还流行吗
Episodic Deep RL(Episodic Deep Reinforcement Learning)是一种深度强化学习算法,旨在解决连续任务的学习问题。它在过去几年中一直是深度强化学习领域的研究热点之一。但是,目前是否仍然流行取决于不同的应用场景和问题。
在某些特定的连续控制任务中,Episodic Deep RL仍然是一个有效的解决方案,因为它能够学习从过去的经验中汲取有用的信息,并利用这些信息优化策略。此外,一些最新的研究表明,在某些复杂的任务中,Episodic Deep RL仍然是一个有前途的方向,有望解决现有深度强化学习算法存在的一些问题,比如学习效率和泛化性能等。
总之,Episodic Deep RL目前仍然是深度强化学习领域的研究热点之一,但其是否适用于特定的应用场景和问题需要具体分析。
Episodic Deep RL在哪些算法中有应用?
Episodic Deep RL已经在许多深度强化学习算法中得到了应用,包括:
- Hindsight Experience Replay (HER):HER是一种通过将当前状态重置为目标状态并使用当前策略从新状态开始进行训练的技术,以解决稀疏奖励问题。Episodic Deep RL被用于HER算法的设计中,使其能够更好地处理这种类型的问题。
- Soft Actor-Critic (SAC):SAC是一种用于连续动作控制的深度强化学习算法。Episodic Deep RL被用于SAC算法的设计中,使其能够从过去的经验中汲取有用的信息,并利用这些信息优化策略。
- Trust Region Policy Optimization (TRPO):TRPO是一种基于策略梯度的深度强化学习算法,它使用了一个局部的目标优化器来改进策略的学习。Episodic Deep RL被用于TRPO算法的设计中,以解决连续任务的学习问题。
- Deep Deterministic Policy Gradient (DDPG):DDPG是一种用于连续动作控制的深度强化学习算法。Episodic Deep RL被用于DDPG算法的设计中,以帮助解决这种类型的问题。
总之,Episodic Deep RL已经在许多深度强化学习算法中得到了广泛的应用,并在解决连续任务学习问题方面取得了一定的进展。
什么是TV-divergence?和KL divergence的区别和联系?
TV(Total Variation)散度是一个用于衡量两个概率分布之间差异的度量,常用于图像处理、计算机视觉、机器学习等领域。
给定两个概率密度函数P和Q,TV散度定义为它们在每个点上差的绝对值的积分的总和。数学上,TV散度可以表示为:
$TV(P,Q) = 1/2 * ∫|P(x) - Q(x)| dx$
其中,$|P(x) - Q(x)|$表示在点x处P和Q之间的差异,积分是对所有可能的点x求和。TV散度衡量的是概率分布P和Q之间的距离,它的值越大,表示它们之间的差异越大,反之则表示它们越相似。
KL(Kullback-Leibler)散度和TV(Total Variation)散度都是用于衡量两个概率分布之间的差异的度量,但它们有不同的性质和用途。
KL散度也被称为相对熵,它是用于衡量两个概率分布之间的差异的一种度量方式。KL散度的值越小,表示两个概率分布越相似,越大则表示它们之间的差异越大。KL散度的数学表达式如下:
$KL(P||Q) = ∫P(x)log(P(x)/Q(x))dx$
其中,P和Q分别是两个概率分布,log是自然对数。KL散度的值可以是无限大,且不对称,即$KL(P||Q) ≠ KL(Q||P)$。KL散度通常用于衡量模型预测结果和真实结果之间的差异,以及在信息检索、分类、聚类等领域中的应用。
相比之下,TV散度是一种更直观的距离度量,它的值永远不会是无限大,且是对称的。在图像处理、计算机视觉等领域中,TV散度通常用于图像去噪、图像分割等问题中。
虽然KL散度和TV散度是两种不同的度量方式,但它们之间有一定的联系。事实上,当两个概率分布的TV散度很小时,它们之间的KL散度也会比较小,但反过来并不成立。因此,在某些应用中,可以同时使用KL散度和TV散度来综合考虑两个概率分布之间的差异。
what is dual gradient descent in safey reinforcement learning?
Dual gradient descent is a technique used in safe reinforcement learning to optimize a policy while ensuring that certain safety constraints are satisfied.
In traditional reinforcement learning, the goal is to maximize a reward function by updating the policy parameters in the direction of the gradient of the expected reward. However, in safe reinforcement learning, there may be constraints that need to be satisfied in addition to maximizing the reward.
The dual gradient descent algorithm works by simultaneously optimizing the policy parameters and a set of Lagrange multipliers associated with the safety constraints. The Lagrange multipliers are used to enforce the constraints and are updated in the direction of the gradient of a cost function that penalizes violations of the constraints.
The policy parameters are updated in the direction of the gradient of the expected reward, but with an additional term that is proportional to the Lagrange multipliers and the gradient of the constraint functions. This term ensures that the policy parameters are updated in a way that satisfies the constraints.
By using dual gradient descent, the policy can be optimized to maximize the reward while satisfying the safety constraints, which is important in applications where safety is a critical concern.
Here is the formulation of the dual gradient descent algorithm in safe reinforcement learning:
Suppose we have a policy parameterized by $\theta$, and we want to maximize the expected reward $J(\theta)$ subject to some safety constraints $g_i(\theta) \leq 0$ for $i=1,\ldots,m$. We introduce Lagrange multipliers $\lambda_i \geq 0$ for each constraint and define the Lagrangian:
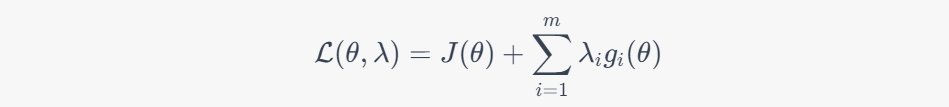
The dual gradient descent algorithm updates the policy parameters and Lagrange multipliers iteratively as follows:
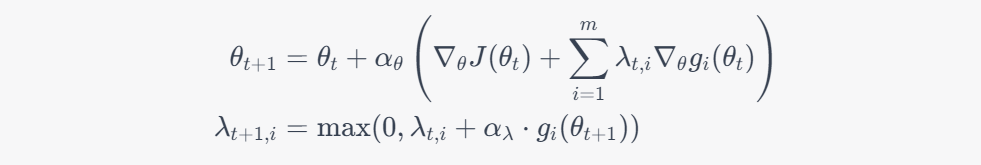
where $\alpha_\theta$ and $\alpha_\lambda$ are step sizes. The update for $\theta$ is the standard policy gradient update, but with an additional term that takes into account the Lagrange multipliers and the gradients of the constraint functions. The update for $\lambda$ is a projection update that ensures that the Lagrange multipliers remain non-negative.
By updating both the policy parameters and the Lagrange multipliers simultaneously, dual gradient descent can find a policy that maximizes the expected reward while satisfying the safety constraints.
let me provide some more details about each step of the dual gradient descent algorithm:
Initialize policy parameters and Lagrange multipliers: We start by initializing the policy parameters $\theta$ and Lagrange multipliers $\lambda$ to some initial values.
Evaluate policy: We use the current policy to interact with the environment and collect a set of trajectories. From these trajectories, we compute the expected reward $J(\theta)$ and the constraint violations $g_i(\theta)$.
Update Lagrange multipliers: We update the Lagrange multipliers using a projection update:
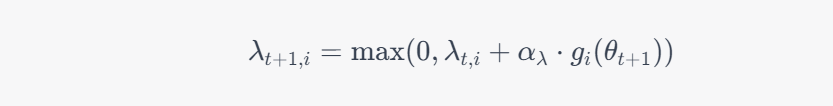
This update ensures that the Lagrange multipliers remain non-negative.
Update policy parameters: We update the policy parameters using the policy gradient method, but with an additional term that takes into account the Lagrange multipliers and the gradients of the constraint functions:
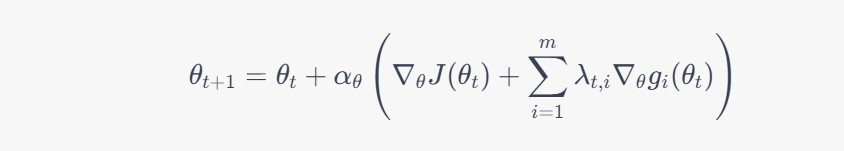
This update ensures that the policy parameters are updated in a way that satisfies the safety constraints.
Repeat: We repeat steps 2-4 until some stopping criterion is met, such as a maximum number of iterations or convergence of the policy.
By using dual gradient descent, we can optimize the policy to maximize the expected reward while satisfying the safety constraints, which is important in applications where safety is a critical concern.

